
Dec 08, 2021 \ Machine Learning, IPU-POD
Dec 08, 2021 \ Machine Learning, IPU-POD
공유:
현재 고객들은 대규모 모델을 훈련하고 미세 조정하기 위해 그래프코어 IPU-POD 시스템을 배포하고 있습니다. 은행, 의료, 보험, 정부, 제조 및 기타 AI 기반 분야의 많은 조직들이 GPT(Generative Pre-Trained Transformer) 모델에 더욱 많은 관심을 보임에 따라 자연어 처리에 대한 수요가 크게 증가하고 있습니다.
MLPerf 결과에서 드러난 그래프코어 솔루션의 성능은 최신 모델의 비용 효율성 측면에서 다른 솔루션을 능가했습니다. 그와 동시에 대형 플래그십 IPU-POD128 및 IPU-POD256 시스템의 선도적이고 혁신적인 모델에 대한 MLPerf 결과에서 그래프코어가 공유한 연산 확장 능력은 그래프코어 IPU-Link 및 IPU-Fabric의 뛰어난 대역폭과 용량을 보여 줍니다. 또한 그래프코어의 소프트웨어 스택 Poplar에 대한 시연을 통해 모든 머신 러닝 모델에 걸쳐 인상적인 성능 최적화를 지속적으로 제공한다는 사실을 증명했습니다.
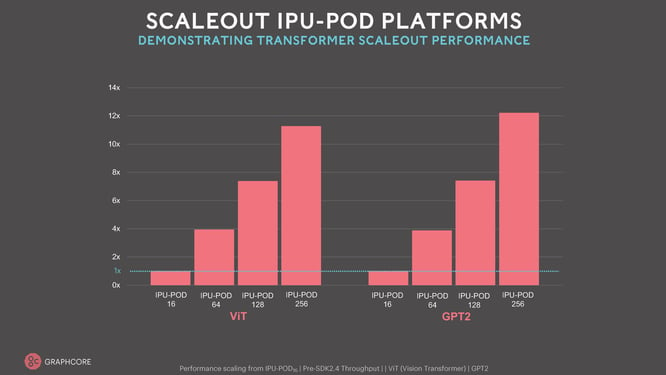 대규모 IPU-POD 시스템의 성능은 매우 놀랍습니다. 다른 어떤 혁신적인 AI 시스템도 수많은 독립 프로그램과 페타바이트/초 메모리 대역폭을 제공하는 메모리 용량을 바탕으로 이러한 연산 능력을 제공하지 못합니다.
대규모 IPU-POD 시스템의 성능은 매우 놀랍습니다. 다른 어떤 혁신적인 AI 시스템도 수많은 독립 프로그램과 페타바이트/초 메모리 대역폭을 제공하는 메모리 용량을 바탕으로 이러한 연산 능력을 제공하지 못합니다.
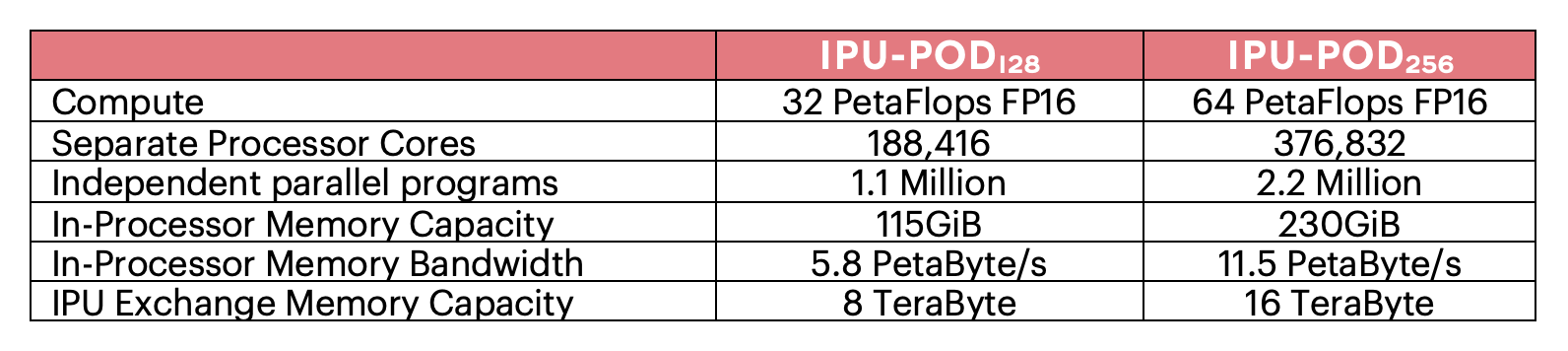 이러한 새로운 차원의 성능을 통해 고객은 IPU-POD128 및 IPU-POD256 시스템에서 새로운 유형의 대규모 모델을 실험하고 구축할 수 있습니다. IPU-POD256은 수십 페타바이트/초 메모리 대역폭에서 액세스할 수 있는 IPU의 인프로세서 메모리 내부에 수백억 개의 매개변수가 있는 모델을 포함할 수 있습니다. 이러한 높은 대역폭을 지닌 모델 크기 조합을 통해 혁신가들은 희소 연산 능력의 가능성을 열고 새로운 AI 접근 방식을 제시하는 새로운 유형의 대규모 모델을 탐구할 수 있습니다. 이제 훨씬 더 효율적인 모델 훈련을 위해 관련 훈련 데이터만 올바른 매개변수에 전달하는 모델을 개발할 수 있습니다. 또한 오늘날의 대규모 모델 접근 방식을 통해 기존 프로세서가 요구하는 기하급수적인 연산 증가로부터 해방될 수 있습니다.
이러한 새로운 차원의 성능을 통해 고객은 IPU-POD128 및 IPU-POD256 시스템에서 새로운 유형의 대규모 모델을 실험하고 구축할 수 있습니다. IPU-POD256은 수십 페타바이트/초 메모리 대역폭에서 액세스할 수 있는 IPU의 인프로세서 메모리 내부에 수백억 개의 매개변수가 있는 모델을 포함할 수 있습니다. 이러한 높은 대역폭을 지닌 모델 크기 조합을 통해 혁신가들은 희소 연산 능력의 가능성을 열고 새로운 AI 접근 방식을 제시하는 새로운 유형의 대규모 모델을 탐구할 수 있습니다. 이제 훨씬 더 효율적인 모델 훈련을 위해 관련 훈련 데이터만 올바른 매개변수에 전달하는 모델을 개발할 수 있습니다. 또한 오늘날의 대규모 모델 접근 방식을 통해 기존 프로세서가 요구하는 기하급수적인 연산 증가로부터 해방될 수 있습니다.
하지만 연결된 스트리밍 메모리와 Poplar 소프트웨어 SDK를 통해 지원되는 그래프코어의 IPU 익스체인지 메모리는 훨씬 더 큰 모델을 간편하게 지원할 수 있으므로 매개변수 개수가 수십억 개로 제한되지 않습니다. IPU-POD256 시스템의 16테라바이트 IPU 익스체인지 메모리 용량은 매개변수 수조 개가 포함된 모델을 지원할 수 있는 가능성을 열어 줍니다. 이러한 브레인 스케일(brain-scale) 모델은 그래프코어 IPU 프로세서가 제공하는 새로운 연산 방식을 활용할 수 있습니다.
이 블로그에서는 개발자들이 이러한 대규모 모델을 IPU-POD 시스템에 매핑하는 방법에 대한 몇 가지 사례를 소개합니다. 해당 사례들은 모두 성숙하고 쉽게 사용할 수 있는 소프트웨어 스택 Poplar에서 지원됩니다.
그래프코어는 IPU를 개발할 때 확장성이 우수한 메모리 시스템을 구축하는 데 초점을 맞추었습니다. 이는 그래프코어 IPU 프로세서의 매우 흥미롭고 미래 지향적인 측면 중 하나입니다. 저희는 메모리 구성에 대한 혁신적인 접근 방식을 개발했습니다.
첫째, 엄청난 양의 인프로세서 메모리를 확보하는 데 집중했습니다. 각 Colossus GC200 IPU는 약 1기가바이트의 메모리를 프로세서 내에 포함하고 있으며, 해당 메모리는 프로세서의 전체 연산 속도로 액세스할 수 있습니다. 둘째, IPU가 스트리밍 메모리라고 불리는 다른 메모리 소스에 액세스할 수 있도록 했습니다. 그래프코어의 IPU-Machine M2000 시스템에는 이러한 목적을 위한 플러그인 DDR-DIMM 모듈이 포함되어 있습니다. 일반적으로는 256GB의 스트리밍 메모리로 구성되지만, 대용량의 메모리를 위해 더 큰 DIMM 모듈로 구성할 수도 있습니다. Poplar SDK 소프트웨어의 관리 기능을 사용하여 데이터와 프로그램을 외부 메모리 소스에서 IPU 인프로세서 메모리로 스트리밍할 수 있습니다. 그래프코어의 Poplar 소프트웨어는 내부 메모리와 외부 스트리밍 메모리 간의 데이터 교환을 오케스트레이션할 수 있습니다. 이러한 정교한 메모리 시스템의 설계는 다음의 두 가지 핵심 원칙에 기반합니다.
각 IPU-Processor에 내장된 고속 IPU-Link와 각 IPU-Machine M2000 시스템에 내장된 IPU-Fabric을 통해 더 큰 스케일아웃 IPU-POD 시스템을 구축할 수 있을 뿐만 아니라, 전체 IPU-POD 시스템에서 인프로세서 메모리와 스트리밍 메모리를 모두 공유할 수 있습니다. IPU-Machine의 로컬 DDR-DIMM에서 메모리를 스트리밍하는 데 적용되는 원칙이 다른 IPU 및 다른 IPU-Machine 메모리에서 IPU-Link를 통해 데이터를 스트리밍하는 데도 동일하게 적용됩니다. 이는 IPU-POD 시스템의 어느 부분에서 어느 부분으로든 오케스트레이션될 수 있습니다. 모든 메모리 사용은 Poplar SDK 소프트웨어에서 지시하며, 이를 통해 고효율 메모리 액세스와 더불어 최고의 유연성을 보장하는 애플리케이션용 플랫폼을 제공할 수 있습니다.
익스체인지 메모리는 IPU 내부 및 단일 IPU-Machine 내부에서 그리고 IPU-POD 시스템 내 IPU-Machine 간의 인프로세서 메모리와 스트리밍 메모리의 사용을 관리하는 Poplar SDK 기능을 지칭하는 용어입니다. Poplar에서 지원하는 익스체인지 메모리 기능은 광범위하며, 신중하게 설계되었고 지속적으로 추가됩니다. 여타 메모리 계층 구조와 마찬가지로, 이러한 도구는 고속 로컬 메모리(IPU가 대부분의 프로세서보다 월등히 더 많은 개수 보유)와 스트리밍 메모리(훨씬 더 큰 용량 제공) 간의 균형을 효율적으로 유지해야 합니다.
스트리밍 메모리를 사용하면 로컬 IPU에 데이터를 보내고 받거나 IPU-POD에 분산된 다른 IPU-Machine의 IPU에 데이터를 이동하는 데 걸리는 시간을 최적화할 수 있습니다. 데이터를 복제하고 액세스를 샤딩하여 다양한 연산 접근 방식을 지원할 수 있습니다. 또한 스트리밍 메모리는 호스트와의 통신을 위한 중간 버퍼 역할도 할 수 있습니다. 이러한 최적화는 Poplar SDK에서 지원되며, 새로운 최적화는 사용자가 모델을 쉽게 파이프라이닝하고 샤딩하는 데 도움이 됩니다. 이러한 최적화의 가장 큰 장점 중 하나는 애플리케이션과 함께 자동으로 작동할 수 있다는 점입니다. 따라서 모델을 정의하는 상위 수준 프레임워크 코드를 변경할 필요가 없습니다.
IPU 내부에서, IPU 간에 그리고 IPU-Machine 간의 데이터 이동은 모두 IPU BSP(Bulk Synchronous Communication) 체계에서 지원됩니다.
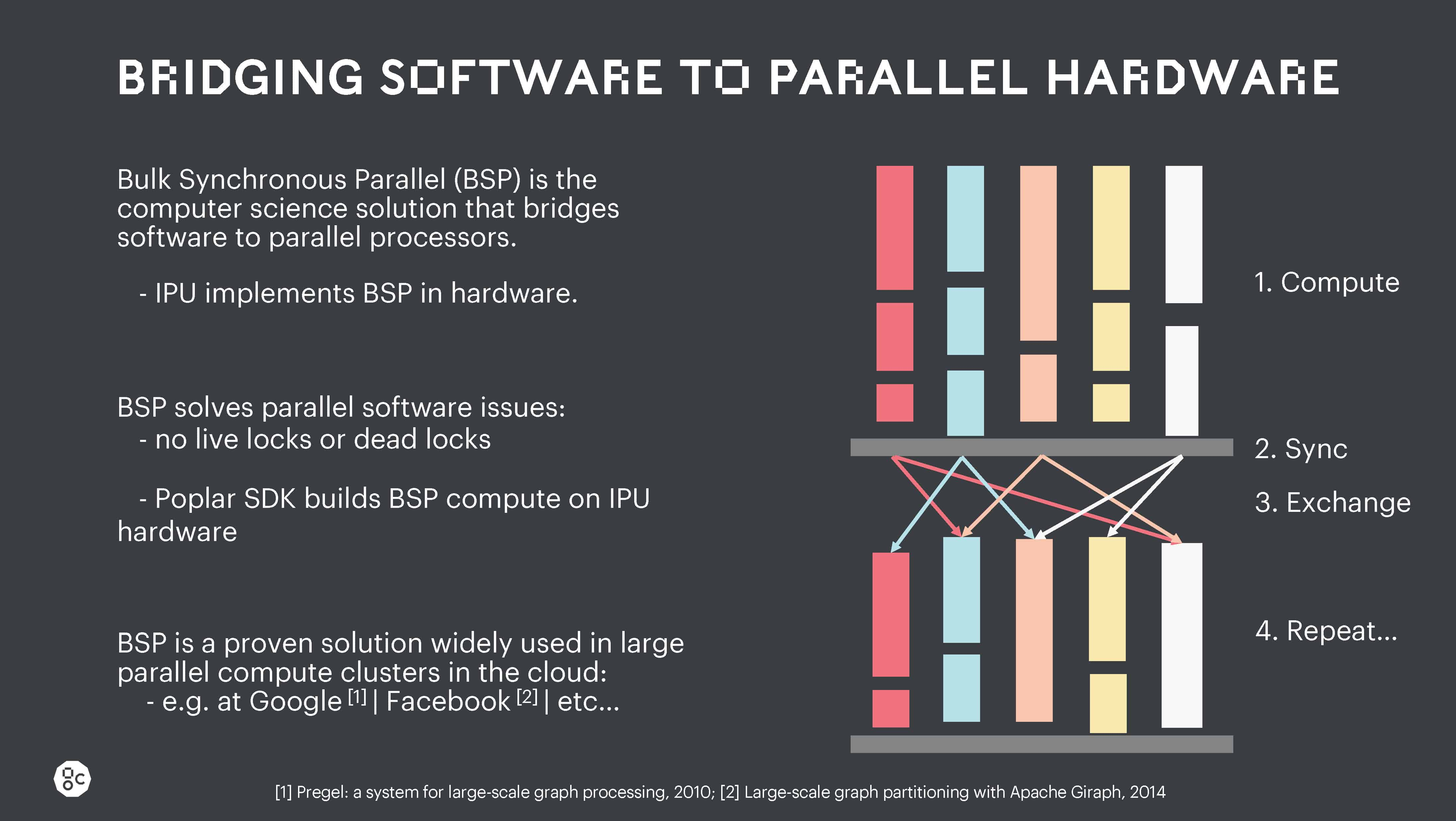 이러한 강력한 병렬 처리 방식은 고도의 병렬 작업 시 경쟁 상태, 라이브 로크(live lock), 데드 로크(dead lock)를 제거합니다. 이러한 수준의 명시적 병렬 실행 제어는 다른 여타 프로세서에 존재하지 않지만, 대규모 스케일아웃 머신 전반에서 대규모 모델을 견고하고 확장 가능하도록 실행하는 데 필수적입니다.
이러한 강력한 병렬 처리 방식은 고도의 병렬 작업 시 경쟁 상태, 라이브 로크(live lock), 데드 로크(dead lock)를 제거합니다. 이러한 수준의 명시적 병렬 실행 제어는 다른 여타 프로세서에 존재하지 않지만, 대규모 스케일아웃 머신 전반에서 대규모 모델을 견고하고 확장 가능하도록 실행하는 데 필수적입니다.
이러한 BSP 실행 외에도 Poplar SDK는 서로 다른 프로세서 코어 간 그리고 서로 다른 독립 병렬 프로그램 간의 모든 통신을 관리합니다. 또한 Poplar SDK는 스트리밍 메모리 액세스를 오케스트레이션하여 연산 뒤에 숨겨진 백그라운드에서 발생하도록 만듭니다. 이렇게 하면 다음에 필요한 데이터 및 코드를 해당 데이터 및 코드가 전체 프로그램 실행 시 필요하기 전에 언제나 사용할 수 있는 상태로 만들 수 있습니다.
이러한 정교한 제어를 통해 전체 IPU-POD128 또는 IPU-POD256 시스템에서 대규모 연산 작업을 오케스트레이션할 수 있습니다. 또한 IPU-POD256 시스템을 서로 연결하여 더 큰 시스템을 구축하는 것도 가능하며, Poplar SDK 도구는 이러한 시스템을 지원할 수 있습니다. 개발자는 다양한 파이프라인 모델 병렬 및 텐서 모델 병렬 방식을 손쉽게 탐색하여 최고의 성능을 달성할 수 있습니다. 모델 훈련 주기의 후반에 필요한 활성화 및 가중치는 스트리밍 메모리로 오프로드한 후 연산 주기 후반에 Poplar가 복원할 수 있습니다. 때로는 활성화의 작은 샘플만 저장한 후, 모델 훈련 시 역방향 패스에서 중간 활성화를 재연산할 수도 있습니다. 이렇게 하면 메모리 대역폭을 절약하고, IPU에서 사용 가능한 매우 높은 수준의 연산을 효율적으로 사용할 수 있습니다. 이러한 트레이드오프를 통해 연산과 대역폭 간의 균형을 맞출 수 있습니다. 일부 모델은 더 적은 연산으로 더 큰 상태를 요구하지만, 더 작은 상태에서 더 큰 연산 활동을 필요로 하는 모델도 있습니다. 이러한 트레이드 오프는 모델 훈련 주기에 따라 달라질 수 있으므로, 연산 및 I/O 대역폭의 균형을 계속해서 높은 수준으로 제어하는 것이 가능합니다.
그래프코어의 Poplar SDK 소프트웨어는 TensorFlow 또는 Pytorch 같은 AI 프레임워크에서 높은 수준의 모델 설명을 가져오며, 이러한 고도로 추상화된 그래프 표현을 낮은 수준의 연산 그래프로 매핑한 후 컴파일하여 IPU 내부 또는 IPU 그룹에서 실행할 수 있습니다.
Poplar SDK 시스템은 연산을 구축할 뿐만 아니라, 각 IPU 프로세서 내부에 있는 IPU 익스체인지 패브릭 전반의 모든 통신과 IPU-POD 시스템 내부의 개별 IPU를 연결하는 IPU-Link 및 IPU-Fabric 간의 통신도 오케스트레이션합니다. 또한 Poplar는 모든 데이터 스토리지를 관리하고 다음 연산 단계를 지원하기 위해 올바른 데이터가 적시에 적절한 위치에 있도록 합니다. 이러한 매우 정교한 접근 방식을 통해 IPU-POD 시스템의 모든 IPU 프로세서에서 대규모 모델을 확장하고 여러 IPU-POD 시스템에 연산을 분산할 수 있습니다.
하지만 Poplar가 생성하는 연산 그래프는 IPU에서 단계적으로 실행할 수 있는 더 작은 하위 그래프로 분할될 수도 있습니다. 연산이 전체 그래프를 통과할 때 하위 그래프 상태는 스트리밍 메모리의 백그라운드 모드에서 안팎으로 이동합니다. 이를 단계적 실행이라고 부릅니다. 아래 그림은 단계적 실행에 사용되는 하위 그래프의 매우 간단한 예로, ResNet-50 모델의 레이어 전반에 대한 별도 단계가 표시되어 있습니다. 이 히트 맵은 각 연산 단계에서 연산 그래프의 실행 부분을 보여 줍니다.
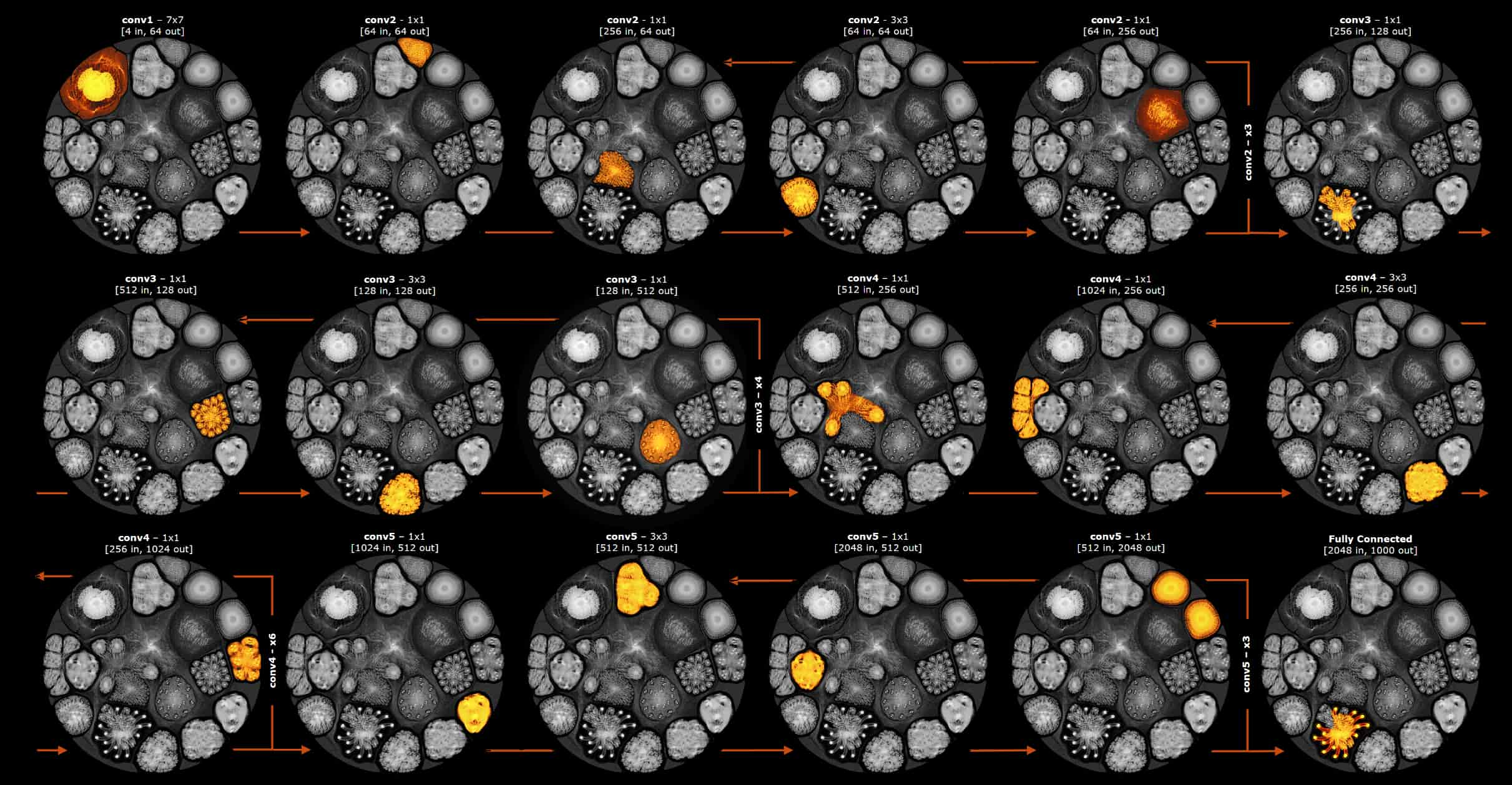
ResNet-50 모델의 레이어 전반에 걸친 단계적 실행의 간단한 예
하위 그래프의 크기를 제어함으로써 개발자는 대규모 인프로세서 메모리를 최대한으로 활용할 수 있습니다. 연결된 메모리에서 데이터를 앞뒤로 끊임없이 뒤섞어야 하는 GPU와 달리, IPU는 프로세서 내부에 대용량 상태를 유지할 수 있습니다. 이러한 접근 방식은 외부 메모리 대역폭 요구 사항을 크게 낮추므로, IPU가 훨씬 더 큰 용량의 DDR-DIMM 모듈을 활용할 수 있습니다. 그래프코어의 CTO인 Simon Knowles는 최근 핫 칩스 컨퍼런스에서의 발표를 통해 IPU의 인프로세서 메모리가 제공하는 이점에 대해 상세히 설명했습니다.
단계적 실행은 대규모 모델을 IPU 프로세서 어레이에 매핑하는 데 추가적인 유연성을 효과적으로 제공합니다.
IPU-POD128 및 IPU-POD256 시스템은 매개변수가 매우 많이 포함된 대규모 모델, 대규모 활성화 상태, 복잡한 옵티마이저 상태를 모두 지원하는 풍부한 리소스 세트를 제공합니다. 개발자는 Poplar SDK의 다양한 소프트웨어 기능을 통해 이러한 강력한 연산 플랫폼에 대규모 모델을 매핑할 수 있습니다.
모델은 빠른 훈련을 지원하기 위해 많은 수의 IPU에 걸쳐 분해될 수 있습니다(아래 다이어그램 참조). p축에 연결된 IPU에 걸쳐 딥러닝 모델의 단계를 파이프라이닝하는 것이 가능합니다. 또한 t축에 연결된 여러 IPU에 걸쳐 모델 텐서를 샤딩할 수도 있습니다. 그런 다음 훈련 데이터를 GPU에서도 일반적으로 사용되는 기존 데이터 병렬 경로로 분할할 수 있습니다. 이는 데이터 복제본 차원인 r축입니다. 데이터 복제본 차원과 관련하여 저희는 스트리밍 메모리를 사용하여 모델 가중치 데이터에 액세스할 수 있습니다. 메모리를 더 효율적으로 사용하기 위해 전체 모델에 대한 가중치를 복제본 간에 분할한 후, 각 실행 단계에 대해서만 복제할 수 있습니다. 이를 복제된 텐서 샤딩(rts)이라고 합니다. 옵티마이저 상태(모멘텀 조건 등)는 기본 가중치보다 액세스 빈도가 낮으므로 가중치(rts')와 다른 수의 복제본에 분산할 수 있습니다. 하위 그래프에 대한 이러한 병렬 실행 외에도 모델 레이어에 걸친 단계적 실행을 구현하여 하위 그래프의 크기를 최적화하고, 대규모 IPU 인프로세서 메모리 내부에 보관되는 하위 그래프 연산에 필요한 모든 상태를 사용하여 높은 수준의 연산을 달성합니다.
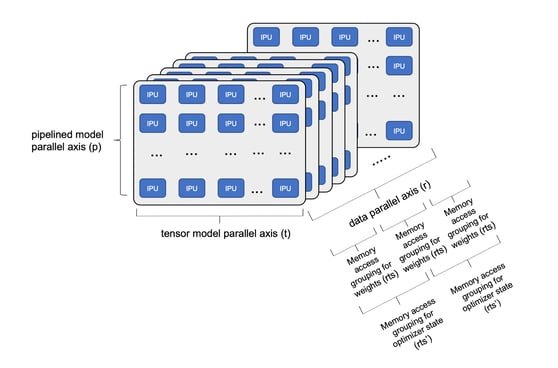
IPU-POD에 걸친 모델 분해
특정 모델 분해의 총 IPU 수는 t*p*r로 계산됩니다. 모델 파이프라이닝, 텐서 샤딩, 데이터 병렬 차원의 수준을 달리하여 IPU-POD128 또는 IPU-POD256 시스템에서 사용 가능한 모든 연산 및 메모리 리소스를 효율적으로 사용하는 대규모 모델을 구축할 수 있습니다.
각 IPU는 1/(t * p)로 지정된 가중치 비율을 사용하지만, 각 IPU 인프로세서 메모리에 저장된 가중치 비율은 복제된 텐서 샤딩을 고려하여 1 / (t * p * rts)로 계산될 수 있습니다. 그러고 나서 단계적 실행을 사용하여 각 하위 그래프에서 사용 가능한 가중치 비율을 최적화하고, IPU 인프로세서 메모리를 최대한 활용하도록 최적화하고, 연산 효율을 극대화할 수 있습니다.
전역 배치 크기는 b * r로 계산되며, 여기서 b는 복제본 배치 크기입니다. 개발자는 적절한 복제본 배치 크기를 선택하여 모델에 맞는 전역 배치 크기를 얻을 수 있습니다.
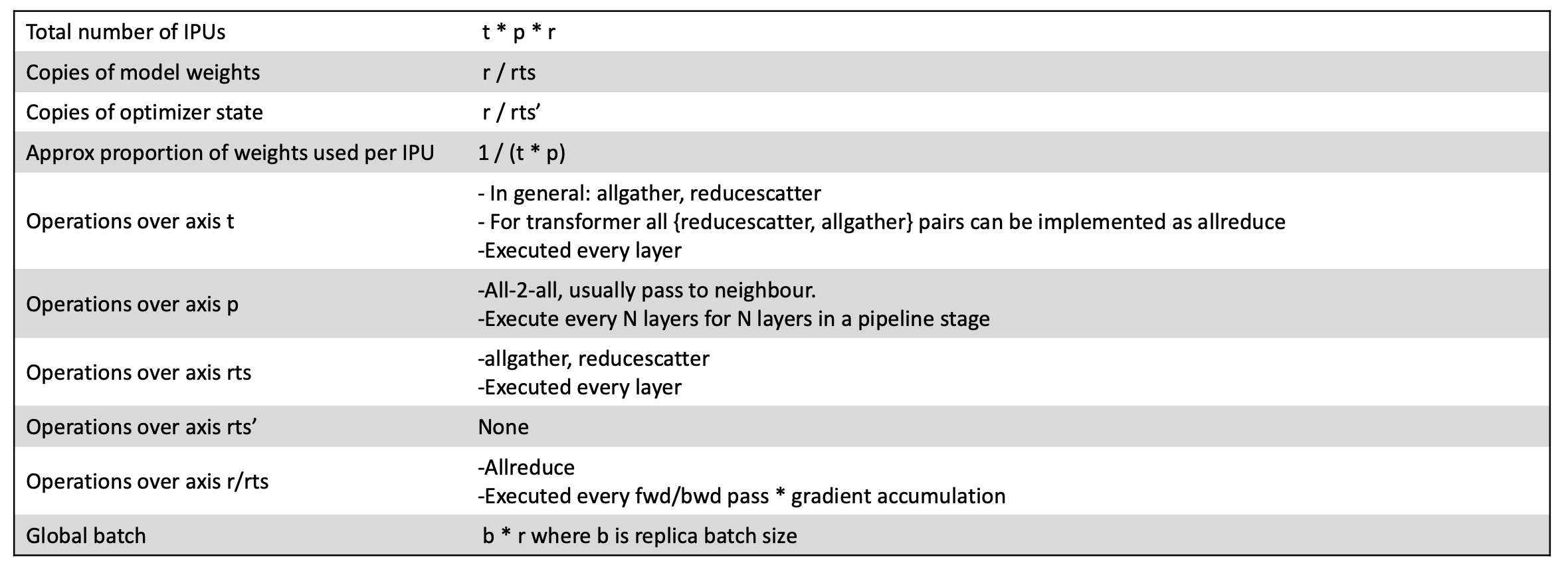 이러한 점을 더 잘 이해하기 위해 아래에서 더 작은 IPU-POD16 시스템에 매핑된 Bert-Large 모델의 간단한 예를 확인할 수 있습니다.
이러한 점을 더 잘 이해하기 위해 아래에서 더 작은 IPU-POD16 시스템에 매핑된 Bert-Large 모델의 간단한 예를 확인할 수 있습니다.
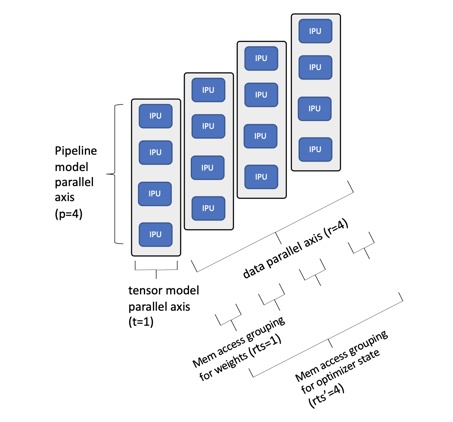
IPU-POD16에 매핑된 BERT-Large 예시
이 예에서는 4개의 IPU 프로세서를 통해 모델을 파이프라이닝하고 텐서를 샤딩하지 않기로 선택했습니다. IPU-POD16 시스템에서 16개의 IPU 프로세서 사용을 극대화하기 위해 데이터 병렬 차원을 4로 선택했습니다. 파이프라인 깊이를 8차원으로 확장하면 모든 옵티마이저 상태를 포함한 전체 모델을 이 단일 IPU-POD16 시스템의 IPU 인프로세서 메모리 내에 포함할 수 있으며, MLPerf 성능 결과에서 입증된 것처럼 동급 최고의 훈련 성능 및 미세 조정 결과를 얻을 수 있습니다.
아래에 나와 있는 좀 더 복잡한 예는 IPU-POD256 시스템에 매핑된 1,750억 개 매개변수가 포함된 GPT-3 NLP 모델입니다.
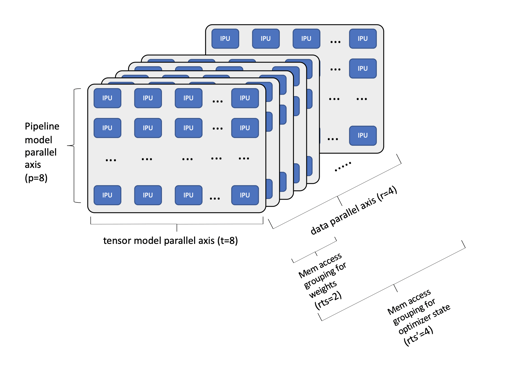
IPU-POD256에 매핑된 1,750억 개 매개변수가 포함된 GPT-3 예시
이 예에서는 단일 IPU-POD256 시스템에 매핑된 훨씬 더 큰 모델을 확인할 수 있습니다. 여기에서는 파이프라인 모델 깊이를 8로 선택하고, 각 파이프라인 단계에서 IPU 8개에 걸쳐 텐서를 샤딩했습니다. 따라서 데이터 병렬 축의 각 데이터 복제본에 대해 총 64개의 IPU가 제공되며, 데이터 병렬 축 너비를 4로 설정하면 시스템에서 256개의 IPU 프로세서를 전부 사용할 수 있습니다. 더 작은 GPT 클래스 모델을 사용하면 IPU 인프로세서 메모리 내부에 모든 가중치를 포함할 수 있지만, 1,750억 개의 매개변수를 사용하면 단계적 실행을 활용하여 대규모 모델을 여러 개의 하위 그래프로 분할합니다. GPT-3 모델의 레이어 96개를 통해 이용 가능한 모든 인프로세서 메모리와 모든 연산 리소스를 여전히 효율적으로 사용할 수 있습니다. 단계적 실행을 사용하여 구현된 더 많은 하위 그래프로 확장하면 수조 개의 매개변수가 포함된 더 큰 모델을 지원할 수 있습니다. 훈련 시간을 더 단축하기 위해 네트워크에 연결된 여러 IPU-POD256 시스템으로 확장할 수도 있습니다.
IPU-POD 시스템이 GPT 및 그 이상을 비롯한 오늘날의 대규모 AI 모델을 손쉽게 지원할 수 있음을 알 수 있습니다. IPU-POD 시스템은 대규모 모델을 지원하도록 확장할 수 있습니다. 하지만 매우 많은 인프로세서 메모리와 극도로 고도화된 병렬 IPU 프로세서를 이용하면 훨씬 더 다양한 차세대 대규모 모델을 탐구할 수 있는 기회가 주어집니다. 희소 모델, GNN(Graph Neural Networks)을 비롯한 흥미로운 연구가 이미 IPU에서 진행되고 있습니다. 그래프코어는 혁신가들이 최첨단 IPU-POD128 및 IPU-POD256 시스템을 활용하여 놀라운 결과를 만들어낼 수 있기를 기대합니다.
공유:


