
Jul 07, 2020
Jul 07, 2020
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamGraphcore is seeing world-leading performance on state-of-the-art computer vision models like EfficientNet and ResNeXt thanks to a combination of IPU architectural features and Poplar software optimisations and features. Find out more with this deep dive from Graphcore Research.
In 2015, Microsoft’s seminal paper on Residual Networks (ResNets) took the computer vision world by storm. The paper set a new record on the popular image classification benchmark ImageNet, and ResNet soon became the most well-known and widely adopted model in computer vision.
This success can partially be attributed to ResNet’s improved accuracy over alternative models but was also largely driven by its suitability to GPUs. As they predominantly use large dense convolutions, ResNets are a very good fit for GPUs’ SIMT architecture. Despite the positive reception of Microsoft’s paper, however, this turned out to be one of the last times large dense convolutions were exclusively used in a state-of-the-art CNN.
In recent years, there has been a significant move to group and depthwise convolutions in computer vision applications. Out of the top 50 published results on ImageNet, 42 use group or depthwise convolutions in some form. However, these operations do not naturally map well to GPUs and this has limited their uptake in practical training applications. By building our IPU hardware from the bottom up for AI applications, Graphcore has been able to overcome some fundamental bottlenecks in operations like these. This has led to world-leading performance on state-of-the-art image classification models like EfficientNet.
But what are group and depthwise convolutions? How do they improve performance? And how can they be accelerated efficiently in hardware?
How Group Convolutions Impact Performance
In a normal dense convolution, each input feature has connections to all of the output features. Group convolutions sparsify this operation by splitting the features into equal groups and performing independent convolutions on each of them. This means that there are only connections within each group, vastly reducing the total number of weights and the number of floating-point operations (FLOPs) required. When the size of these groups is reduced to one, this is commonly referred to as a depthwise convolution, where each feature is processed independently.
Reducing the complexity of a convolution in this way does not, in itself, produce a better representation. However, when applied spatially (i.e. kernel size larger than 1x1) and paired with a pointwise mapping (1x1 kernel), it forms a depthwise/group separable convolution. This results in a building block that is highly efficient, both computationally and statistically, driven by the factorisation of spatial and feature-wise transformations.
This innovation has allowed networks to be designed with much higher accuracy and/or much lower cost in FLOPs or parameters. For example, by adding group convolutions to ResNet-50, a 40% reduction in FLOPs and parameters can be achieved without any loss in accuracy. Alternatively, by adding group convolutions and increasing the network width to match the ResNet-50 parameter count, ResNeXt-50 achieved a remarkable 1.7% improvement in top-1 accuracy on ImageNet.
Neural network design has recently been dominated by the use of Neural Architecture Search (NAS). This automated technique seeks out the best performing model within a specified design space, typically with some constraints on cost such as the number of FLOPs allowed. The fact that group and depthwise convolutions feature in all of the NAS models in the top 100 best performing ImageNet results is highly significant, as NAS methods typically directly compare the effectiveness of these convolutions against the fully dense versions.
Accelerating Group Convolutions in Hardware
These breakthroughs have had a significant impact on the practical application of efficient inference as they have enabled networks with much higher accuracy to be designed even under tight power constraints. However, in high performance training applications these models have struggled to gain traction. This is primarily because group/depthwise convolutions perform poorly on GPUs.
A key issue with deployment on GPU is that while there is much less to compute, the amount of data that needs to be transferred (dominated by input and output activations) is not substantially lower. This significantly reduces the ratio of FLOPs to data transfer, referred to as the arithmetic intensity. Arithmetic intensity can also be thought of as a measure of the number of times data can be reused in compute. Throughput is therefore highly affected by limited memory bandwidth. This data-transfer bottleneck is very difficult to overcome for conventional accelerators such as GPUs or TPUs, because the weights and activations are stored in off-chip DRAM and are comparatively slow to access. IPUs were designed to overcome this fundamental problem by keeping all of the weights and activations on chip which allows them to be accessed at 90 TB/s per card, which is approximately 100x the memory access bandwidth of off-chip DRAM. This means that the multipliers can be effectively utilised even when the arithmetic intensity is low.
IPUs also benefit from a large degree of flexibility in their compute structure. The IPU has 1216 totally independent processor cores, each with 6 threads, which allow it to run 7296 independent, concurrent instructions at once. Thanks to its architecture, the IPU can better exploit the natural parallelism in modern neural networks, even when operations cannot be structured into large matrix multiplications. This is particularly relevant for group convolutions, as the size of dot products involved decreases with the group size. GPUs naturally perform better with large structured vector operations, which makes processing group convolutions a difficult task for GPUs in terms of compute.
IPU Performance on Group Convolutions
IPUs efficiently process the full range of group convolution sizes thanks to these design choices, resulting in significant performance advantages. IPU processors are already being used to drive a variety of innovative applications of group convolutions, including medical imaging and image search.
Group Convolution Microbenchmarks
Looking at the performance of group convolutions in isolation gives some useful insight into how these architectural decisions influence performance. Importantly, we see that as the group size decreases, and consequently the total number of operations reduces, the IPU performance increases significantly. This shows that the IPU can maintain a similar rate of FLOPs as it is not bottlenecked by data movement. This leads to a throughput improvement over GPUs of more than 4x in the critical small group sizes used in practice.
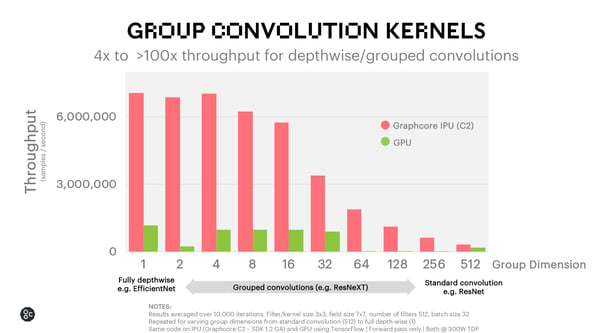
ResNeXt Training and Inference
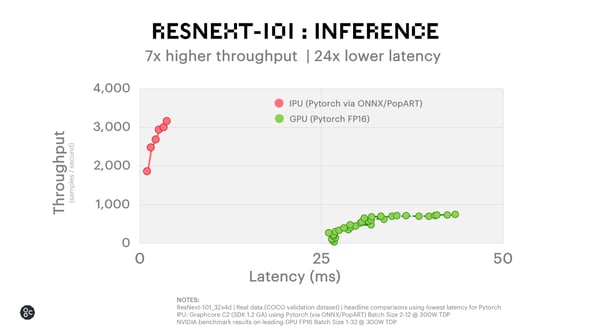
When looking at full applications, the impact of these low-level performance improvements is clear. While for a GPU-friendly network such as ResNet-50 we can achieve 4.7x higher inference throughput at 2.2x lower latency, for a group convolution-centric networks like ResNeXt-101 this can jump to 7x higher throughput with 24x lower latency.
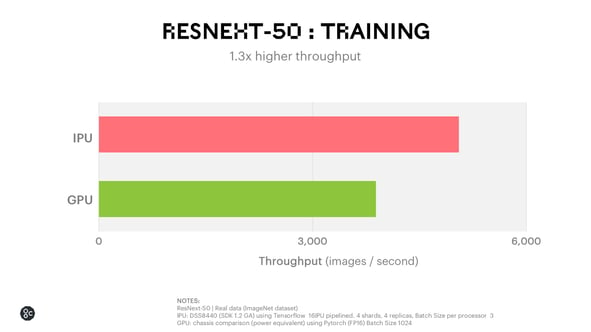
Even when a large batch is used during training to help offset GPU difficulties with low arithmetic efficiency, IPUs are still 30% faster.
EfficientNet Training and Inference
These performance improvements become even greater when looking at models that use depthwise convolutions such as the EfficientNet family that was designed using NAS. They achieve 76.8% - 85.4% top-1 accuracy on ImageNet depending on the size of model and augmentation method used. If training is then performed with extra non-labelled data, while allowing extra tuning, the top-1 accuracy can be pushed as high as 88.5% - the current state of the art.
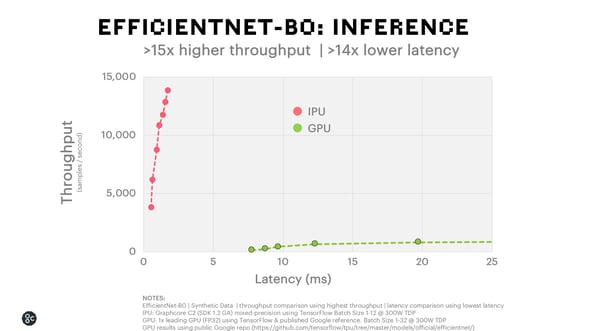
When running these models on the IPU, we can achieve 15x higher throughput and 14x lower latency for inference with nearly 7x higher training throughput. We can further improve on this performance by making a small modification to the model. By increasing the size of the groups in the spatial convolutions from 1 to 16 and reducing their width to compensate for the extra parameters, we achieved the same final accuracy but with nearly 40% higher throughput. However, when we ran this model on a GPU, the throughput was significantly reduced.
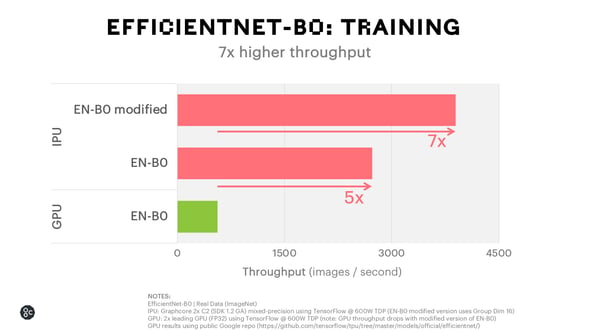
The field of computer vision is on a clear trajectory to favouring group and depthwise spatial convolutions over plain dense convolutions due to their increased accuracy and efficiency. In the past, poor performance of GPUs, due to fundamental hardware constraints, has held back innovation in this area. Graphcore’s IPU has a profoundly different architecture which is centred around massive parallelism and extensive on-chip memory. Its unique design allows the IPU to provide world-leading performance on the latest models, whilst also paving the way for the models of the future.
Share:


