
Jun 28, 2021 \ Computer Vision, Research
Jun 28, 2021 \ Computer Vision, Research
共有:
Graphcore Researchは、コンピュータビジョンモデルEfficientNetのIPU(Intelligence Processing Unit)上でのパフォーマンスを最適化する3つの手法を分析した新しい論文を発表しました。この3つすべての方法を組み合わせることで、学習のスループットが7倍、推論のスループットが3.6倍以上に向上します。
Graphcore Researchの新しい論文「Making EfficientNet More Efficient:Exploring Batch-Independent Normalization, Group Convolutions and Reduced Resolution Training(EfficientNetの効率を高める:バッチに依存しない正規化、グループ畳み込み、および低解像度学習の研究)」では、(理論的に)効率的になるように最適化された最先端のモデルEfficientNetを用いて、IPU上で実用的な効率を高める3つの方法を分析しています。
例えば、IPUで非常に優れたパフォーマンスを発揮するグループ畳み込みを追加することで、理論上の計算コストにはほとんど差がなく、実用的な学習スループットを最大で3倍向上させることができました。
調査した3つの手法を組み合わせることで、IPU上での学習のスループットを最大7倍、推論のスループットを3.6倍に向上させ、同等の検証精度を得ました。
モデル学習の理論的なコストは通常、FLOPで測定されますが、これは簡単に計算でき、使用しているハードウェアとソフトウェアのスタックに依存しません。 このような特徴があるため、魅力的で複雑な測定単位として利用され、より効率的な深層学習モデルを探す上で重要な原動力となっています。
しかし実際には、この理論的な学習コストの測定単位と実際のコストとの間には大きな隔たりがありました。なぜならば、単純なFLOPの数では、計算の構造やデータ移動など、他の多くの重要な要素が考慮されないからです。
最初に、depthwise畳み込み(言い換えれば、グループサイズ1のグループ畳み込み)に関するパフォーマンスを向上させる手法を研究します。EfficientNetは、すべての空間畳み込み演算にdepthwise畳み込みをネイティブに使用します。この畳み込みは、FLOPとパラメータの効率が良いことで知られており、多くの最先端の畳み込みニューラルネットワーク(CNN)に活用されています。しかし実用的な加速性において、いくつか課題があります。
例えば、それぞれの空間カーネルを分離して考えると、一般的にベクトル乗累算ハードウェアによって加速される、結果として生じるドット積演算の長さが制限されます。これは、このハードウェアが常に完全には利用できず、結果として「無駄な」サイクルが発生することを意味します。
また、実行するFLOPの数に対して大量のデータ転送を必要とするdepthwise畳み込みは、演算強度がとても低いので、メモリアクセス速度が重要な要素になります。これによって代替のハードウェアではスループットが制限されることがありますが、非常に高い帯域幅のメモリアクセスを実現するIPUのIn-Processor Memoryアーキテクチャでは、これらのような演算強度の低い演算のパフォーマンスが大幅に向上します。
そして最後に、depthwise畳み込みは、MBConvブロックを形成するために2つの全結合pointwise「投影」畳み込みの間に入れることで、最も効果的になることがわかっています。このようなpointwise畳み込みは、空間depthwise畳み込みを中心にして、アクティベーションの次元性を6の「膨張係数」で増減させます。この膨張によってタスクのパフォーマンスは向上しますが、もう一方でとても大きなアクティベーションテンソルが作られるため、メモリ要件が大きくなり、最終的には使用可能な最大バッチサイズが制限されることがあります。
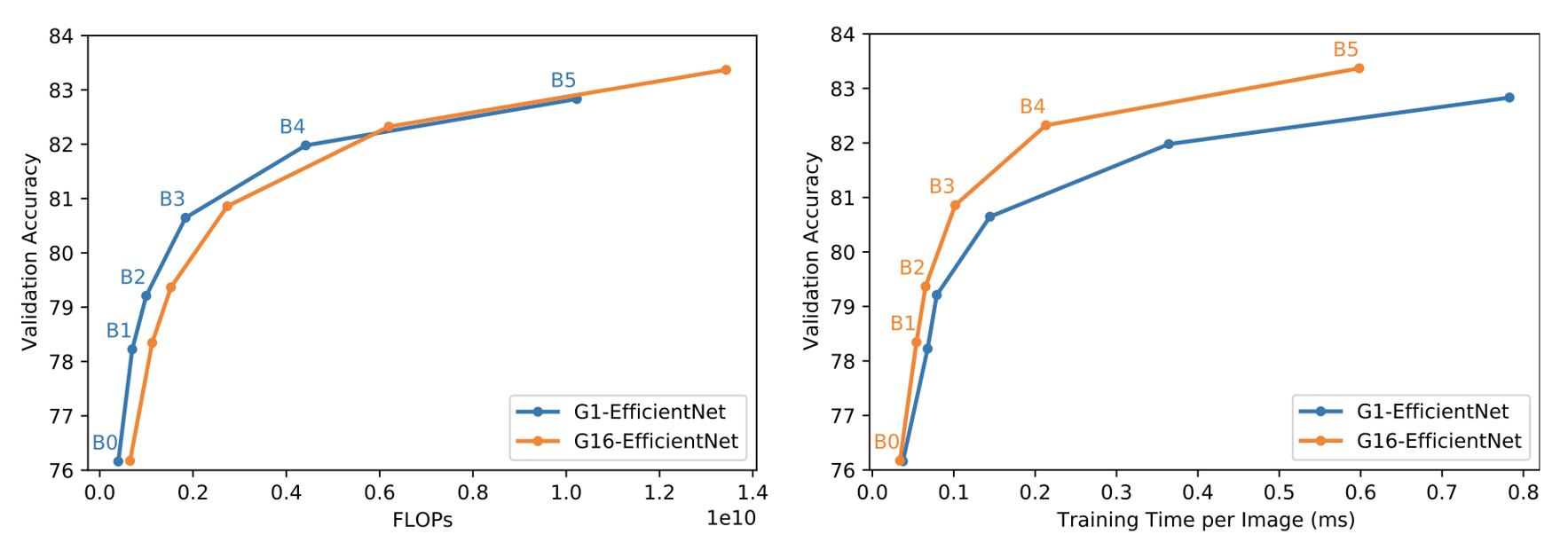
このような3つの問題を解決するために、私たちはMBConvブロックにシンプルで重要な変更を加えました。つまり、畳み込みグループのサイズを1から16に増やすことで、IPUのハードウェア利用率を向上させたのです。そして、FLOPとパラメータの増加を相殺し、メモリの問題に対処するために、膨張比を4に下げます。これによってメモリ効率が良く、計算的にコンパクトなバージョンのEfficientNetが生まれました。私たちはこれをG16-EfficientNetと呼んでいます。
これらの変更は、主にスループットの向上を動機としたものですが、あらゆるモデルサイズにおいて、バニラグループサイズ1(G1-EfficientNet)のベースラインよりも高いImageNet検証精度を達成できることもわかりました。この変更は実用的効率の大幅な向上につながっています。
畳み込み演算や行列乗算演算の出力を正規化することは、最新のCNNには欠かせない要素となっており、この目的のために使用される最も一般的な形式の手法がバッチ正規化です。しかし、Batch Normがもたらすバッチサイズの制約はよく知られた問題であり、バッチに依存しない代替手段のイノベーションが相次いで行われてきました。そのような手法の多くはResNetモデルではうまく機能しますが、EfficientNetではどれもBatch Normと同じパフォーマンスを得られないことがわかっていました。
私たちは、このようなBatch Normに代わるものがない問題に対処するため、最近の論文で紹介された、バッチに依存しない新しい正規化手法のProxy Normを活用しています。この手法は、既にうまく機能しているグループ(および層)正規化の手法をベースにしています。
Group NormとLayer Normには、アクティベーションがチャンネル単位で非正規化されてしまうという問題があります。非正規化はすべての層で強められていくので、深くなるほどこの問題は悪化していきます。この問題はGroup Normのグループのサイズを単純に小さくすることで回避できますが、グループのサイズを小さくすると表現性が変わってしまい、パフォーマンスには不利に働きます。
Proxy Normは、Group NormやLayer Normに従ったアフィン変換とアクティベーション関数という非正規化の主な2つの発生源を打ち消す一方、表現性を維持するという利点があります。具体的には、Group NormやLayer Normの出力をガウス「プロキシ」変数に同化し、そのプロキシ変数に同じアフィン変換と同じアクティベーション関数を適用することで非正規化が打ち消されます。そして、非正規化されたプロキシ変数の統計値を用いて、実際のアクティベーションで予想される分布のシフトを補正します。
Proxy Normを使うと、グループサイズを最大にして(つまりLayer Normを使って)、チャンネル単位の非正規化の問題を発生させることなく表現性を維持できます。
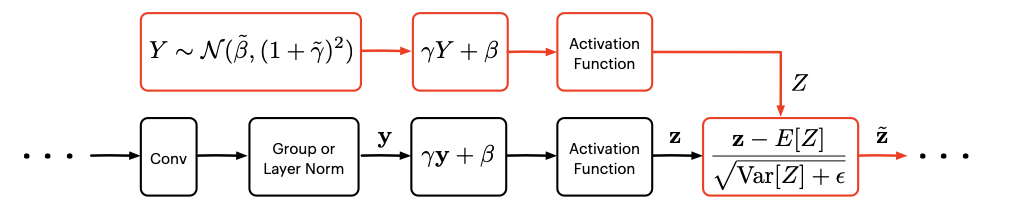
この新しい正規化技術については、関連する論文で詳しく紹介されています。
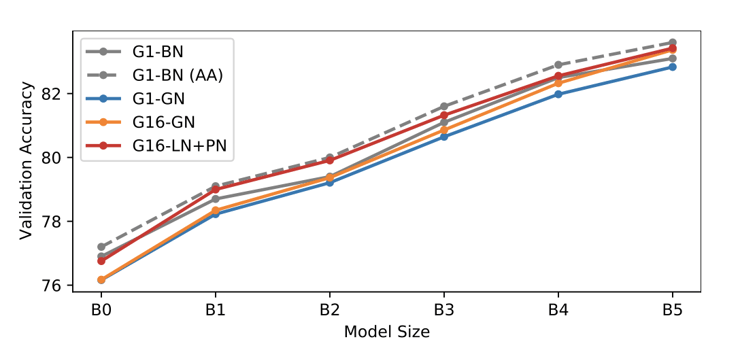
重要なのは、このアプローチ全体においてBatch Normの暗黙の正則化の特性を一切模倣していないことです。このため追加の正則化が必要となりますが、今回の研究ではmixupとcutmixの組み合わせを使用しています。Layer Norm + Proxy Norm(LN+PN)のパフォーマンスを、標準的な前処理とAutoAugment(AA)を用いた2つのBatch Norm(BN)のベースラインと比較したところ、LN+PNはモデルサイズの全範囲において、標準的な前処理を用いたBNのパフォーマンスと同等か、またはそれ以上であることがわかりました。さらにLN+PNは、AAが拡大パラメータを「学習する」という高価なプロセスを必要とするにもかかわらず、AAを用いたBNとほとんど変わらないパフォーマンスになります。
Touvronおよびその他(2020年)は、最初に学習したときよりも大きな画像を使って最後の数層を学習後に微調整することで、大幅な精度向上を達成できることを示しました。この微調整の段階はとても安価であるため、これによって実用的な学習効率の向上が達成できることは明らかでした。そしてこの結果、さらに多くの興味深い研究課題が提起されました。 効率を最大化するためには、どのように学習の解像度を選択すべきなのでしょうか?画像が大きいとテストに時間がかかりますが、これが推論の効率にどのような影響するのでしょうか?
このような疑問を調べるために、「ネイティブ」解像度(本来のEfficientNetで定義されているもの)と約半分の画素数の、2つの異なる解像度で学習を比較しました。その後、微調整を行い、広範囲の画像サイズでテストしました。このような作業によって、学習解像度が効率に与える直接的な影響を調査し、学習と推論において速度と精度の最適な妥協点を示すパレート最適な組み合わせを特定できました。
学習効率を比較する際には、2つのテストシナリオを検討しました。つまり、ネイティブの解像度でテストする場合と、あらゆる解像度で検証精度を最大化するために「最適」な解像度を選択する場合です。
その結果、ネイティブの解像度でテストすると、半分のサイズの画像を使って学習することで、理論的にも実用的にもかなりの効率化が図れることがわかります。また驚くべきことに、特定のモデルサイズでは、半分の解像度で学習し、ネイティブの解像度で微調整する方が、すべてネイティブの解像度で学習、微調整、テストを行うよりも最終的な精度が高くなることもわかりました。この結論は、ImageNetの学習においては、常に学習時よりも高い解像度でテストするべきであることを示唆しています。このことが他の分野にも当てはまるかどうかについては、今後解明したいと思います。
次に、「最適」な画像解像度でテストすると、ネイティブの解像度で学習することで最終的な精度が大幅に向上し、パレートフロントでの間隔が狭くなることがわかります。
しかし、これを実現するためには、「ネイティブ」な学習方式に「最適」なテスト解像度が、半分の学習解像度のケースに対応するものよりもはるかに大きくなってしまうことに注意する必要があります。つまり、推論時により高価になるということです。
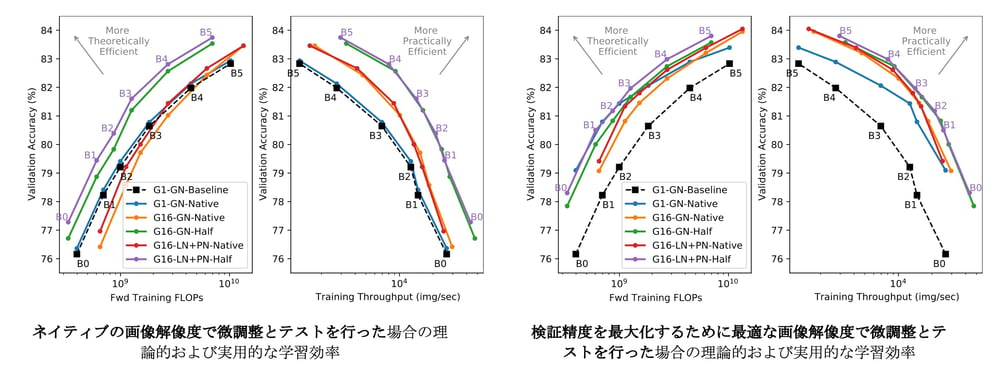
これらの結果から、調査を行った(i)グループ畳み込み[G16(当社)対G1]、(ii)プロキシ正規化アクティベーション[LN+PN(当社)対GN]、および(iii)半分の解像度による学習[半分(当社)対ネイティブ]の3つの改良によって、学習効率が向上したことが良くわかります。なお、ベースラインの結果は微調整しておらず、ネイティブの画像解像度を使用しています。
推論単体の効率を比較すると、半分の解像度で学習することで、全範囲の精度でパレート最適な効率が得られることがわかります。推論においてはFLOPの直接的な優位性が全くないことを踏まえると、これは驚くべき結果です。さらに、半分の解像度の推論効率のパレートフロントに沿ったポイントは、学習のスループットに最適なまま変わりません。
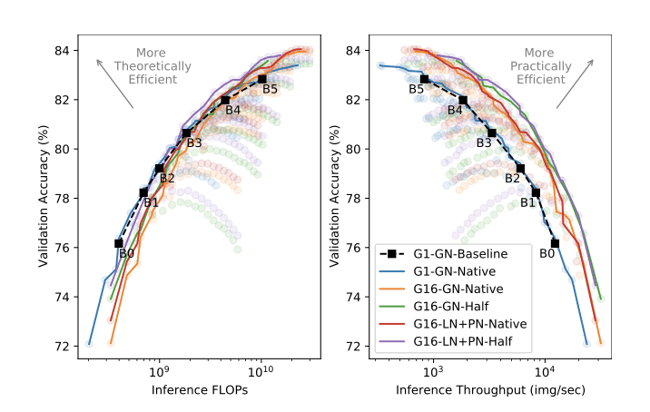
すべての効率の指標において、Proxy Normを用いたモデルはGroup Normを用いたモデルと同等か、またはわずかに良い結果となりました。これは、スループットのコストは最大で10%と小さいにもかかわらず、精度が向上したことが原因です。しかし重要なことは、Proxy Normを用いたモデルでは、パレートフロント全体で使用するパラメータの数が少なく、モデルサイズに対する効率の観点ではProxy Normの利点が際立っていることです。
今回の研究では、学習と推論の全体的な効率を向上させるために、EfficientNetモデルに次のような変更を加えました。
これらすべての手法を組み合わせることで、IPUにおいて実用的な学習効率を最大で7倍、実用的な推論効率を3.6倍に向上させることができました。これらの結果から、EfficientNetは、IPUのようなグループ畳み込みの処理に適したハードウェアを使用した場合に、学習と推論の効率向上を実現できることがわかりました。今後、理論を超えた実用的な実社会への応用が期待されます。
共有:


