
Jul 27, 2021
Jul 27, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamGraphcore’s PopTorch™ framework is now integrated with PyTorch Lightning, allowing developers to run their PyTorch models on IPU systems with more ease than ever before.
PyTorch Lightning models minimise the number of code changes required to run a PyTorch model on the IPU. The full set of PopTorch features is supported in PyTorch Lightning as well as our integrated data loading utilities.
Our PopTorch framework requires a few minor modifications to be made to PyTorch code because it handles parts of the training loop internally. PopTorch uses the PopART™ (Poplar Advanced Runtime) autograd and manually applies the optimisers to allow our compiler stack to optimise the backprop/weight update step, enabling greater performance on the IPU. As a result, small changes then need to be made to the training loop to remove the redundant backward/optimiser application step. PyTorch Lightning eliminates the need for these steps and manages them for you.
PyTorch Lightning’s integration with PopTorch means that instead of making changes to the core training loop of the model, developers can write the model as they usually would for any other hardware architecture. Other small (one-line) changes which were previously required to update optimisers and run with learning rate schedulers are no longer necessary thanks to this integration.
Below we look at how to run a PyTorch Lightning model on the IPU with a single line of code.
We’ll keep our model simple for this tutorial.
This Lightning model already abstracts a few concepts that developers previously would have to use in normal PopTorch. The loss, optimisers and learning rate scheduling are used in the exact same way as they would be on a GPU or CPU.
Here we use the torchvision FashionMNIST dataset, training it on an IPU with the model above. This has been achieved with just one line of code by indicating to PyTorch Lightning how many replicas we want to run across.
ipus=1,
Changing that to 8 IPUs will do the same but will automatically replicate the model across 8 IPUs using PopTorch’s existing data parallel process.
ipus=8,
No other changes were required anywhere in the code – this shows just how powerful PyTorch Lightning’s functionality is.
Let’s review some of the most useful PopTorch features which are supported by PyTorch Lightning. Many of these features are exposed via a Python class in PopTorch called Options. This is used to configure various IPU-specific hardware and software settings.
These can be provided to PyTorch Lightning using an IPUPlugin object. Developers can set separate PopTorch Options for both training and inference. We will look at some of the commonly used options in this tutorial and a full list can be found in our user guide.
To reduce host overhead, we allow PopTorch to be configured to handle multiple batches of data at a time. This is not the same as running with a larger batch size. The model batch size remains the same, we simply pull in more batches per run to avoid the IPUs waiting on the data loader.
Setting these options will allow the IPU to pull in 300 x 4 x 8 batches at a time, so 9600 batches. This allows us to reduce communication overhead with the host by having the IPUs running for much longer before having to return to host. You can read more about batching here.
PopTorch fully supports native PyTorch data loaders, but for convenience we have provided our own lightweight wrapper which can be used in the place of a torch.utils.data.DataLoader. This works in tandem with the above batching semantics by automatically setting the total batch size based on the deviceIterations/replicationFactor/gradientAccumulation options. This avoids the user having to change any other parameter on the dataset.
Sometimes developers might want to run their model in a model parallel configuration, in addition to a data parallel configuration. To achieve this, we can use PopTorch’s model parallel annotation toolkit which is also available with PyTorch Lightning models. At any time before trainer.fit is called the model can be annotated using poptorch.BeginBlock annotations. This will partition the model into stages which will be automatically mapped onto the specified IPUs in a pipelined configuration. The annotations can be set after model creation, as above, in the model's __init__ function, or inside the train_step, so there is some flexibility around which approach to use.
Developers can also partition the model into non-pipelined parallel execution strategies; the full list of these can be found here.
Passing autoreport=True to the IPUPlugin object will trigger the generation of a Poplar graph and execution report which can be opened with the PopVisionTM Graph Analyser.
These reports extensively detail the memory and cycles used by each operation within the model. You can read about the PopVision Graph Analyser tool on our developer portal.
The runtime execution report of the pipelined model from above can be seen below.
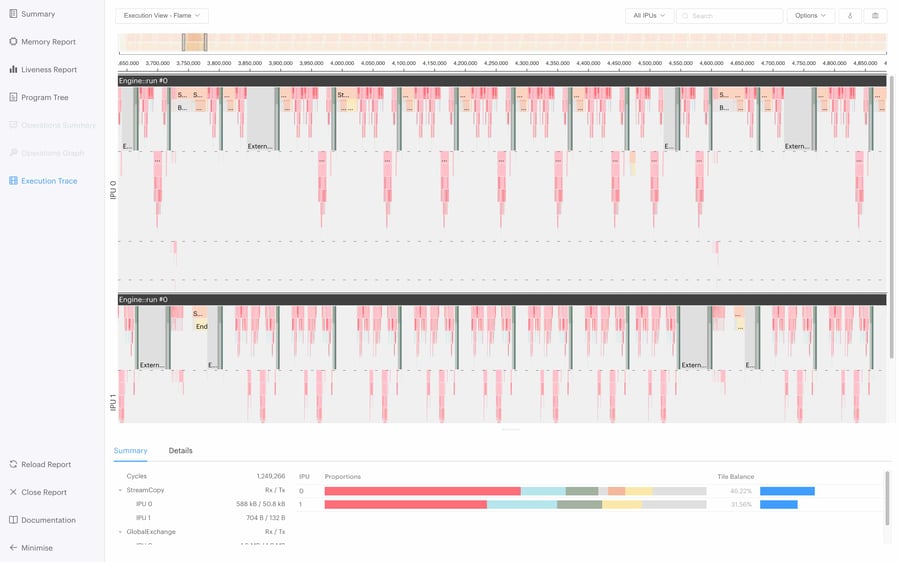
Outputting cycles for extremely long model runs may impact report readability so it is recommended to run for one epoch. If you want to just profile an individual step you can add the Lightning method on train batch start or any of the other Lightning early exit mechanisms to capture subsections of the IPU execution.
Graphcore PyTorch Lightning tutorials and examples
PyTorch Lightning MNIST example
PyTorch Lightning IPU support documentation
We would like to say a massive thank you to the team at PyTorch Lightning for their work in integrating our framework into their backend. We look forward to hearing from you and we welcome developer feedback as you use this integration.
Share:



