
Jul 15, 2020
Jul 15, 2020
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamI am delighted to introduce our second-generation IPU platform with greater processing power, more memory and built-in scalability for handling extremely large Machine Intelligence workloads.
The IPU-Machine M2000 is a plug-and-play Machine Intelligence compute blade that has been designed for easy deployment and supports systems that can grow to massive scale. The slim 1U blade delivers one PetaFlop of Machine Intelligence compute and includes integrated networking technology, optimized for AI scale-out, inside the box.
Each IPU-Machine M2000 is powered by four of our brand new 7nm Colossus™ Mk2 GC200 IPU processors, and is fully supported by our Poplar® software stack.
Users of our Mk1 IPU products can be assured that their existing models and systems will run seamlessly on these new Mk2 IPU systems but will deliver an incredible 8X step up in performance when compared to our already class-leading first-generation Graphcore IPU products.
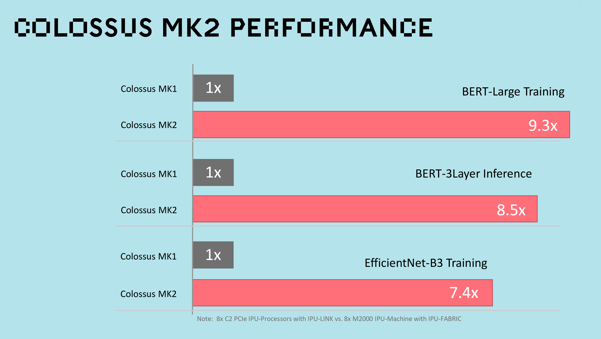
The design of our IPU-Machine M2000 allows customers to build datacenter-scale systems of up to 64,000 IPUs, in IPU-POD™ configuration, that deliver 16 ExaFlops of Machine Intelligence compute. Our new IPU-Machine M2000 is capable of handling even the toughest Machine Intelligence training or large-scale deployment workloads.
You can get started with a single IPU-Machine M2000 box, directly connected to one of your existing CPU-servers, or add up to a total of eight IPU-Machine M2000s connected to this one server. For larger systems, you can use our rack-scale IPU-POD64, comprising 16 IPU-Machine M2000s built into a standard 19-inch rack and scale these racks out to deliver datacenter-scale Machine Intelligence compute.

Connecting IPU-Machine M2000s and IPU-PODs at scale is made possible by our new IPU-Fabric™ technology, which has been designed from the ground-up for Machine Intelligence communication and delivers a dedicated low latency fabric that connects IPUs across the entire datacenter.
Our Virtual-IPU software integrates with workload management and orchestration software to easily serve many different users for training and inference, and allows the available resources to be adapted and reconfigured from job to job.
Whether you are using a single IPU or thousands for your Machine Intelligence workload, Graphcore’s Poplar SDK makes this simple. You can use your preferred AI framework, such as TensorFlow or PyTorch, and from this high-level description, Poplar will build the complete compute graph, capturing the computation, the data and the communication. It then compiles this compute graph and builds the runtime programs that manage the compute, the memory management and the networking communication, to take full advantage of the available IPU hardware.
If you’re looking to add Machine Intelligence compute into your datacenter, there’s nothing more powerful, flexible or easier to use than a Graphcore IPU-Machine M2000.
Innovation and advantage
Graphcore customers span automotive, consumer internet, finance, healthcare, research and more.
The number of corporations, organisations and research institutions using Graphcore systems is growing rapidly and includes Microsoft, Oxford Nanopore, EspresoMedia, the University of Oxford, Citadel and Qwant.
Graphcore’s technology is also being evaluated by J.P. Morgan to see if its solutions can accelerate the bank’s advances in AI, specifically in Natural Language Processing and speech recognition.
With the launch of the IPU-Machine M2000 and IPU POD64, the competitive advantage that we are able offer is extended even further.
Graphcore’s latest product line is made possible by a range of ambitious technological innovations across compute, data, and communication, that deliver the industry-leading performance customers expect.
Compute
At the heart of every IPU-Machine M2000 is our new Graphcore Colossus™ Mk2 GC200 IPU. Developed using TSMC’s latest 7nm process technology, each chip contains more than 59.4 billion transistors on a single 823sqmm die, making it the most complex processor ever made.

GC200 integrates 1,472 separate IPU-Cores, and is capable of executing 8,832 separate parallel computing threads. Each IPU processor core gets a performance boost from a set of novel floating-point technologies developed by Graphcore, called AI-Float. By tuning arithmetic implementations for energy and performance in Machine Intelligence computation, we are able to serve up one PetaFlop of AI compute in each IPU-Machine M2000 1U blade.
With class leading support for FP32 IEEE floating point arithmetic we also support FP16.32 (16bit multiply with 32bit accumulate) and FP16.16 (16bit multiply accumulate). However, our Colossus IPUs are unique in having support for Stochastic Rounding on the arithmetic that is supported in hardware and runs at the full speed of the processor. This allows the Colossus Mk2 IPU to keep all arithmetic in 16bit formats, reducing memory requirements, saving on read and write energy and reducing energy in the arithmetic logic, while delivering full accuracy Machine Intelligence results. Each of the 1,472 processor cores and each of the 8,832 parallel program threads can generate a separate random number seed with shaped noise, allowing a unique compute capability to support, for example, Probabilistic or Evolution Strategy models.
The AI-Float arithmetic block also provides native support for sparse arithmetic floating-point operations. We provide library support for different sparse operations including block sparsity and dynamic sparsity. This means that the IPU delivers much more efficient compute on sparse data, not just in inference, but also during training, helping innovators to create new types of complex models that deliver state of the art performance with much fewer parameters, faster training times and using much less energy.
Data
Our IPUs working together with Poplar, also have a radical new approach to memory organisation. Firstly, each IPU has a huge amount of In-Processor Memory™ with our new Mk2 GC200 having an unprecedented 900MB ultra-high-speed SRAM inside the processor. This is spread across the IPU, with In-Processor Memory sitting right next to each processor core in an IPU-Tile™ for the lowest energy access per bit. 900 MB is a 3x step up in density when compared to our Mk1 IPU and is enough to hold massive models, prior state, or many layers of even the world’s largest models inside the chip running at the full speed of the processor.
Our Poplar software also allows IPUs to access Streaming Memory™ through our unique Exchange-Memory™ communication. This allows large models with 100’s Billions of parameters to be supported. Each IPU-Machine M2000 can support Exchange-Memory™ with up to 450GB in density and with an unprecedented bandwidth of 180TBytes/sec. As a result, the IPU Exchange-Memory delivers over a 10x advantage in density together with over a 100x advantage in memory bandwidth when compared to the very latest 7nm GPU products.
Overall, the combination of the unique way that the IPU accesses memory, the class-leading In-Processor Memory design and Exchange Memory features, together with native support for sparsity, enable developers to execute machine learning models at very high speed, no matter how large or how complex.
Communication
Unlike other solutions, you don’t need to add expensive InfiniBand networking cards to connect the IPU-Machines; each IPU-M2000 has dedicated AI networking built in. We call this IPU-Fabric™.
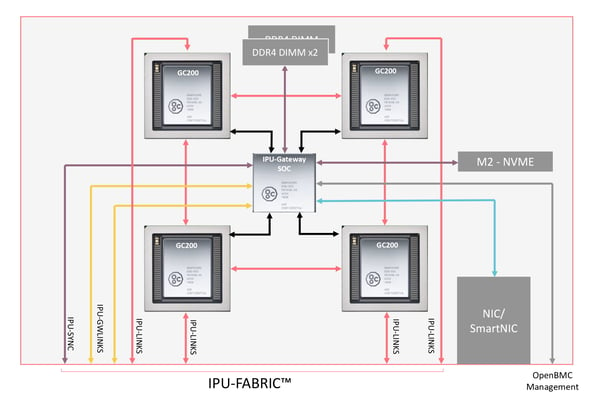
We created a new Graphcore GC4000 IPU-Gateway chip that delivers incredibly low latency and high bandwidth, for each IPU-Machine M2000 delivering 2.8 Tbps bandwidth. As you connect more IPU-Machine M2000 systems together, the overall bandwidth grows to many Petabits/sec.
And while IPU-Fabric has been built from the ground-up to maximise performance in IPU-based systems, it is also designed for maximum compatibility with existing datacenter infrastructure.
IPU-Fabric uses standard copper or optical OSFP connectors, linking IPUs up and down the rack. In larger configurations, communication between IPU-PODs uses tunneling-over-Ethernet technology to maintain throughput, while allowing the use of standard QSFP interconnect and 100Gb Ethernet switches – underscoring Graphcore’s commitment to straightforward deployment in mixed-use datacenters.
Across the entire system, IPU-Fabric uses a 3D ring topology, chosen both for maximum efficiency and because it maps well to the three dimensions of parallelism found in Machine Intelligence compute.
IPU-Fabric is fully supported by our Poplar SDK. As you extend your datacenter setup through the addition of extra IPU-PODs our Virtual-IPU software is used to tell Poplar how many machines are present for each workload and all subsequent adjustments to compile and other processes are taken care of by Poplar.
The incredible IPU-Fabric technology keeps communication latency close to constant while scaling from 10s of IPUs to 10s of thousands of IPUs.

The IPU-Machine M2000 also enables a flexible disaggregated model, where users are not confined to a fixed ratio of CPU to Machine Intelligence compute at a server level. Rather, Graphcore customers can choose their preferred mix of CPUs and IPUs, connected via Ethernet switches. You can easily change this ratio from one workload to the next. For example, NLP has relatively low CPU host processing requirements whereas image classification may require a higher ratio of servers to support more pre-processing of the data. The IPU-Machine M2000 allows these ratios to be changed and will support new applications as they emerge.
Virtual-IPU™ and workload management
Graphcore’s Virtual-IPU™ Technology allows users to dynamically provision which IPUs they want to associate with specific hosts, and to assign workloads even down to individual IPU level.
Virtual-IPU also supports multi-tenancy on the IPU-POD, allowing resources to be allocated, and then re-allocated, to different individuals, teams or tasks, in both private and public cloud environments.
For example, Graphcore technology might be running inference on a consumer image recognition service, accessed concurrently by thousands of users. The same IPU-POD hardware might then be used later to refine their models by running a large training job overnight. Our Virtual-IPU software interfaces to workload management systems such as Slurm and will support orchestration systems such as Kubernetes.
The IPU-Machine M2000s also support converged infrastructure deployments with OpenBMC hardware management built in. Each IPU-Machine M2000 provides a dedicated out-of-band management network port or provides the option for in-band management. Management data can be delivered via Redfish DTMF to management systems such as Grafana. And of course, our Poplar software and our IPUs support containerisation with Docker.
Availability
IPU-Machine M2000 and IPU-POD64 systems are available to pre-order today with full production volume shipments starting in Q4 2020. From today, early access customers are able to evaluate IPU-POD systems in the cloud, with our cloud partner Cirrascale.
More details on our OEM and channel partners will be announced during the coming months.
What Graphcore customers and partners are saying
Graphcore’s IPU products are already being used across a range of industries and research fields. Users have seen significant performance improvements over GPU-based technology, bringing commercial advantage and helping to advance research.
Graphcore’s technology is being evaluated by J.P. Morgan to see if its solutions can accelerate the bank’s advances in AI, specifically in Natural Language Processing and speech recognition.
Chris Seymour, Director, Advanced Platform Development, Oxford Nanopore said:“We have been testing Graphcore IPUs for some time now and have been really impressed with the potential of this technology. With IPUs we’ve seen impressive throughput in some of our key areas of research. We are excited to be testing Mk2 architecture and continue exploring the benefits of this innovative chip architecture”.
KS Lee, CEO, EspresoMedia, said: “We have been working with Graphcore IPUs for some time and we are seeing significant performance gains in a number of our machine learning workloads including video and image super resolution upscaling. We are delighted to be a lead customer for their Mk2 IPU platforms. The Mk2 IPU is extremely powerful and flexible and the IPU-Machine M2000 offers a real breakthrough platform for us to enable our customers to make new breakthroughs in Machine Intelligence.”
Dr. Kristofer Bouchard, Staff Scientist, Lawrence Berkeley National Laboratory: “By leveraging the Azure IPU preview we have seen impressive potential from the IPU, and look forward to driving new innovations on the Graphcore Mk2 platform. I expect the IPU-Machine M2000 to enable major breakthroughs in artificial intelligence.”
Professor Andrew Briggs, Department of Materials, University of Oxford: “Creating and maintaining solid state for use in quantum computers is, unsurprisingly, complex. Tuning them and keeping them stable requires analysing and controlling many sensitive variables in real-time. It is a perfect machine learning problem.
“The advanced AI models we use are already testing the limits of today’s accelerators. Our early work with Graphcore’s IPU has resulted in dramatic performance gains, thanks to its raw computing power, and the way it manages classic AI challenges such as sparsity.
“We’re tremendously excited by the announcement of Graphcore’s next generation IPU technology, and the associated computational power that will propel us further and faster into the future of quantum computing.”
Are Magnus Bruaset, Research Director, Simula Research Laboratory, said: “Our HPC department has been collaborating with Graphcore over the last two years, and at the end of 2019 Simula became an early access customer for their IPU-POD scale out platforms. We are impressed with Graphcore’s technology for energy-efficient construction and execution of large, next-generation ML models, and we expect significant performance gains for several of our AI-oriented research projects in medical imaging and cardiac simulations. We are also pursuing other avenues of research that can push the envelope for Graphcore’s multi-IPU systems, such as how to efficiently conduct large-scale, sparse linear algebra operations commonly found in physics-based HPC workloads.
Simula, as host of the national research infrastructure eX3, is delighted to announce that our IPU compute cluster will soon be available for research projects at the interface of HPC and AI. Academics in Norway and their international partners that are looking to make new breakthroughs in scientific research using machine learning are welcome to apply for access.”
Arnaud Bertrand, SVP & Fellow, Head of Strategy, Innovation and R&D BDS, Atos: “We are partnering with Graphcore to make their Mk2 IPU systems products, including IPU-Machine M2000 and IPU-POD scale out systems, available to our customers specifically large European labs and institutions. We are already planning with European early customers to build out an IPU cluster for their AI research projects. The IPU new architecture can enable a more efficient way to run AI workloads which fits to the Atos decarbonization initiative and we are delighted to be working with a European AI semiconductor company to realise this future together.”
Share:



