
Dec 09, 2020
Dec 09, 2020
Join the IPU conversation
Join our Graphcore community for free. Get help and share knowledge, find tutorials and tools that will help you grow.
Join on SlackWe’re sharing a raft of new performance results for our MK2 IPU-based machine intelligence systems today. You’ll see our IPU-M2000 system significantly outperforms the Nvidia A100 DGX across the board, with orders of magnitude performance improvements for some models.
Graphcore customers are already making big leaps forward with our second generation IPU systems – whether they prioritise faster time to result, model accuracy, better efficiency, lower TCO (Total Cost of Ownership) or the chance to make new breakthroughs in AI with the IPU.
We’ve chosen a range of the most popular models our customers frequently turn to as proxies for their proprietary production AI workloads in natural language processing, computer vision and more, both in training and inference.
We are also delighted to share results in this blog using our new PyTorch framework support. We are continuing to develop and expand this capability – you can find out more in our blog here.
The results are measured on IPU-M2000 & IPU-POD64 platforms. Wherever possible, we compare IPU performance against performance numbers published by NVIDIA for the A100 GPU as part of the DGX A100 platform. It’s notoriously hard to find an exact apples-to-apples comparison for very different products and chip architectures, so we compare against the closest platform in terms of price and power. Where NVIDIA has not published results for a particular model, measured results are used.
Code for all of our benchmarks is available from the examples repo on the Graphcore GitHub site where you can also find code for many other model types and application examples.
We’ve included notes for each chart to explain our methodology and to provide additional information about batch sizes, data sets, floating point arithmetic, frameworks etc. In addition to publishing our benchmarking charts in this blog and on our website, we are also publishing performance data in tabular format for IPU-M2000 and IPU-POD systems on our website. We’ll add more and update the results regularly.
Finally, we’ve also joined MLCommons, the governing body for the independent benchmarking organisation, MLPerf. We will be participating in MLPerf in 2021 – starting with the first training submission in the Spring – as well as continuing to build out our own performance results.
Natural Language Processing (NLP)
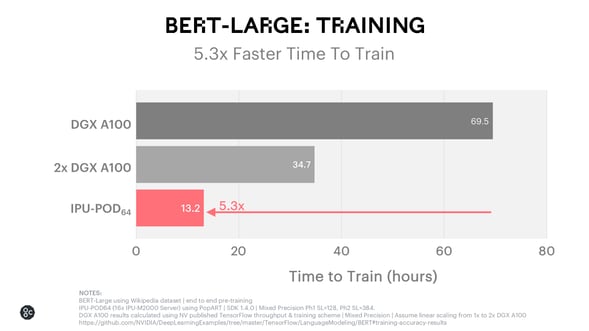
BERT-Large Training
BERT-Large (Bidirectional Encoder Representations from Transformers) is established as one of the most widely used models for NLP.
The IPU-POD64 is over 5x faster than a DGX A100 system for end-to-end BERT-Large Training to convergence to reference accuracies. To provide consistency in the comparisons used in our other charts, we also show time-to-train for a 2x DGX A100 system.
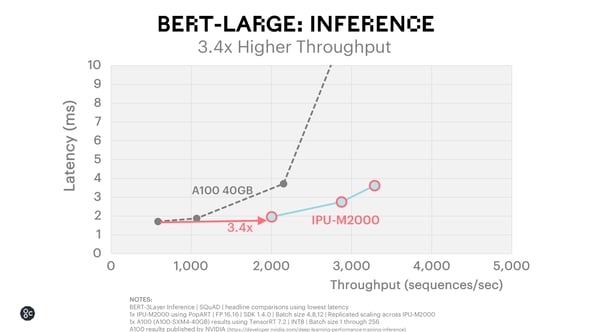
BERT-Large Inference
The goal in inference production systems is typically to achieve the highest possible throughput at the lowest possible latency. For example, search engine companies and many automated services using inference need to respond in near real time.
For BERT-Large Inference, the IPU-M2000 delivers 3.4x higher throughput at the lowest latency compared to the A100.
Computer Vision
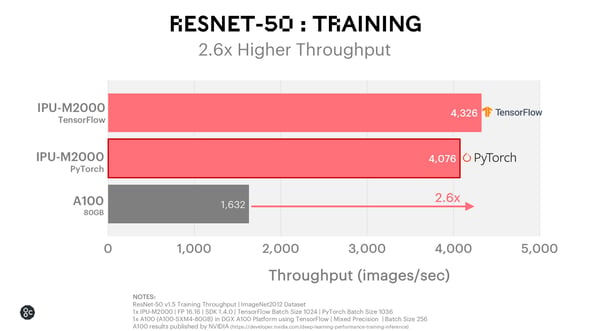
ResNet-50 Training
The IPU-M2000 processes 2.6x more images per second vs the A100 for ResNet-50, a common model for image classification used as a baseline performance metric across the industry, which has been highly optimised on GPU architectures. Here we show results for IPU with both TensorFlow and PyTorch.
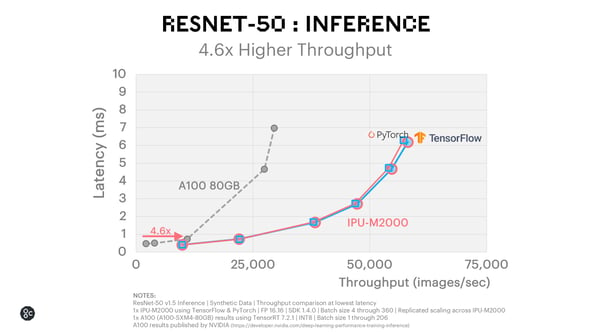
ResNet-50 Inference
The IPU-M2000 delivers 4.6x higher throughput at lowest latency comparing with published results for the A100 80GB GPU, for both PyTorch and TensorFlow, achieving much higher absolute throughput of 58,112 images per second.
EfficientNet Training
EfficientNet uses innovative techniques like group separable and depth-wise convolutions to deliver far higher accuracy per parameter than legacy image classification models like ResNet-50.
Group and depth-wise convolutions use smaller kernels which are not well suited to GPUs and this has limited their adoption to date.
By contrast, a fine-grained processor like the IPU, with its unique MIMD architecture, is much better suited to group convolution, depth-wise convolution and more generally sparse models which inherently do not use dense, contiguous data structures.
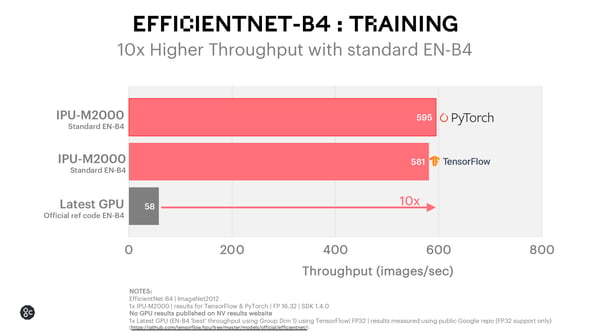
For standard EfficientNet-B4 Training for both PyTorch and TensorFlow, the IPU-M2000 achieves 10x throughput advantage versus the latest GPU.
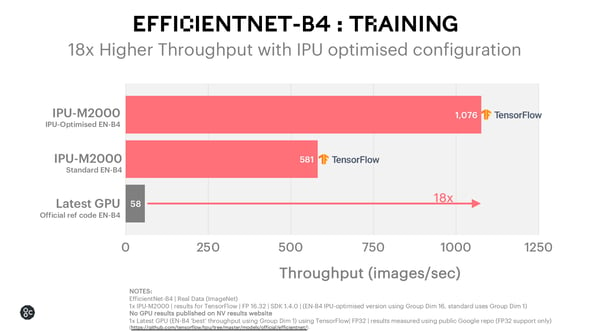
With optimised EfficientNet-B4 Training, the IPU-M2000 achieves 18x throughput advantage versus the latest GPU.
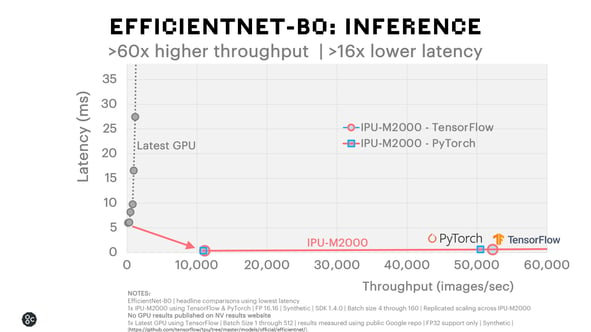
EfficientNet-B0 Inference
We see an even greater advantage with inference. The IPU-M2000 achieves more than 60x higher throughput and 16x lower latency than the latest GPU in a lowest latency comparison for both TensorFlow and PyTorch. In fact, the IPU-M2000 delivers higher throughput at its lowest latency than is achievable by the latest GPU at any batch size.
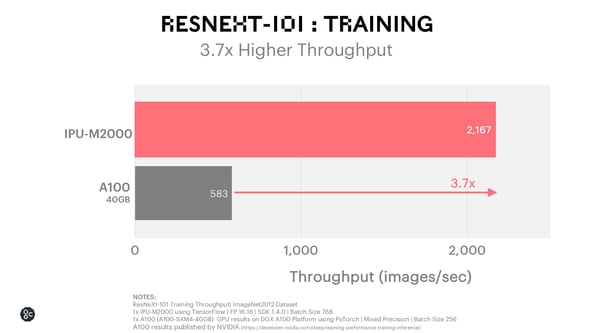
ResNeXt-101 Training
ResNeXt-101 is an innovative model that delivers higher accuracy for image classification. ResNeXt uses depth-wise separable convolutions which perform far better on the IPU architecture than on the GPU resulting in 3.7x higher throughput on the IPU-M2000 with TensorFlow vs A100 GPU.
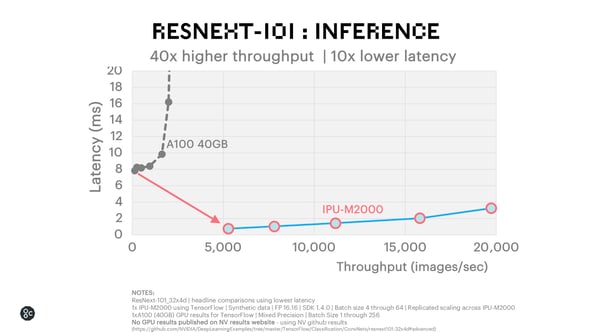
ResNeXt-101 Inference
The IPU-M2000 achieves 40x higher throughput and 10x lower latency for ResNeXt-101 inference using TensorFlow.
Probabilistic Learning
Probabilistic models are used in applications where the underlying system is inherently stochastic. They are widely used in the financial sector and as well as in scientific research. However, many varieties of probabilistic models do not fit well with the SIMD/SIMT architecture of GPUs and run far too slowly to be of use.
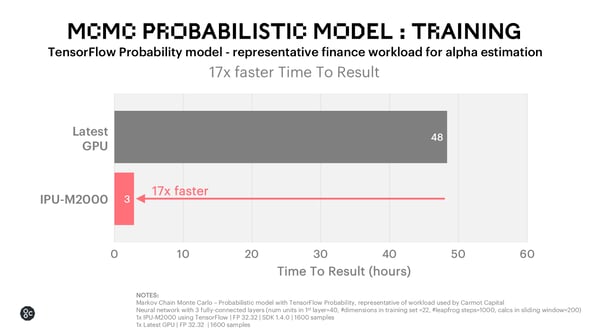
Markov Chain Monte Carlo (MCMC) Training
Using an off-the-shelf TensorFlow Probability (TFP) library to assess the performance of probabilistic models on IPU, we see that a financial MCMC workload trains in less than 3 hours on the IPU-M2000 platform, 17x faster than the 48 hours measured on the latest GPU.
Speech Processing
Converting written text into speech is a challenging but highly valuable area of speech technology research, with a wide variety of use-cases across most industry verticals.
A number of text-to-speech models have risen to prominence, including Tacotron from Google, Deep Voice from Baidu and FastSpeech from Microsoft, enabling high-quality, end-to-end speech synthesis.
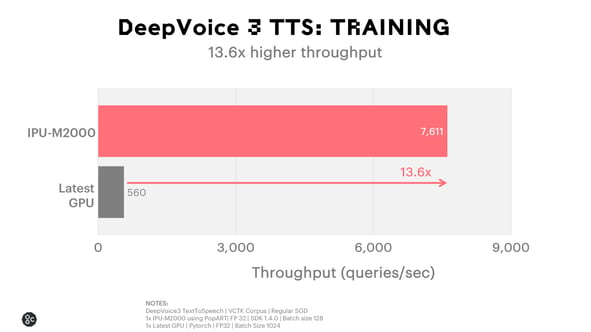
Deep Voice 3 Training
Here we focus on the third Deep Voice iteration. The Deep Voice 3 model is fully convolutional and uses attention blocks to decode the input text sequence to the output audio sequence representation. More details about our Deep Voice 3 implementation are provided in the Accelerating Text-To-Speech models with the IPU blog.
The chart below highlights the performance advantage of the IPU-M2000 on the Deep Voice 3 model, with over 13x higher throughput versus the latest GPU.
Time Series Analysis
Time series forecasting models can predict future values based on previous, sequential data. LSTM is one of the most widely used time series analysis models. Financial companies in particular rely on LSTMs for modelling and predicting financial data such as stock prices. The use of LSTM-based methods in the finance industry is highlighted in this arxiv paper.
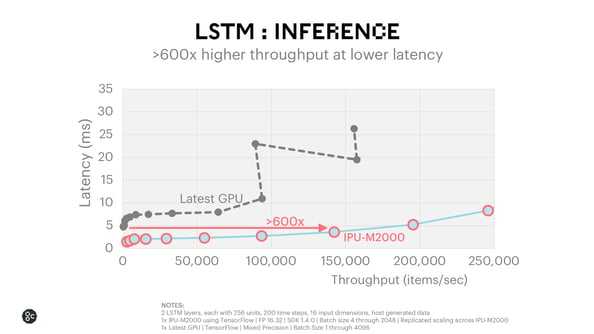
LSTM Inference
The chart below compares throughput vs latency across a range of batch sizes for the IPU-M2000 vs the latest GPU for an LSTM 2-Layer Inference model. Across a range of batch sizes the performance advantage is apparent. At the lowest latency achievable by the GPU, the IPU-M2000 is capable of achieving 600x higher throughput at a lower latency.
Future Breakthroughs with the IPU
As we have seen, the IPU delivers state of the art performance on established image processing and language models such as ResNet and BERT.
It is also clear that the IPU can deliver huge performance gains in several new or currently under-utilised model types which are indicative of the future trend in machine intelligence, like EfficientNet, ResNeXt and MCMC (Markov Chain Monte Carlo) probability-based methods.
We are also working on some exciting developments with sparse models, and are introducing a preview version of our generalized sparse library support in Poplar SDK 1.4, which was released today.
Machine intelligence innovation is still in the early stages and we expect to see many new innovations developed over the next few years. The IPU has been designed to help innovators create these new breakthroughs.
Graphcore IPU-M2000 and IPU-POD systems are shipping and available to order today through our partner network. For more information or to be contacted by one of our AI experts, please register your interest here.
The products, systems, software, and results are based on configurations existing at the time of the measurements, and as such are subject to change at any time, without notice. For more information regarding methodology or results, please contact us.
Share:

