.png?width=1440&name=Papers%20wide%20(1).png "Papers wide (1)")
Jun 06, 2024
Jun 06, 2024
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamMay is always a eventful time of year for ML researchers, with final ICML paper decisions and ICLR taking place in early May, and NeurIPS submission deadlines closing the month. As ever, arxiv submissions continue to grow!
This month we take a look at three papers exploring new techniques to challenge the mainstream large-scale pretraining setup: transformers trained with next-token prediction optimized with Adam/AdamW.
The first paper, xLSTM, is a long-awaited deep dive into Sepp Hochreiter’s new, improved RNN architecture, nearly 30 years after the original LSTM was published. Drawing inspiration from linear attention, the authors demonstrate scaling comparable to transformers up to 1.3B parameters.
We then take a look at Schedule-Free optimizers from a team at FAIR. The authors propose a new class of optimizers that require no finicky learning rate scheduling. By replacing gradient momentum terms in standard optimizers with parameter averages, the authors show faster convergence than scheduled optimizers on a wide battery of small-scale deep learning tasks.
A further paper from FAIR extends the standard pretraining setup for large language models from next-token to multi-token prediction. This particularly seems to improve performance for larger models and offers a natural choice of model to use for speculative sampling to accelerate inference.
Here’s our summary of this month’s chosen papers:
Authors: Maximilian Beck, Korbinian Pöppel, et al. (NXAI, Johannes Kepler University Linz)
Recurrent neural networksm, based on Long Short-Term Memory units were the backbone of NLP models before the advent of the now-ubiquitous transformer. This work seeks to close the gap between LSTM and transformer in the crucial model-scaling regime of LLMs. They do this by extending the LSTM in two ways to create sLSTM and mLSTM, then incorporating these layers into a deep residual architecture, called xLSTM.
.png?width=1108&height=800&name=POTM%201%20(1).png)
We’ll focus on the mLSTM variant, as the sLSTM variant is omitted from many of the best-performing models in their results. I think the best way to understand the architecture is to stare at a wall of maths for a while:
.png?width=1337&height=619&name=POTM2%20(1).png)
To give an intuition for this, there’s:
Like softmax dot product self-attention, this involves a normalised sum of exponentials; a key difference is that the input to exp depends only on the “source” (key, value), not on the “target” (query). It bears some similarities to linear attention, Mamba and RWKV, permitting a parallel scan over the inputs since time dependency is linear. It retains the RNN’s advantage of summarising the context in a fixed-size representation, 𝐂, for efficient autoregressive inference.
In the xLSTM architecture, this is used in a custom residual block that performs positionwise up projection before the multi-headed mLSTM.
Downstream results for LLMs of up to 1.3B parameters, trained on 300B SlimPajama tokens:
.png?width=1083&height=807&name=POTM3%20(1).png)
(I haven’t been able to confirm if these are zero-shot or few-shot results.) Here, xLSTM[1:0] uses only the mLSTM layer described above, while xLSTM[7:1] includes 7 mLSTM layers per 1 sLSTM layer. These results appear to demonstrate the sufficiency of mLSTM for LLMs. The paper also includes a helpful set of ablations and synthetic tasks.
It’s refreshing to see non-transformer LLMs trained at scale, and that the xLSTM architecture appears competitive with transformers. More research could help us understand the benefits of these alternatives, and whether the scaling properties are robust.
Full paper: xLSTM: Extended Long Short-Term Memory
Authors: Aaron Defazio, Xingyu (Alice) Yang, et al. (FAIR at Meta)
Deep learning practitioners use often use two key hacks to make optimisation of deep neural networks work in practise:
Here the authors propose a principled approach that replaces estimates of first-order gradient moments with an averaged parameter state to adapt commonly used optimisers to avoid the need for either of these hacks with no overhead.
.png?width=1621&height=732&name=POTM4%20(1).png)
We’ll present scheduled and schedule-free AdamW side-by-side, identify key differences, and explain how they are motivated.
Algorithm comparison
Given:
We compute:
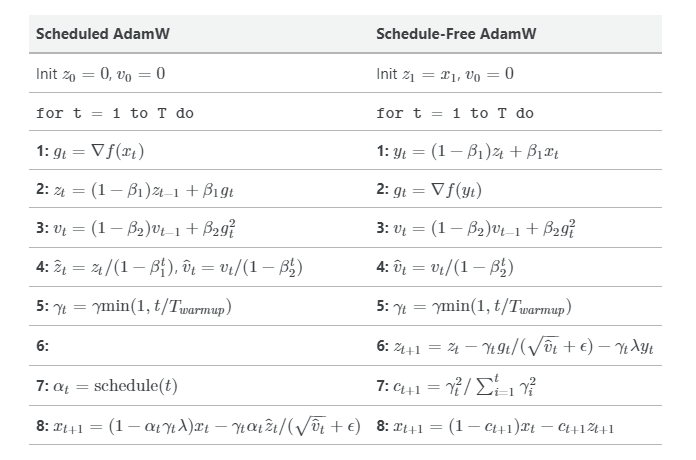
Let’s go through line by line:
Previous work by the same group illustrated a connection between learning rate schedules and Polyak-Ruppert parameter averaging, a theoretically optimal technique for ensuring convergence in stochastic optimisation. Polyak-Ruppert parameter averaging is simple to compute (effectively just line 6-8 of our schedule-free algorithm), but appears to perform worse than cosine decay schedules in practice.
The authors propose combining Polyak-Ruppert averaging with Primal averaging. In Primal averaging, we evaluate gradients at a slow moving average parameter value rather than a fast moving immediate parameter value (standard practice). Likewise, Primal averaging on its own also appears to perform worse in practice as parameters change too slowly.
The combined solution is to effectively try to get the Primal average parameters to move a bit faster, by interpolating them with a Polyak-Ruppert average. This interpolated parameter is our 𝑦𝑡 term computed on Line 1. Given that when 𝛽1=1 is pure Primal averaging, and 𝛽1=0 is pure Polyak-Ruppert averaging, the authors’ recommended 𝛽1=0.9 is still pretty close to Primal averaging.
Two other changes appear to be less theoretically motivated: using 𝑦𝑡 for decaying weights (rather than 𝑥𝑡 or 𝑧𝑡), and Polyak-Ruppert averaging coefficients 𝑐𝑡 that discounts parameter states visited during learning rate warmup. Warmup-free optimisers are a step too far it seems…
The authors test schedule-free optimiser on a battery of different small models of different types (Transformers, RNNs, CNNs, GNNs, Recommenders), different datasets and objective functions, In each case they show comparable convergence as carefully tuned learning rate schedules, with faster training dynamics in many cases.
.png?width=1084&height=1058&name=POTM%206%20(1).png)
As hacks go, learning rate schedules are an enduring one. Given the drastic effect they can have on your model performance when implemented in a training pipeline you omit them at your peril. However, they never seemed particularly well motivated other than for their empirical effect. This looks like a step in the right direction for hack-free optimisation in deep learning.
Full paper: The Road Less Scheduled
Authors: Fabian Gloeckle, et al (FAIR at Meta)
Large language models are usually trained using the next-token prediction loss. The authors propose training the model to predict multiple tokens at a time instead, while still generating a single token at a time at inference as usual. By training models up to 13B parameter in size, they show that this can lead to models with better performance, particularly at coding tasks.
.png?width=1870&height=590&name=POTM%207%20(1).png)
Multi-token prediction: Each output head predicts a token (4-token prediction shown), while only the first head is employed during inference. The training scheme improves performance on MBPP coding task as models get larger.
In order to enable multi-token prediction, the authors propose a simple modification to the standard transformer architecture. The final output embedding is fed into 𝑛 parallel output heads, each a single standard transformer layer. This effectively means that the final transformer layer is replaced by 𝑛 parallel transformer layers. The outputs of each head are then passed through a shared unembedding projection, generating a probability distribution over the whole vocabulary for each head. During training, each head is then trained to predict one of the next 𝑛 tokens for each training example. In order to minimise maximum memory usage during training, the forward/backward passes on each head are performed sequentially (Figure 2).
.png?width=1931&height=937&name=POTM%208%20(1).png)
During inference, all but the output of the first head are discarded, and tokens are generated one-by-one as with the standard transformer architecture. However, multiple-token prediction can be used to speed-up inference using self-speculative decoding, i.e. by using the 𝑛 generated tokens as an initial sequence draft, and validating the sequence with just the next-token head in parallel.
The results of the paper are promising, as they show multi-token prediction can indeed lead to improved performance at scale, particularly at coding tasks, while at the same time providing a more suitable drafting model for speculative-sampling inference. The results hint at the possible benefits of teaching the model to “plan ahead” compared to the standard next-token prediction, and may lead to exciting alternatives to the widely-adopted token-by-token generation.
Full paper: Better & Faster Large Language Models via Multi-token Prediction
Discover more on the Graphcore Research team's Github, and subscribe to the Papers of the Month newsletter.
Share:


