
Dec 08, 2021 \ Machine Learning, IPU-POD
Dec 08, 2021 \ Machine Learning, IPU-POD
共有:
GraphcoreのIPU-PODシステムは現在、大規模モデルの学習や微調整のために導入されています。銀行や医療、保険、行政、製造業において、特にAIファーストを掲げる先進的な企業・組織の間でGenerative Pre-Trained Transformer(GPT)モデルへの関心が高まっており、自然言語処理に対する需要も拡大しています。
MLPerf評価で当社が残した成果は、現在のモデルで実現できるコスト効率において、他のソリューションを凌ぐ能力が当社製品に備わっていることを示しています。IPU-POD128やIPU-POD256といった当社の大型フラッグシップシステムを使った革新的かつ新進気鋭のモデルにおけるMLPerf評価の成果と同時に明らかになったコンピュートスケーリングから、IPU-LinkやIPU-Fabricの帯域幅や容量が分かってきます。また、あらゆる機械学習モデルにおいて、目を見張るような性能の最適化を一貫して実現している当社のソフトウェアスタック、Poplarの成熟度も実証されました。
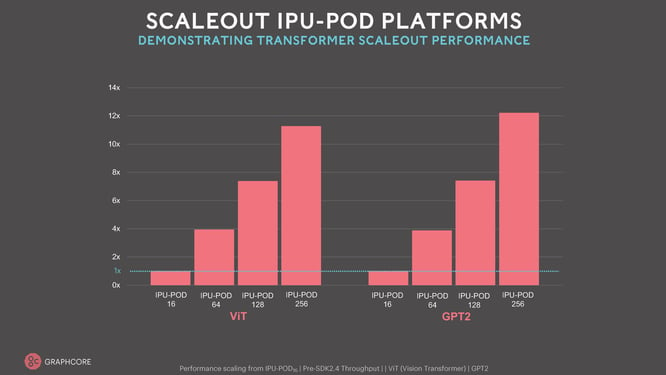 Graphcoreの大型IPU-PODシステムの性能能力には、まさに目を見張るものがあります。革新的なAIシステムであっても、異なる複数のプログラムにおいて、ペタバイト/秒のメモリ帯域幅を実現するこのようなメモリ容量で、これほど高いコンピュート性能を発揮するシステムは他にありません。
Graphcoreの大型IPU-PODシステムの性能能力には、まさに目を見張るものがあります。革新的なAIシステムであっても、異なる複数のプログラムにおいて、ペタバイト/秒のメモリ帯域幅を実現するこのようなメモリ容量で、これほど高いコンピュート性能を発揮するシステムは他にありません。
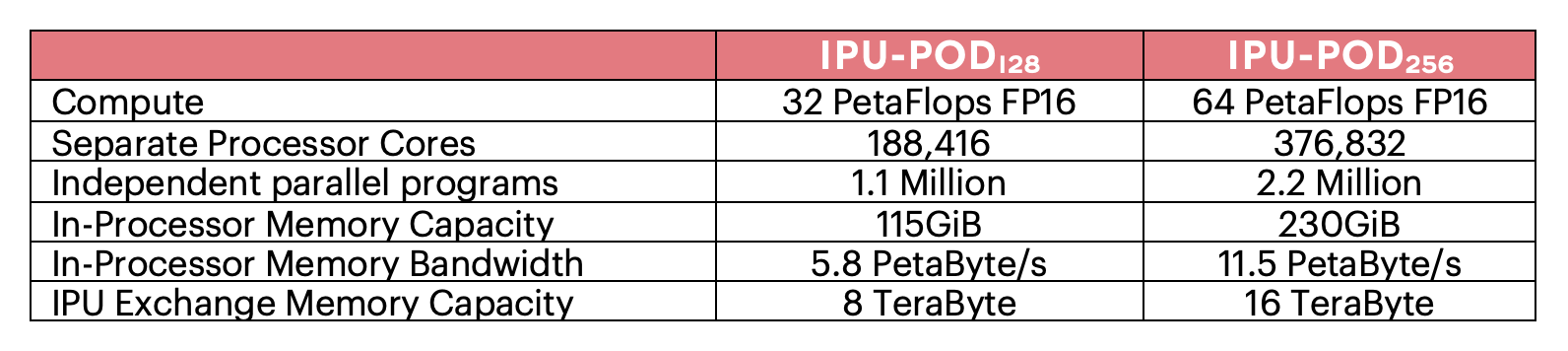 今までになく高い性能レベルを備えたIPU-POD128システムやIPU-POD256システム上で実験を行うことで、新しいタイプの大規模モデルを構築できます。IPU-POD256であれば、数百億のパラメータを持つモデルを、数十ペタバイト/秒のメモリ帯域幅でアクセスできるIPUのプロセッサ内メモリにすべて保持できます。これほどまでに高い帯域幅とモデルの大きさを組み合わせることで、イノベーターは新しいタイプの大規模モデルを探求でき、その結果、スパースなコンピューティングの可能性が引き出されて、AIの新しいアプローチへの扉が開かれます。今後は、関連する学習データだけが正しいパラメータに導かれるようなモデルを開発することで、モデル学習をより効率的に行えるようになるでしょう。今日の大規模モデルのアプローチにおいて従来のプロセッサが必要とするコンピュート機能は指数関数的に高まるばかりですが、そのような傾向からついに解放されるのです。
今までになく高い性能レベルを備えたIPU-POD128システムやIPU-POD256システム上で実験を行うことで、新しいタイプの大規模モデルを構築できます。IPU-POD256であれば、数百億のパラメータを持つモデルを、数十ペタバイト/秒のメモリ帯域幅でアクセスできるIPUのプロセッサ内メモリにすべて保持できます。これほどまでに高い帯域幅とモデルの大きさを組み合わせることで、イノベーターは新しいタイプの大規模モデルを探求でき、その結果、スパースなコンピューティングの可能性が引き出されて、AIの新しいアプローチへの扉が開かれます。今後は、関連する学習データだけが正しいパラメータに導かれるようなモデルを開発することで、モデル学習をより効率的に行えるようになるでしょう。今日の大規模モデルのアプローチにおいて従来のプロセッサが必要とするコンピュート機能は指数関数的に高まるばかりですが、そのような傾向からついに解放されるのです。
しかしGraphcoreの場合、数十億のパラメータが限界ではありません。付属のストリーミングメモリとPoplarソフトウェアSDKによってサポートされている当社のIPU交換メモリは、はるかに大きなモデルにも容易に対応できます。16テラバイトのIPU交換メモリ容量を備えるIPU-POD256システムであれば、数兆のパラメータを持つモデルにも対応できるのです。そのようなブレインスケールのモデルでも、GraphcoreのIPUプロセッサが実現する新たなコンピュートアプローチが力を発揮します。
このブログでは、開発者がこのような大規模モデルをIPU-PODシステムにマッピングしている方法について、いくつかのハイレベルな例をご紹介します。なお、同システムはすべて、成熟した使いやすいソフトウェアスタックであるPoplarによってサポートされています。
IPUの開発において、当社は高度にスケーラブルなメモリシステムの構築に重点を置きました。これはGraphcoreのIPUプロセッサに備わった最もエキサイティングで、将来を見越した特徴の一つです。私たちが開発したのは、メモリ構成に対する革新的なアプローチでした。
まず、膨大な量のプロセッサ内メモリを搭載することを重視しました。Colossus GC200の各IPUはプロセッサ内に約1ギガバイトのメモリを搭載しており、プロセッサの全計算速度でアクセスできます。これは前代未聞の設計です。次に、IPUが他のメモリソースにアクセスできるようにしました。当社はこれをストリーミングメモリと呼んでいます。当社のIPU-Machine M2000システムには、この機能専用のプラグイン式DDR-DIMMモジュールが搭載されています。このモジュールは通常、256ギガバイトのストリーミングメモリで構成されていますが、より大きなDIMMモジュールを使用してさらに大容量のメモリを構成することもできます。このシステムでは、Poplar SDKソフトウェアの制御の下、外部メモリソースからIPUプロセッサ内メモリにデータやプログラムをストリーミングできます。当社のPoplarソフトウェアは内部メモリと外部ストリーミングメモリ間のデータ交換をオーケストレーションできます。このような高機能メモリシステムの設計において、私たちは次のような2つの基本方針を貫いてきました。
各IPUプロセッサに組み込まれた高速IPU-Linkと、当社のIPU-Machine M2000システムに組み込まれたIPU-Fabricにより、より大規模なスケールアウトIPU-PODシステムを構築できるだけでなく、IPU-PODシステム全体でプロセッサ内メモリとストリーミングメモリの両方を共有することも可能になります。IPU-MachineのローカルDDR-DIMMからメモリをストリーミングするという原理は、他のIPUや他のIPU-MachineのメモリからIPU-Link経由でデータをストリーミングする場合でも同じです。このストリーミングは、IPU-PODシステムのどの部分からでも、また他のどの部分にでもオーケストレーションできます。 メモリの使用はすべて当社Poplar SDKソフトウェアによって管理されているので、高い柔軟性と高効率のメモリアクセスを同時に提供する用途に向けたプラットフォームを実現できるようになります。
「交換メモリ」とは、IPU内部、単一のIPU-Machine内部、およびIPU-PODシステムのIPU-Machine間のすべてにおいてプロセッサ内メモリとストリーミングメモリの使用を管理するPoplar SDKの機能を指す、当社独自の言葉です。Poplarがサポートする交換メモリの機能は豊富で、綿密に設計されており、機能の追加も常に行われています。これらは他の記憶階層と同様に、高速なローカルメモリ(一般的なプロセッサに比べてIPUのメモリは膨大)とストリーミングメモリ(はるかに大容量)のバランスを効率的に取る必要があります。
ストリーミングメモリは、ローカルのIPUとの間や、IPU-PODに散在する他のIPU-MachineのIPUとの間でデータをやり取りする際にかかる時間を最適化するのに使用できます。データを複製し、アクセスをシャーディングすることで、異なるコンピュートアプローチに対応できます。またストリーミングメモリは、ホストからの通信の中間バッファとしても機能します。これらの最適化はPoplar SDKでサポートされており、新しい最適化によってモデルのパイプライン化やシャーディングを容易に行えます。このような最適化の優れた特徴の一つは、用途に合わせて自動で動作することです。モデルを定義するハイレベルなフレームワークコードを変更する必要はありません。
IPU内部、IPU間、およびIPU-Machine間のデータの移動はすべて、IPUのバルク同期通信(BSP)方式によってサポートされています。
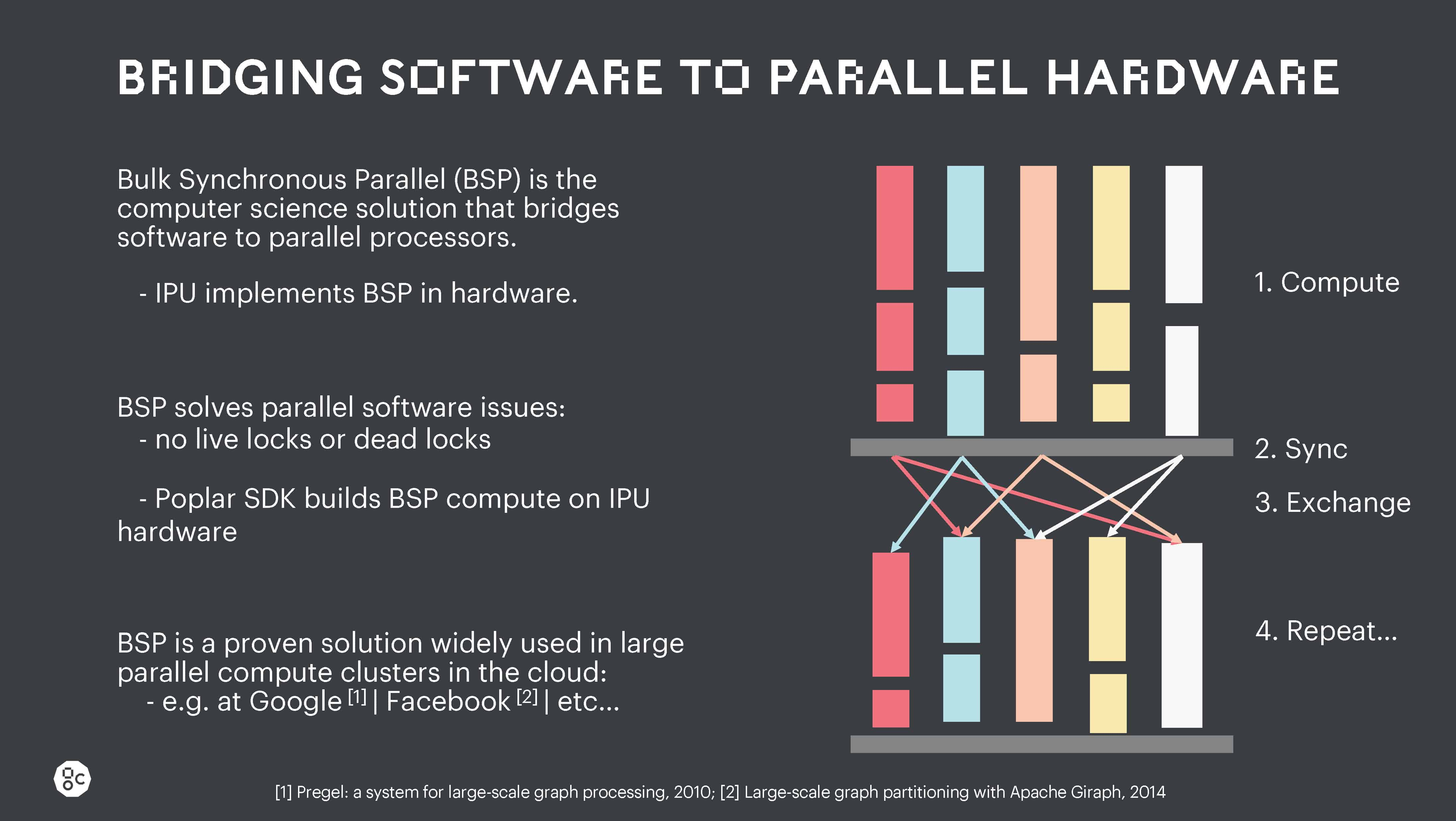 このロバストな並列処理アプローチによって、高度に並列化されたオペレーションを実現し、競合状態やライブロック、デッドロックが一切発生しなくなります。これほどまで明示的な並列実行制御は、他のどのプロセッサにもありませんが、大規模なモデルをロバストに実行し、大規模なスケールアウトマシンでの拡張性を維持するためには不可欠です。
このロバストな並列処理アプローチによって、高度に並列化されたオペレーションを実現し、競合状態やライブロック、デッドロックが一切発生しなくなります。これほどまで明示的な並列実行制御は、他のどのプロセッサにもありませんが、大規模なモデルをロバストに実行し、大規模なスケールアウトマシンでの拡張性を維持するためには不可欠です。
このBSPの実行に加えて、異なるプロセッサコア間の通信や、独立した並列プログラム間の通信もすべてPoplar SDKが管理します。またPoplar SDKは、ストリーミングメモリのアクセスを、コンピュート機能の背後に隠れてバックグラウンドで行われるようにオーケストレーションします。この仕組みによって、次に必要なデータやコードが、プログラム全体の実行時に必要になる前に、常に利用できるようになります。
このような高度な制御により、IPU-POD128またはIPU-POD256システム全体で大規模な計算タスクのオーケストレーションが可能になります。そればかりか、IPU-POD256システムを連結すればさらに大規模なシステムの構築も可能で、もちろんPoplar SDKのツールはそのようなシステムにも対応しています。 このような拡張性を利用することで、開発者は最高の性能の実現を目指し、様々なパイプラインモデル並列処理やテンソルモデル並列処理のアプローチを容易に探求できます。モデルの学習サイクルの後半で必要となるアクティベーションや重みづけは、ストリーミングメモリにアンロードされ、計算サイクルの後半でPoplarによってリストアされます。場合によっては、アクティベーションの小さなサンプルだけを保存しておき、モデルを学習する際にバックワードパスで中間のアクティベーションを再計算した方が良いこともあります。このようにすることでメモリ帯域幅を節約でき、IPUで利用可能な非常に高いレベルのコンピュート機能を効率的に利用できます。このトレードオフを利用すれば、コンピュート機能と帯域幅のバランスを取ることもできます。モデルによっては、より少ない計算でより大きな状態を必要とすることもあれば、より小さな状態でより大きな計算アクティビティを必要とすることもあります。このトレードオフはモデルの学習サイクル全体で変化することもあるので、コンピュート機能とI/Oの帯域幅のバランスを高度に制御し続けることが可能です。
GraphcoreのPoplar SDKは、TensorFlowやPytorchなどのAIフレームワークから高レベルのモデル記述を受け取り、この高度に抽象化されたグラフ表現を低レベルのコンピュートグラフにマッピングした上で、IPU内部またはIPUのグループ全体で実行できるようにコンパイルします。
Poplar SDKシステムはコンピュートを構築するだけでなく、各IPUプロセッサに内蔵されているIPU交換ファブリックのあらゆる通信に加え、IPU-PODシステム内部の個別のIPUを接続するIPU-LinkやIPU-Fabric全体の通信もオーケストレーションします。またPoplarはすべてのデータストレージを管理し、正しいデータが正しい場所に、正しいタイミングで置かれるようにすることで、次の段階のコンピュートをサポートします。この極めて精巧なアプローチにより、大規模モデルをIPU-PODシステムのすべてのIPUプロセッサでスケールアップすることができ、複数のIPU-PODシステムにコンピュートを分散させることも可能になるのです。
しかし、Poplarが生成するコンピュートグラフは、より小さなサブグラフに分割して、IPUで段階的に実行することもできます。このサブグラフの状態は、コンピュートがグラフ全体を通過する際に、ストリーミングメモリからバックグラウンドで出し入れされます。私たちはこれを段階的実行と呼んでいます。段階的実行で使用されるサブグラフのとても簡単な例を以下に示します。それぞれのサブグラフは、ResNet-50モデルのレイヤーにおける別々の段階を示しています。ヒートマップは、各計算段階におけるコンピュートグラフの実行部分を示しています。
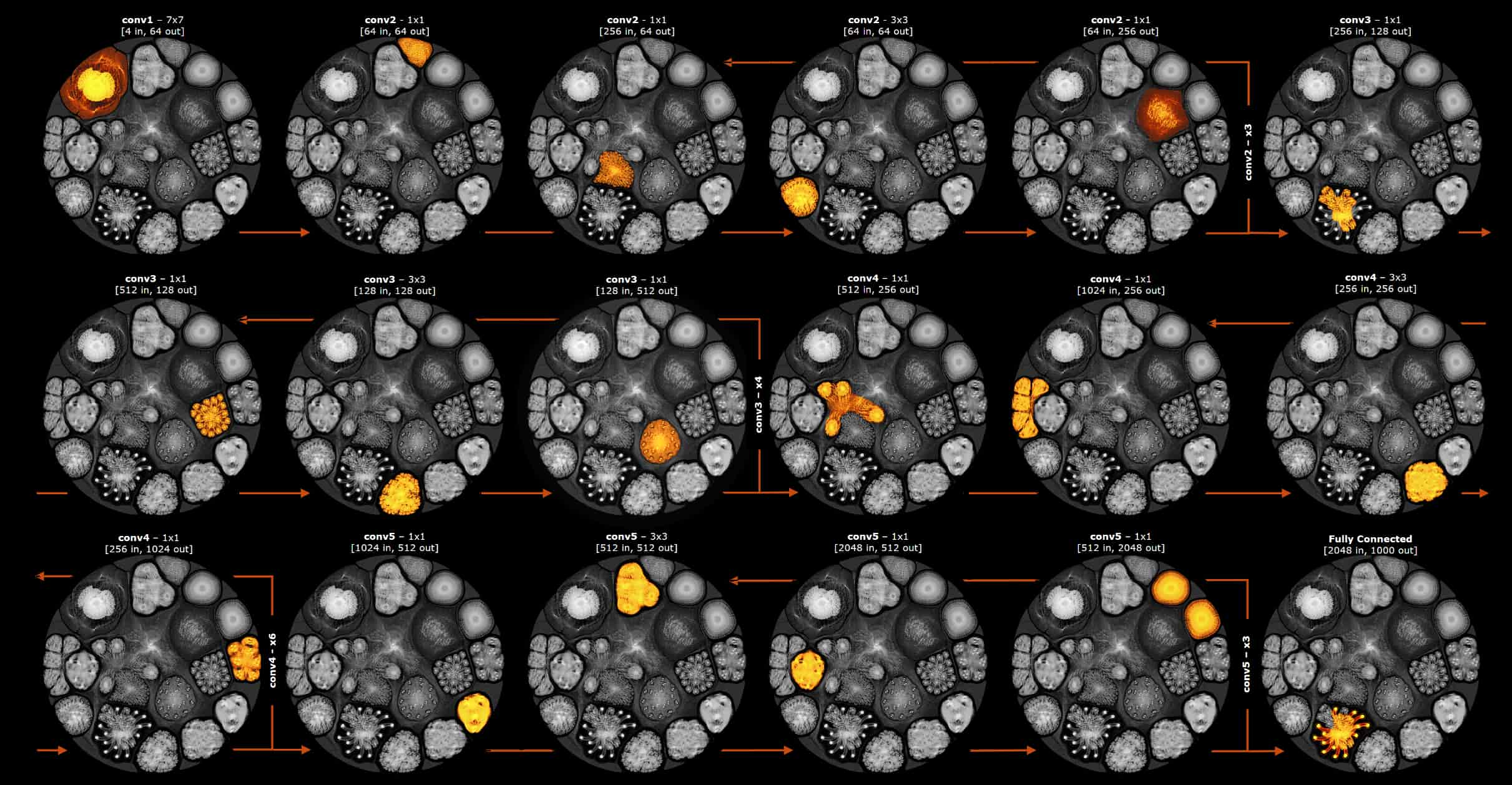
ResNet-50モデルのレイヤーをまたぐ段階的実行を表した簡単な例
開発者はサブグラフのサイズを制御することで、大規模なプロセッサ内メモリを最大限に活用できます。接続されたメモリとの間で常にデータの入れ換えが必要なGPUとは異なり、IPUはプロセッサ内部に大量の状態を保持できます。このようなアプローチにより、外部メモリの帯域幅に関する要件が劇的に軽減され、IPUはより大容量のDDR-DIMMモジュールを利用できるようになります。IPUのプロセッサ内メモリの利点については、先日開催されたHot Chipsカンファレンスでの講演で当社CTOのSimon Knowlesが行った説明をご覧ください。
段階的実行により、大規模モデルをIPUプロセッサの配列にマッピングする際の柔軟性を、効果的に別次元まで高めることができます。
IPU-POD128システムとIPU-POD256システムには、膨大な数のパラメータや大きなアクティベーション状態、複雑なオプティマイザ状態を持つ大規模モデルをすべてサポートする、豊富なリソースが備わっています。そしてPoplar SDKの豊富なソフトウェア機能により、開発者はこれらの強力なコンピューティングプラットフォームに大規模モデルをマッピングできます。
モデルを多数のIPUに分解すれば、高速な学習にも対応できます(下図を参照)。深層学習モデルのステージは、p軸に接続されたIPU間でパイプライン化できます。モデルのテンソルを、t軸に接続された複数のIPUにシャーディングすることも可能です。そして学習データは、GPUでもよく使われる従来のデータ並列パスに分割できます。これがデータレプリカの次元を示すr軸です。データレプリカの次元に関連して、ストリーミングメモリを使ってモデルの重みづけデータにアクセスできます。モデル全体の重みづけをレプリカの中で分割すれば、メモリをより効率的に使用し、実行段階ごとにのみ複製することができます。私たちはこれを複製テンソルシャーディング(rts)と呼んでいます。オプティマイザの状態(モーメンタム項など)は、メインの重みづけよりもアクセス頻度が低いため、重みづけとは異なる数のレプリカに分散させることがあります(rts')。サブグラフでのこの並列実行に加えて、サブグラフのサイズを最適化しながらモデルのレイヤーをまたいで段階的実行を実装することで、サブグラフの計算に必要なすべての状態を大容量のIPUプロセッサ内メモリに保持したまま、ハイレベルのコンピュート機能を実現することができます。
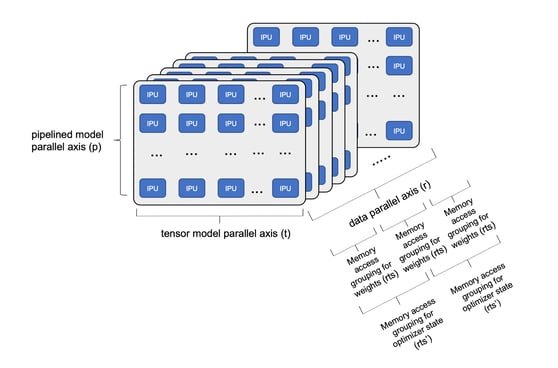
IPU-POD全体でのモデル分解
特定のモデル分解におけるIPUの総数はt*p*rとして計算されます。さらにモデルのパイプライン化やテンソルのシャーディング、データ並列度のレベルを変えることで、IPU-POD128システムまたはIPU-POD256システムで利用可能なすべての計算リソースとメモリリソースを効率的に使用する大規模モデルを構築できます。
それぞれのIPUは、1/(t * p)で与えられた重みづけの割合を使用しますが、それぞれのIPUのプロセッサ内メモリに保存されている重みづけの割合は、複製されたテンソルシャーディングを考慮して1/(t * p * rts)として計算できます。その上で段階的実行を進めれば、各サブグラフで利用可能な重みづけの割合を最適化し、IPUのプロセッサ内メモリを最大限に利用しながら、計算効率も最大化できます。
グローバルバッチサイズは、レプリカバッチサイズをbとして、b * rで計算されます。開発者は適切なレプリカバッチサイズを選択することで、モデルに対して望ましいグローバルバッチサイズを得ることができます。
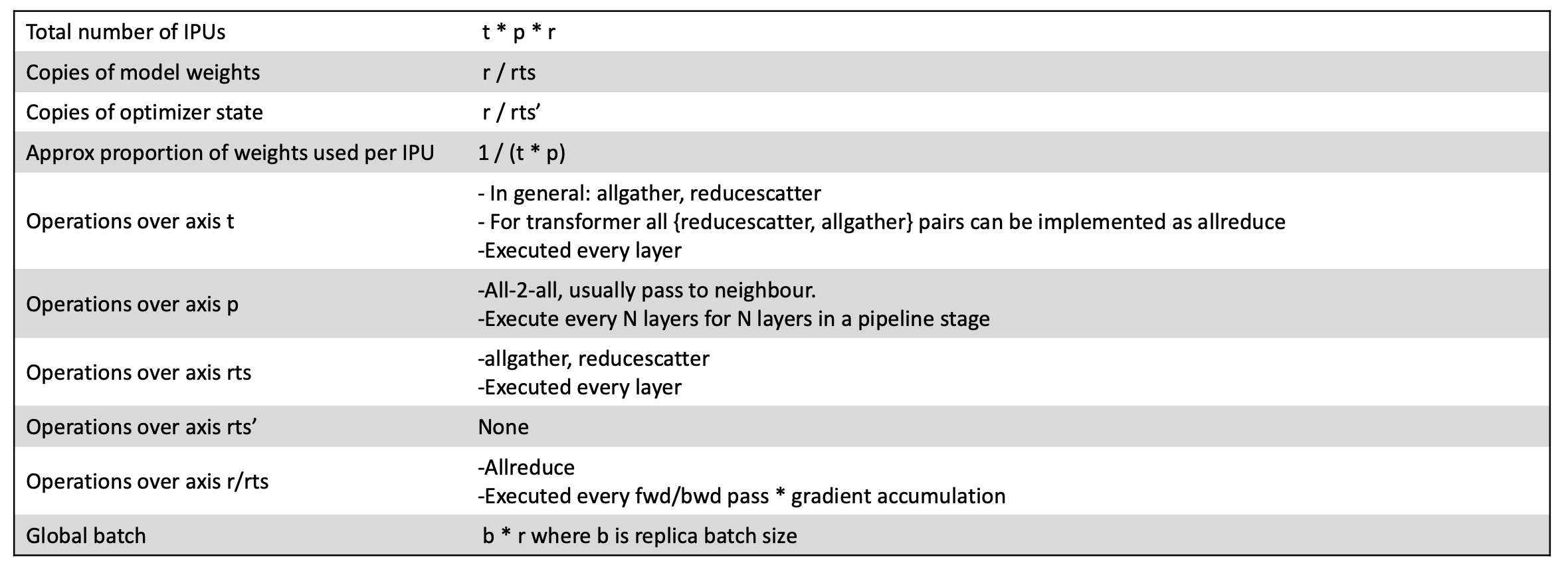 より分かりやすくするために、さらに小さなIPU-POD16システムにマッピングしたBert-Largeモデルの簡単な例で説明してみましょう。
より分かりやすくするために、さらに小さなIPU-POD16システムにマッピングしたBert-Largeモデルの簡単な例で説明してみましょう。
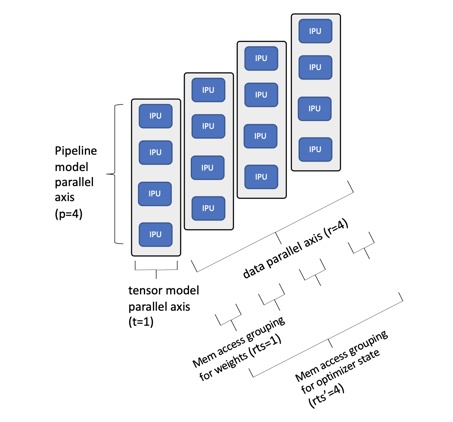
IPU-POD16にマッピングされたBERT-Largeの例
この例では、モデルを4個のIPUプロセッサでパイプライン化し、テンソルをシャーディングしませんでした。IPU-POD16システムに搭載されている16個のIPUプロセッサすべてを最大限に活用するため、データ並列度を4にしました。パイプラインの深さを8次元に拡張すれば、この1台のIPU-POD16システムで、すべてのオプティマイザの状態を含むモデル全体をIPUのプロセッサ内メモリに収めることができ、クラス最高の学習性能と微調整能力を達成できます(このことは、当社がMLPerf性能評価で残した成果で実証されています)。
より複雑な例として、175Bnのパラメータを持つGPT-3 NLPモデルをIPU-POD256システムにマッピングしたケースを見てみましょう。
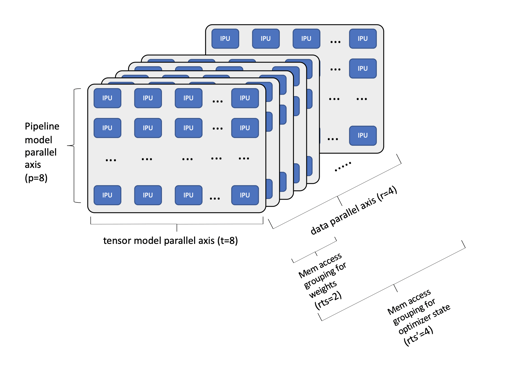
IPU-POD256にマッピングされた175Bnのパラメータを持つGPT-3の例
この例では、はるかに大きなモデルが1台のIPU-POD256システムにマッピングされています。このケースではパイプラインモデルの深さを8とし、パイプラインの各ステージで8個のIPUにテンソルをシャーディングしています。これにより、データ並列軸の各データレプリカに対応するIPUは合計64個となり、データ並列軸の幅を4にすれば、システム内の256個のIPUプロセッサをすべて使用することができます。より小さなGPTクラスのモデルであれば、IPUのプロセッサ内メモリにすべての重みづけを収めることができますが、175Bnのパラメータでは段階的実行を利用して、このより大規模なモデルを少数のサブグラフに分割しています。GPT-3モデルの96個のレイヤーでは、利用可能なすべてのプロセッサ内メモリとすべてのコンピュートリソースを効率的に使用できます。段階的実行を使用して実装されるより多くのサブグラフに拡張すれば、数兆ものパラメータを持つ、より大規模なモデルにも対応できます。また、ネットワークに接続された複数のIPU-POD256システム全体にスケールアップすれば、学習時間をさらに短縮できます。
GPTをはじめとする今日の大規模なAIモデルでも、IPU-PODシステムを使えば簡単に対応できることがお分かりいただけたでしょうか。IPU-PODシステムをスケールアップすれば、最大規模のモデルにも対応できます。しかしそれだけではありません。十分な余裕があるプロセッサ内メモリと、はるかに高度に並列化されたIPUプロセッサの組み合わせによって、さらに多くの次世代大規模モデルを探求する機会も広がるのです。IPUは、スパースなモデルやグラフニューラルネットワークなど、興味深い研究分野ですでに導入されています。高機能のIPU-POD128システムやIPU-POD256システムを使って、世界を驚かせるような新しいブレークスルーがイノベーターの間から誕生することを楽しみにしています。
共有:


