
Jan 12, 2022
Jan 12, 2022
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamDelivering the best possible AI compute performance means optimizing every part of the system for the specific demands of artificial intelligence, including storage.
Following the recent addition of leading storage companies to our Elite Partner Program, we are now publishing our first reference architecture, in partnership with Pure Storage.
The technical guide details how Graphcore users can take advantage of the Pure’s flexible, high-performance FlashBlade technology as part of their IPU-POD configuration.
Both Pure and Graphcore are committed to delivering industry-leading performance, while supporting customers’ AI journeys as they seamlessly transition to next-generation compute systems.
FlashBlade is an all-flash system, optimized for storing and processing unstructured data, and scalable up to multi-petabyte capacity.
The system is based on five key innovations:
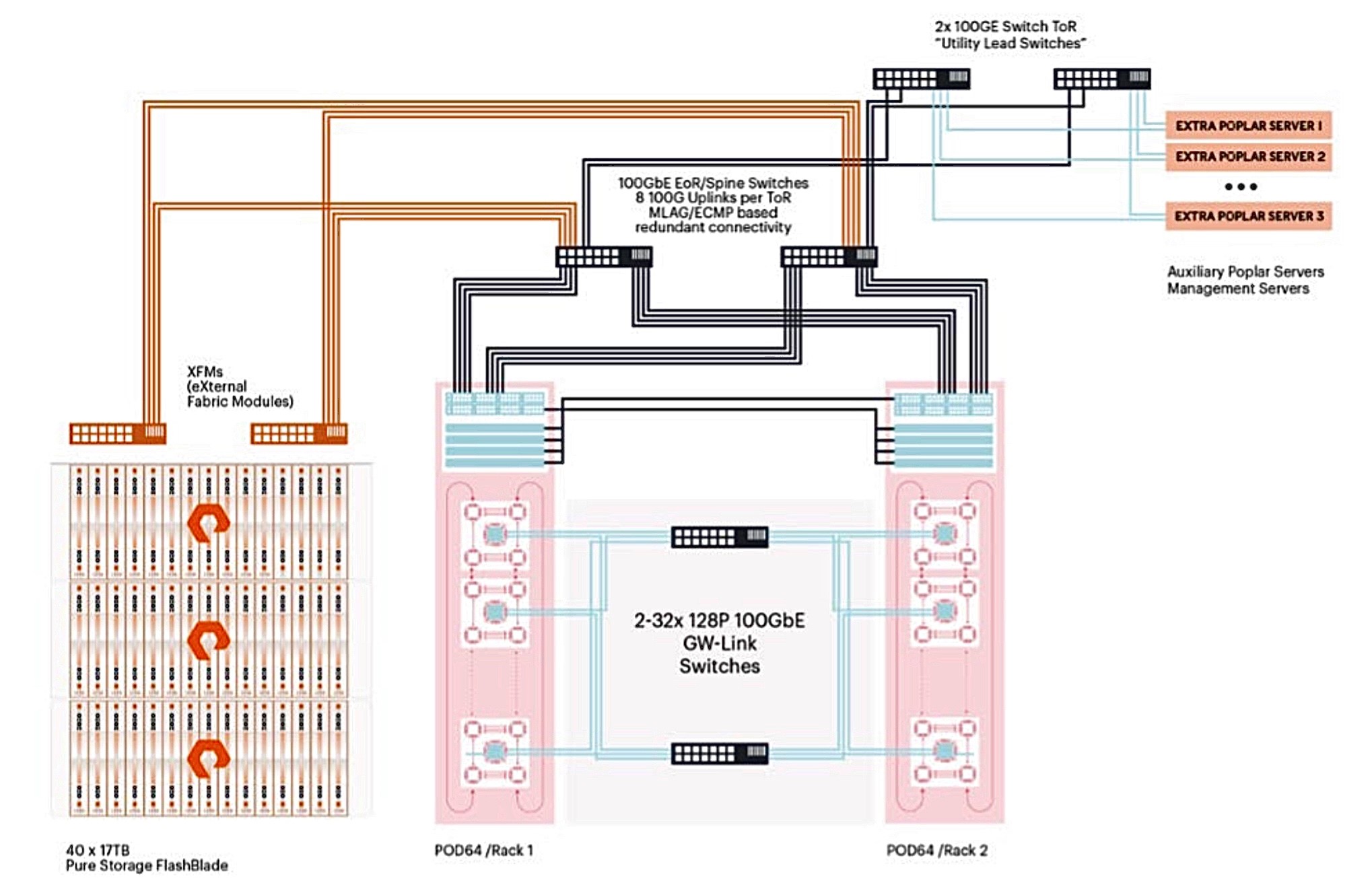
The Pure Storage and Graphcore reference architecture describes the hosts, storage, and networking configuration used in the IPU-POD64 reference architecture featuring the Pure Storage FlashBlade storage solution.
In addition to the IPU-POD configuration detailed in the RA, the FlashBlade storage solution was architected as follows:
As part of the joint reference architecture, Graphcore and Pure benchmarked system performance running ResNet-50 and BERT-Large, along with a number of standardised storage benchmarks for AI workloads.
Near-linear scaling was achieved as we increased the number of jobs run on the infrastructure, while optimal IPU performance was delivered with significant bandwidth capacity remaining on the 40-blade system.
More detail on benchmark performance is available in the reference architecture document.
For more details on Graphcore’s storage partners, read our blog.
To find a channel, technology or ecosystem partner, visit our Partner Program page.
Share:


