
Jan 26, 2021
Jan 26, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamToday, Graphcore is proud to take the next step in our commitment to helping customers accelerate their innovation and harness the power of AI at scale.
Together with Cirrascale Cloud Services, we have built something totally new for AI in the cloud, with the first publicly available Mk2 IPU-POD scale-out cluster, offering a simple way to add compute capacity on-demand, without the need to own and operate a datacentre.
We recognise that the tremendous opportunity offered by AI brings with it a unique set of computing challenges; model size is growing rapidly, and the bar for accuracy is constantly being raised. If customers are to take full advantage of the latest innovations, they need a tightly integrated hardware and software system built specifically for artificial intelligence.
Graphcloud is a secure and reliable IPU-POD family cloud service that allows customers to access the power of Graphcore’s Intelligence Processing Unit (IPU), as they scale from experimentation, proof of concept and pilot projects to larger production systems.
There are two offerings available at launch, with larger scale-out systems available in coming months:
IPU-POD systems deliver a lower total cost of training with improved time to solution compared to the latest GPU systems.
Graphcloud system instances are pre-installed with Poplar and systems software. Sample code and application examples are available locally for the state-of-the art models used in Graphcore benchmarks, including BERT, EfficientNet and more. Users also have access to comprehensive documentation to help them get started quickly with multiple frameworks, including PyTorch and TensorFlow.
One of the first Graphcore customers to use Graphcloud is UK-based Healx, whose artificial intelligence platform for drug discovery is identifying new treatments for rare diseases. The company was named ‘Best Use of AI in Health and Medicine’ at the 2019 AI Awards.
“We began using an IPU-POD16 on Graphcloud in late December 2020, porting our existing Mk1 IPU code to run on the Mk2 system - a frictionless process that delivered a huge performance advantage. Having more memory available for our models meant we no longer needed to shard our model and could focus on sharding our data instead. This resulted in simpler code and more efficient model training,” said Dan O’Donovan, Technical Lead, Machine Learning Engineering at Healx.
“Throughout our collaboration with Graphcore, we have always been granted access to the latest hardware, SDKs and tools. As well as that, there’s an ongoing dialogue with Graphcore’s expert hardware and software engineers, through direct meetings and the support desk.”
Pricing and specifications
Available System Types
Pricing
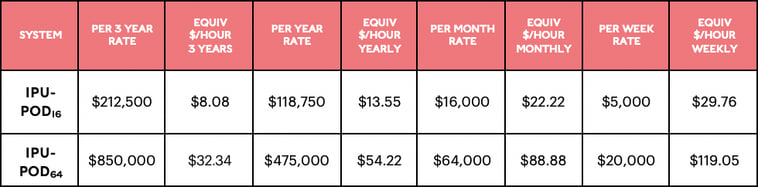
Specifications
Accelerate your innovation with Graphcloud
Graphcloud is available today.
For further information about Graphcloud including how to request access, visit graphcore.ai/graphcloud
Share:


