
Jun 28, 2021
Jun 28, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamGraphcore Research explain how their novel technique “Proxy Norm” paves the way for more memory-efficient training of convolutional neural networks. In Graphcore’s new paper, Proxy Norm is found to retain the benefits of batch normalisation while removing the complication of batch dependence that previously led to inefficient execution. Proxy Norm could help AI engineers to ensure efficiency of execution in future as machine learning model sizes continue to grow and datasets keep getting larger.
Normalisation is critical for successfully scaling neural networks to large and deep models. While the scope of normalisation was originally limited to input processing (Lecun et al., 1998), it was taken to another level with the introduction of the technique Batch Normalisation (Ioffe & Szegedy, 2015) that maintains intermediate activations normalised throughout the network.
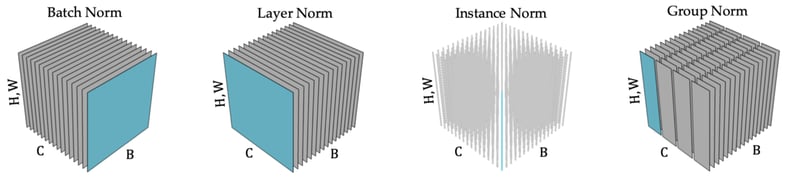
The specific normalisation that Batch Norm imposes is a channel-wise normalisation. This means concretely that Batch Norm normalises intermediate activations by subtracting channel-wise means and dividing by channel-wise standard deviations. Notably, Batch Norm achieves this channel-wise normalisation without altering the neural network's expressivity. This means that the expressivity of batch-normalised networks is the same as the expressivity of unnormalised networks. We will see that these two properties, namely the channel-wise normalisation and the preservation of expressivity, are both beneficial.
Unfortunately, Batch Norm comes with an equally significant complication: batch dependence. Because the channel-wise means and variances over the whole dataset are not easily computable, Batch Norm approximates these statistics by considering the current mini-batch as a proxy for the whole dataset (cf Figure 1). Given the use of mini-batch statistics in Batch Norm’s computation, the output associated by the neural network to a given input depends not only on this input but also on all the other inputs in the mini-batch. In other words, the approximation of full-batch statistics with mini-batch statistics introduces a batch dependence in the neural network’s computation.
Let’s now look in more detail at Batch Norm to understand why channel-wise normalisation and expressivity preservation are beneficial, and why batch dependence is a complication. Following this, we will then introduce Graphcore Research’s novel technique Proxy Norm, as presented in our paper “Proxy-Normalizing Activations to Match Batch Normalization while Removing Batch Dependence”, and show how Proxy Norm can be used to retain these two benefits of Batch Norm while removing batch dependence.
As mentioned above, Batch Norm maintains the intermediate activations channel-wise normalised “close” to the nonlinearity, at each layer. This channel-wise normalisation has two benefits:
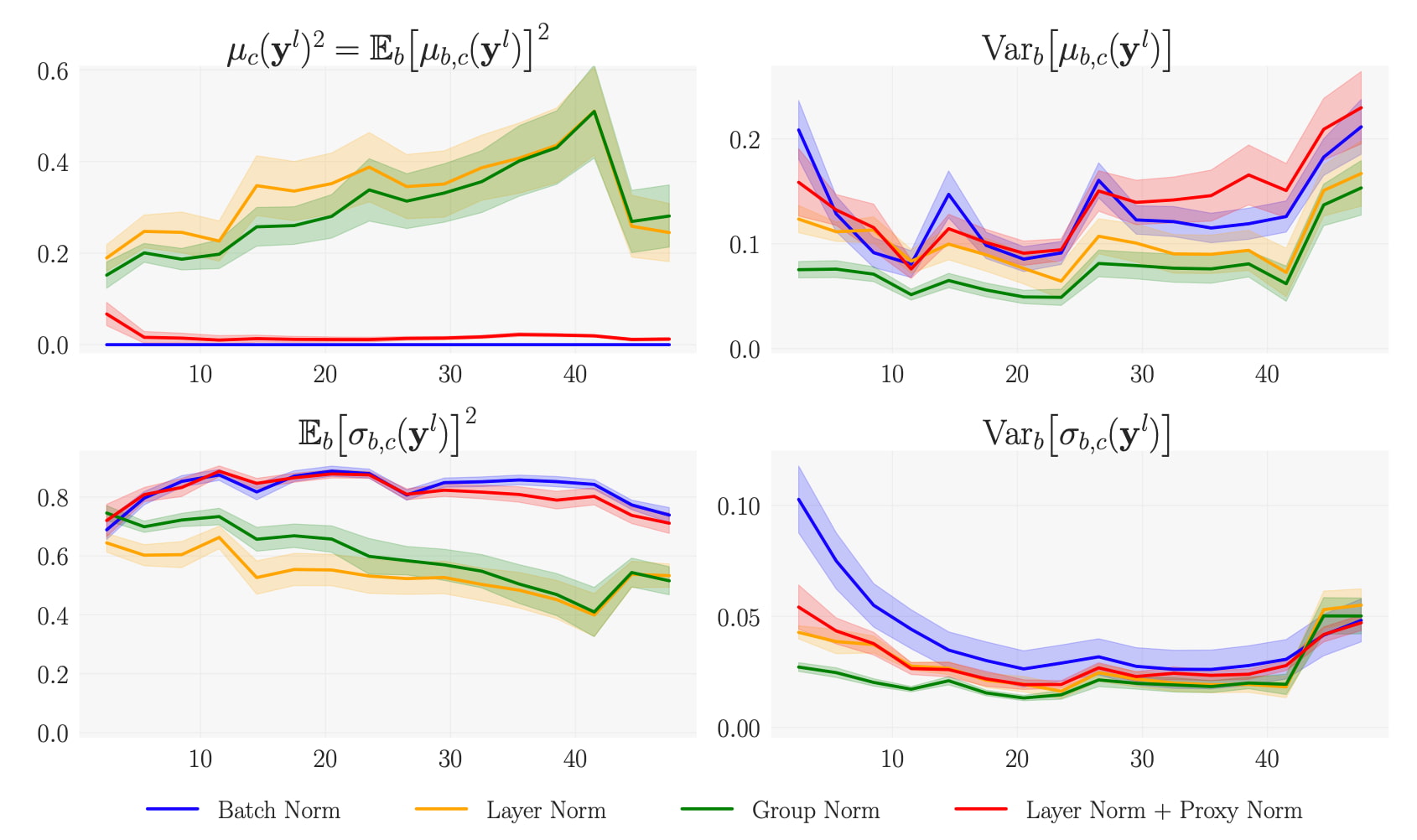
In short, channel-wise normalisation allows the neural network to effectively use its whole capacity. However, this benefit is not retained with the prototypical batch-independent alternatives to Batch Norm (see Figure 1). In fact, while channel-wise normalisation is retained with Instance Norm, it is not retained with Layer Norm or Group Norm. In the top left plot of Figure 2, this translates into non-negligible channel-wise squared means with Layer Norm and Group Norm.
As previously explained, the channel-wise normalisation with Batch Norm does not come at the cost of an alteration of the neural network’s expressivity. This means that any unnormalised network can be equivalently expressed as a batch-normalised network (in the full-batch setting) if Batch Norm's scale and shift parameters are chosen appropriately. Conversely, any batch-normalised network (in the full-batch setting) can be equivalently expressed as an unnormalised network if the convolutional weights and biases are chosen appropriately. In short, Batch Norm amounts to a plain reparameterisation of the neural network’s space of solutions.
This preservation of expressivity is the second benefit of Batch Norm. To appreciate why such preservation of expressivity is beneficial, it is useful to understand why alterations of the expressivity with batch-independent alternatives to Batch Norm are detrimental. In the cases of Instance Norm and Group Norm, a symptom of the alteration of expressivity is the lack of variance of the instance’s mean and standard deviation, as can be seen in the two rightmost subplots of Figure 2. This lack of variance of instance statistics is detrimental for learning as it tends to be incompatible with the expression of high-level concepts in deep layers of the neural network.
The main symptom of Batch Norm’s batch dependence is the presence of a noise stemming from the random choice of the different inputs in each mini-batch. This noise is propagated in between Batch Norm layers and “fuelled” at every Batch Norm layer when full-batch statistics are approximated with mini-batch statistics. The noise is therefore stronger when the mini-batch is smaller. This phenomenon translates into a specific regularisation of Batch Norm (Luo et al., 2019), whose strength depends on the noise amplitude and thus on the mini-batch size.
Unfortunately, this regularisation cannot be easily controlled. When the goal is to decrease the strength of this regularisation, the only way to achieve this is to increase the mini-batch size. Depending on the task and the strength of regularisation needed, Batch Norm then imposes a lower bound on the mini-batch size compatible with optimal performance. When the “compute” mini-batch size is below this lower bound, maintaining optimal performance requires an “expensive” synchronisation of statistics across multiple workers to yield a “normalisation” mini-batch larger than the “compute” mini-batch (Yin et al., 2018). The main issue that can result from batch dependence is therefore an inefficiency of execution.
Resolving this issue would make a real difference when using Graphcore’s IPU, as the extra acceleration and energy savings that the IPU provides are obtained in exchange for tighter memory constraints. Even with alternative accelerators relying less on local memory, this issue could become critical in the future. As datasets get larger and larger, we indeed expect that stronger memory constraints will be imposed by the use of larger and larger models. The use of larger datasets for a given model size also implies that less regularisation will be required, resulting in the requirement of larger and larger “normalisation” mini-batch to guarantee optimal performance when using batch-dependent norms such as Batch Norm.
So how can we retain Batch Norm’s benefits while removing batch dependence?
The two benefits of Batch Norm (i.e. the channel-wise normalisation and the preservation of expressivity) cannot be simultaneously retained with the prototypical batch-independent alternatives to Batch Norm. On the one hand, Layer Norm does a good job at preserving expressivity, but only at the cost of channel-wise denormalisation. On the other hand, Instance Norm guarantees channel-wise normalisation, but only at the cost of a strong alteration of the expressivity. While Group Norm can provide a better trade-off between Layer Norm’s issue and Instance Norm’s issue, it still cannot square the circle. In short, all the prototypical batch-independent alternatives to Batch Norm lead to a degradation of performance.
To resolve this, we need a batch-independent normalisation that can avoid channel-wise denormalisation while simultaneously preserving expressivity. We can make these two requirements more precise by noting that:
These observations have guided our design of the novel technique Proxy Norm. Proxy Norm assimilates the output of the normalisation operation to a Gaussian “proxy” variable that is assumed close to channel-wise normalised. This Gaussian proxy is fed into the same two operations as the real activations, namely the same learnable affine transform and the same activation function. After these two operations, the mean and variance of the proxy are finally used to normalise the real activations themselves. This is depicted in Figure 3.

Proxy Norm enables to preserve expressivity while compensating for the two main sources of channel-wise denormalisation, namely the learnable affine transforms and the activation functions. This leads us to adopt a batch-independent normalisation approach that combines Proxy Norm with Layer Norm, or Group Norm with a small number of groups. As can be seen in Figure 2, this batch-independent normalisation approach preserves channel-wise normalisation while minimising any alteration of the expressivity. With this approach, we retain Batch Norm’s benefits while removing batch dependence.
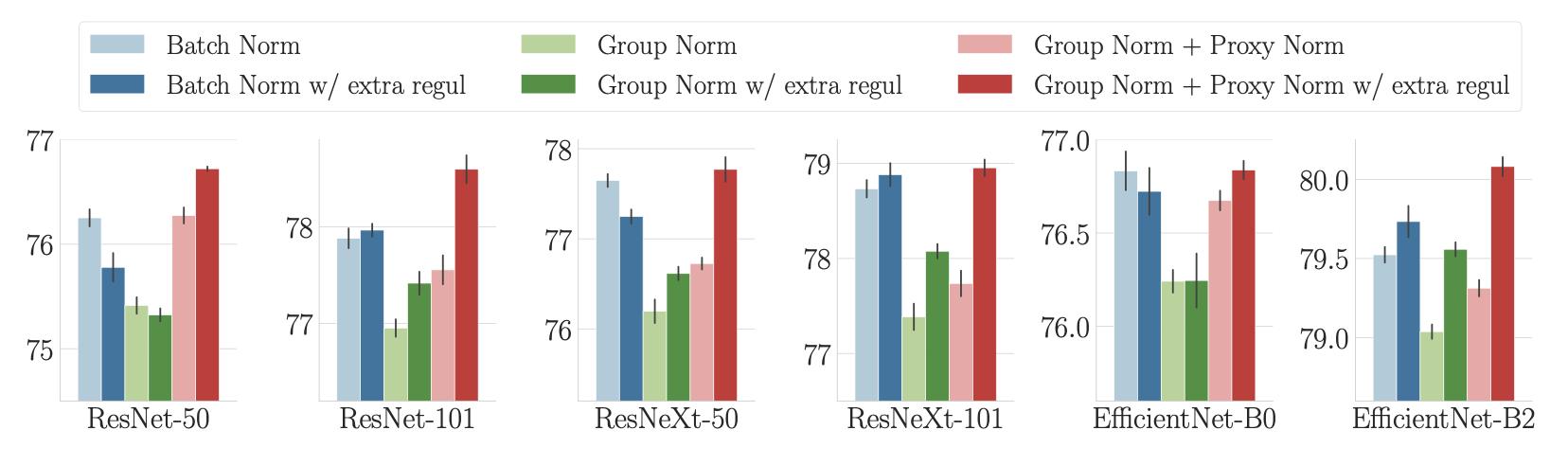
The next question is whether this approach also leads to good performance in practice. Comparing Batch Norm to batch-independent approaches requires specific care to be taken to properly account for the added regularisation stemming from batch dependence with Batch Norm. To “subtract away” this regularisation effect, we therefore include extra regularisation in each of our experiments.
As can be seen in Figure 4, when that specific care is taken, the ImageNet performance of our batch-independent approach consistently matches or exceeds that of Batch Norm across various model types and sizes (note that our variant of EfficientNet is introduced in an associated blog post and paper). This means that our batch-independent approach matches Batch Norm not only in behaviour, but also in performance!
We see as a side product of our analysis that while an efficient normalisation is necessary for good ImageNet performance, it must also come with appropriate regularisation. On even larger datasets, we expect that an efficient normalisation would be sufficient in itself, given that less regularisation would be required (Kolesnikov et al., 2020; Brock et al., 2021).
In this work, we delved into the inner workings of normalisation in convolutional neural networks. We gathered both theoretical and experimental evidence that an efficient normalisation should: (i) maintain channel-wise normalisation and (ii) preserve expressivity. While Batch Norm maintains these two properties, it also introduces the complication of batch dependence.
When investigating the prototypical batch-independent alternatives to Batch Norm, we found that the channel-wise normalisation and the preservation of expressivity are difficult to obtain simultaneously. This led us to design the novel technique Proxy Norm, which preserves expressivity while maintaining channel-wise normalisation. We then adopted a batch-independent normalisation approach based on the combination of Proxy Norm with Layer Norm, or Group Norm with a small number of groups. We found that such an approach consistently matches Batch Norm in both behaviour and performance, while maintaining batch independence at all times.
Our approach paves the way for more memory-efficient training of convolutional neural networks. This memory efficiency gives a significant edge to accelerators such as Graphcore’s IPU that leverage local memory to boost the efficiency of execution. In the long term, we expect that this memory efficiency will be critical even on alternative hardware.
This article was originally published in Towards Data Science.
Read the article in Towards Data Science
Share:


