
Nov 05, 2021 \ Healthcare, Computer Vision, Research
Nov 05, 2021 \ Healthcare, Computer Vision, Research
共有:
疾患の診断の迅速化と早期化、オーダーメード医療、新薬の発見など、医療分野におけるAIは、患者の転帰を劇的に改善し、命を救い、世界中の人々がより健康で長生きできるようにする大きな可能性を秘めています。
進歩は急速に進んでおり、すでに大きな影響をもたらしていますが、その結果、AIモデルの学習に使用される、機密性の高い患者データのプライバシーとセキュリティに関する新たな課題が生まれています。当然のことながら、一般市民や医療関係者、政府レベルにおいて、この問題についての議論が高まっています。また、データ機密性を高めるためのAI技術を向上させる研究が必要であることも明らかです。
先日、スタンフォード大学医学部の研究者らが、機密データを保護するための重要な手法であるディファレンシャルプライバシーの利用において大きな突破口を開きました。このスタンフォード大学のチームはGraphcoreのIPUを使用することで、ディファレンシャルプライバシーを用いたAI学習を10倍以上高速化することに成功したのです。 その結果、計算が難しすぎて普及しないと思われていた技術を、現実的なソリューションに変えることができました。
このチームはGraphcoreと協力して、プライバシーに関わることのない、機密性の高い学習データを使ってこの技術の有用性を実証しました。今後は、新型コロナウイルス感染症の胸部CT画像にこの技術を応用し、世界中の人々の生活に影響し続けているこのウイルスについて新たな知見を得ることを目指しています。
機密性の高い個人データをAIに利用するには様々な課題がありますが、その中でも重要なのはデータ主権を維持することと、個人の特定を防ぐことです。スタンフォード大学の研究では、そのどちらにも応用できる、洗練された技術的なソリューションが発見され、その両方が実現可能であることが証明されています。
世界中の様々な人々を対象とした複数の機関やプロバイダーが保有するデータセットから得られた、大量かつ多様な患者データに基づいて学習されたモデルは、より堅牢で、特定のバイアスがかかりにくく、最終的にはより価値の高いものになります。
一般的な機械学習のアプローチでは、学習のためにデータを集中的に照合する必要があります。患者を識別できる情報を削除してデータを匿名化しようとしても、その情報を第三者の研究機関や組織に提供しなければならないことが大きな問題となっています。実際に、患者データをその入手元である法域に留めることを義務付けるような規制を求める声も高まっています。
それに対して連合学習では、匿名化された患者データを集中管理することなくAIモデルの学習を進められるので、そのような問題の解決につながります。それどころか開発中のモデルを外に出して、その場でデータを学習させるのです。
連合学習は有益な技術ですが、最近の研究では、完全に学習されたモデルからデータを推論し、個人にリンクさせたり、元のデータセットを復元したりすることで匿名の医療情報を再特定できることも明らかになり、プライバシーの脆弱性が指摘されています。
そのため連合学習を利用するには、ディファレンシャルプライバシーの応用も進めていく必要があります。
ディファレンシャルプライバシーとは、誰も連合学習モデルから学習データを推測したり、元のデータセットを復元したりできないような方法で連合学習モデルを学習させることによって、機密データの保護をさらに発展させるものです。
ディファレンシャルプライバシー確率的勾配降下法(DPSGD)では、個々の学習データ項目の勾配をクリッピングしたり歪めたりすることで、匿名化された患者データにノイズが加えられます。このノイズが加わることで、敵対する相手によって、使用された個々の患者データが発見されたり、モデルの学習に使用された元のデータセットが復元されたりする可能性が低くなります。
ディファレンシャルプライバシー確率的勾配降下法(DPSGD)が機密データの保護に役立つことは明らかですが、あまり研究されていない分野であり、GPUやCPUなどの従来のAI演算の形態では計算コストが高すぎるため、これまで大規模データには応用されていませんでした。
スタンフォード大学医学部のコンピュータビジョンを専門とする放射線科の研究者チームはこの分野に着目し、論文「NanoBatch DPSGD:Exploring Differentially Private Learning on ImageNet with Low Batch Sizes on the IPU(NanoBatch DPSGD:IPUを用いた低バッチサイズのImageNetに関するディファレンシャルプライバシー学習の研究)」でその結果を発表しました。
通常、DPSGDは計算処理量が多くなるので、小規模なデータセットに応用され、分析されます。しかしスタンフォード大学のチームは、一般公開されているImageNetデータセットから採取した130万枚の画像を使って、IPUシステムで初めての分析を行うことに成功しました。この論文では、プライベートデータからなる大規模な画像データセットのプロキシとしてImageNetが使用されました。この研究は、ディファレンシャルプライバシーを大規模に展開する上での現在の障害を克服するのに役立つでしょう。
IPUを使った結果の詳細について、もう少しご説明します。
処理を加速させる一般的なアプローチとしては、マイクロバッチを使用することがあります。その場合、データは共同で処理され、個々のサンプルベースの勾配の代わりに共同勾配がクリッピングされ、歪められます。これにより学習が加速されますが、分析によると、結果として得られるモデルの予測品質だけでなく、結果として得られるプライバシー保護メトリクスも低下するので、本質的には目的を達成できません。事実、マイクロバッチサイズを1として(つまり「NanoBatch」で)実験を行うと、最も高い精度が得られます。
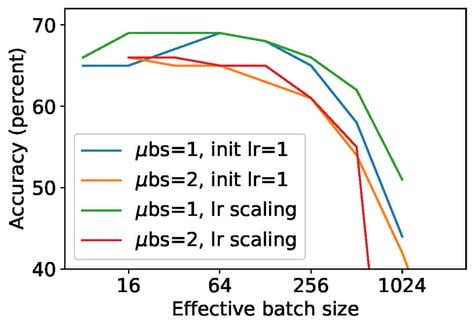
NanoBatchのDPSGDが広く普及していない大きな理由に、ImageNetでNanoBatchのDPSGD Resnet50を実行すると数日かかるほど、GPUのスループットが大幅に低下することがあります。
それとは対照的に、IPUではNanoBatchのDPSGDをとても効率的に実行でき、GPUに比べて8~11倍の速度で結果が得られるため、数日かかる処理が数時間に短縮されます。IPUの場合、IPUのMIMDアーキテクチャときめ細かな並列処理によって処理効率が格段に向上するので、DPSGDに必要な追加演算による計算オーバーヘッドは50~90%を優に超え、10%まで大幅に減少します。
さらに、プライバシー保護やNanoBatchのDPSGDではバッチ正規化の代わりにグループ正規化を使用する必要があり、IPUでは高速に処理できますが、GPUでは大幅に遅くなります。Graphcore Researchは最近、新しい正規化技術であるプロキシ正規化を発表しました。この技術は、バッチ正規化の特性をグループ正規化に応用して、実行効率を高めるものです。この技術については今後、さらなる研究が期待されます。
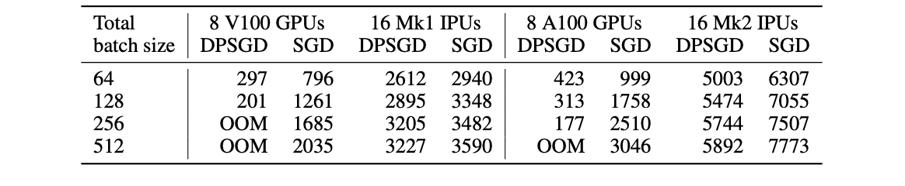
これらの技術により、IPU-POD16システムでImageNetを100エポック学習した場合、ResNet-50の学習時間は約6時間になります(GPUでは数日かかります)。精度は71%で、非プライベートのベースラインを5%下回りました。この結果は、ノイズが加わったことで予想されたことですが、予想以上に良かったとはいえ、今後の研究課題も残ります。
ディファレンシャルプライバシーではイプシロンやデルタの値も報告するのが一般的です。この論文では、デルタが10-6の場合のイプシロンは11.4となっており、良好な範囲と言えます。これをさらに減らすためのアイデアとして、たとえば、学習率をより積極的に予定してエポック数を減らすなどがチームで検討されています。

この研究は、個人の機密データの保護が重要視される医療や金融サービスなど多くの分野における応用において、プライバシー強化の大きなチャンスを切り開くものです。
共有:


