
Dec 01, 2021 \ Machine Learning, IPU-POD, Benchmarks
Dec 01, 2021 \ Machine Learning, IPU-POD, Benchmarks
공유:
그래프코어가 MLPerf에 제출한 최신 자료에서 두 가지 사실을 명확하게 알 수 있습니다. 그래프코어의 IPU 시스템 규모와 효율성이 향상되고 있으며, 소프트웨어 성숙도가 높아지면서 IPU 시스템의 속도와 사용 편의성이 개선되고 있다는 것입니다.
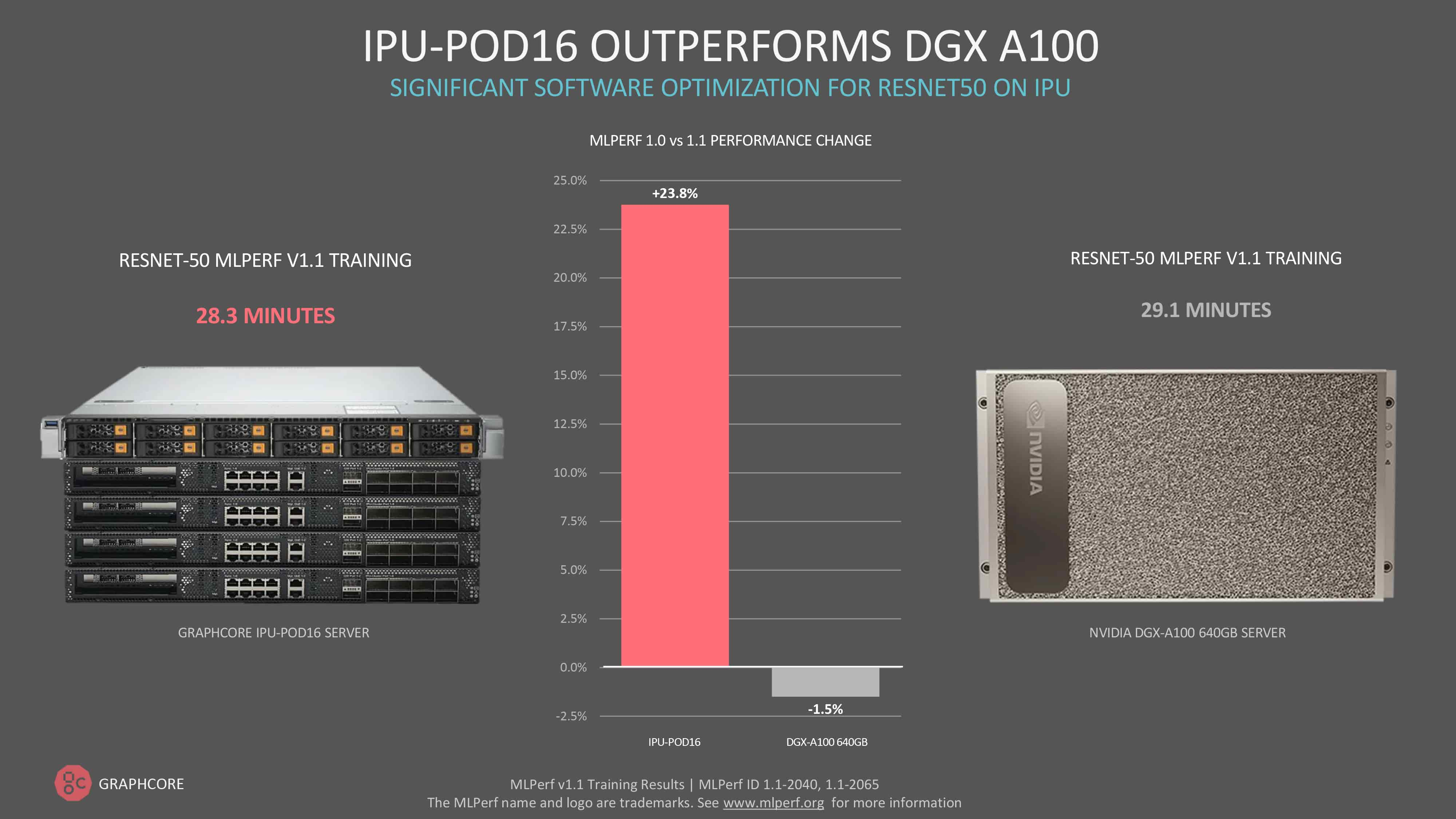
소프트웨어 최적화를 통해 계속해서 상당한 성능 향상을 제공하고 있으며, 현재 그래프코어의 IPU-POD16은 컴퓨터 비전 모델 ResNet-50에 대한 훈련에서 Nvidia의 DGX A100을 능가합니다.
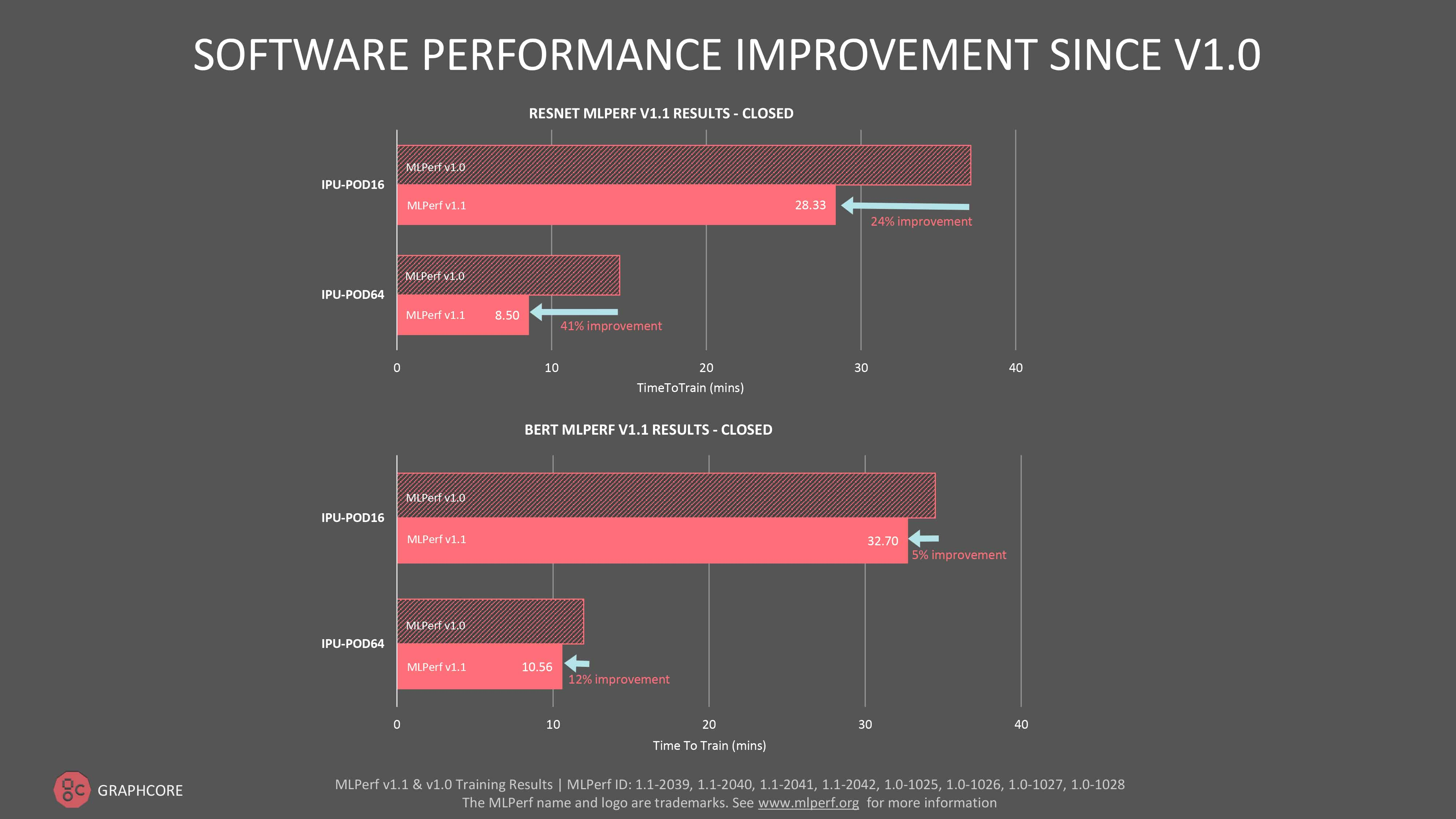
ResNet-50에 대한 훈련은 IPU-POD16에서 28.3분이 걸린 반면, DGX A100에서는 29.1분이 소요되었습니다. 이는 소프트웨어를 통한 첫 번째 제출 이후 성능이 24% 향상되었음을 보여 줍니다. ResNet-50이 전통적으로 GPU의 대표 모델이었다는 점을 감안하면 이번 결과는 매우 중요한 이정표라고 할 수 있습니다.
IPU-POD64의 ResNet-50에 대한 소프트웨어 기반 성능 향상은 41%로 훨씬 더 높았습니다.
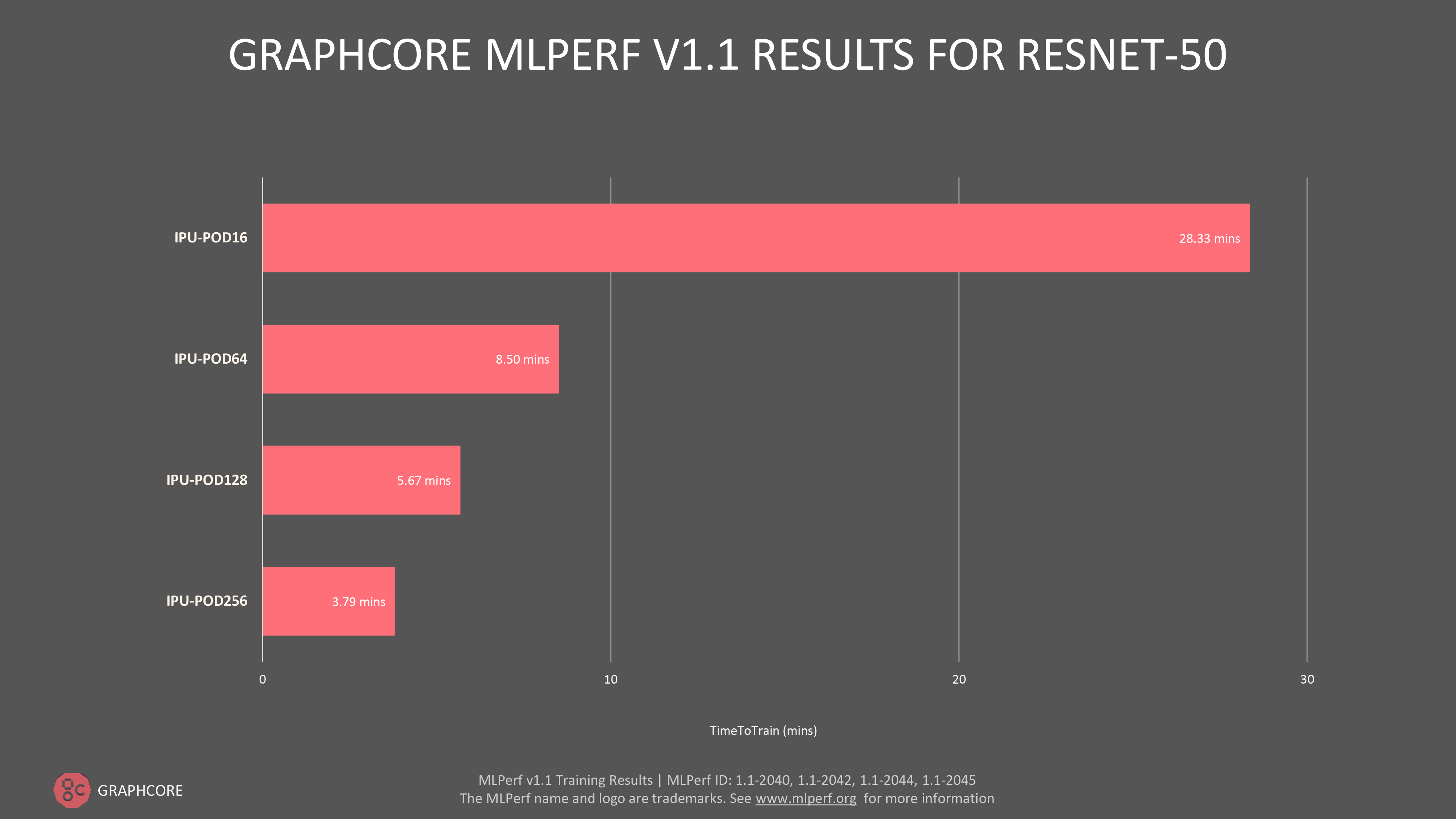
또한 최근 발표된 IPU-POD128 및 IPU-POD256 스케일 아웃 시스템에 대한 결과도 나타났습니다. 이를 통해 그래프코어는 MLPerf의 '이용 가능' 카테고리에 바로 진입하며 뛰어난 성능을 대규모로 제공하기 위한 노력을 인정받았습니다.
그래프코어의 대형 플래그십 시스템의 경우, ResNet-50에서 훈련하는 데 걸린 시간은 IPU-POD128에서 5.67분, IPU-POD256에서 3.79분이었습니다.
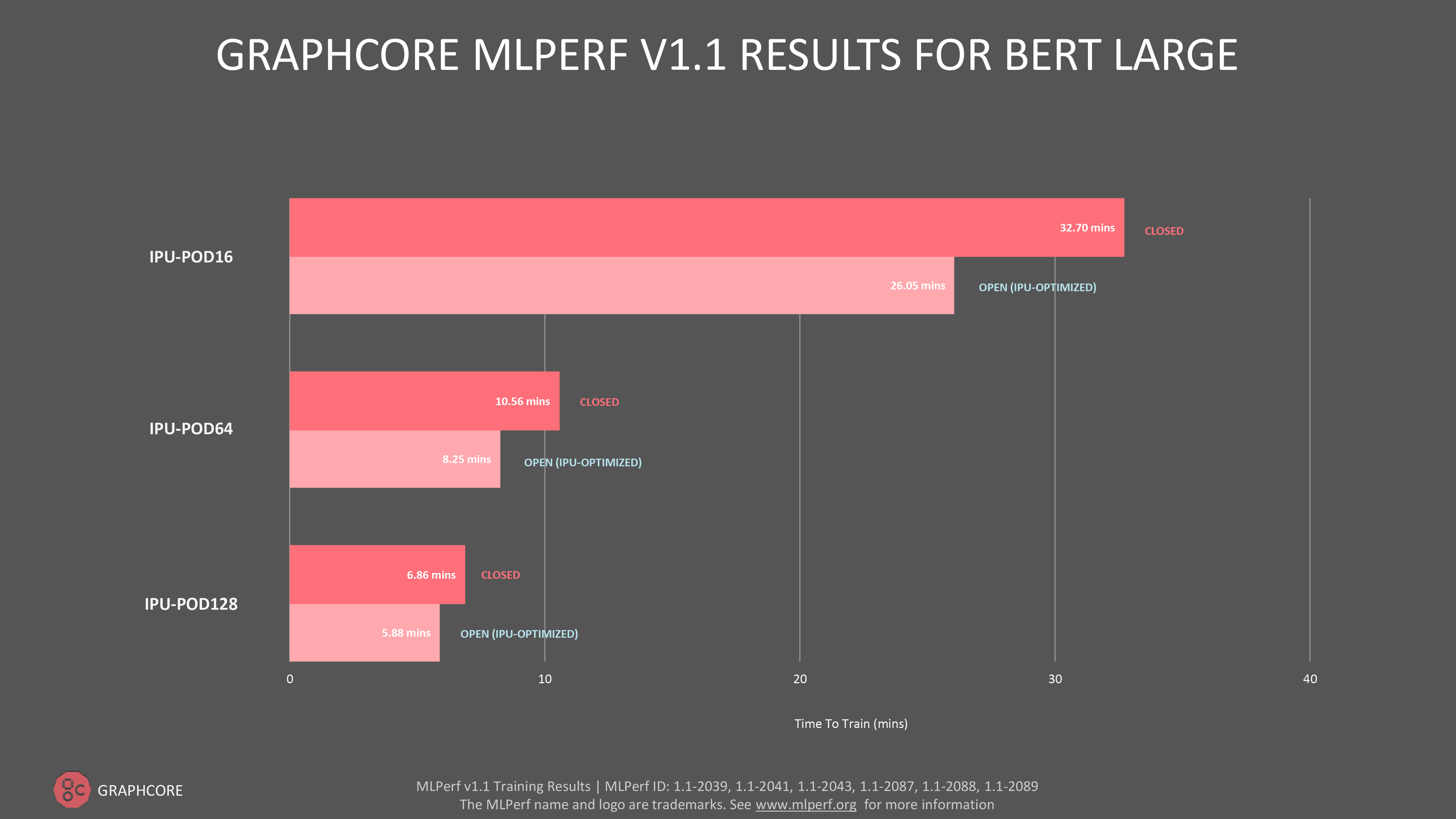
자연어 처리(NLP) 모델 BERT의 경우, 개방형 부문과 폐쇄형 부문 모두에서 IPU-POD16, IPU-POD64 및 IPU-POD128에 대한 데이터를 제출했습니다. 특히 개방형 부문 제출에서 새로운 IPU-POD128의 훈련 시간은 5.78분으로 놀라운 성능을 보여 주었습니다.
전반적으로 지난 MLPerf 훈련 라운드 대비 BERT 성능이 IPU-POD16에서 5%, IPU-POD64에서 12% 향상되는 결과가 나타났습니다.
MLPerf의 폐쇄 부문의 경우, 제출자들은 하이퍼 파라미터 상태와 훈련 시기 지정을 비롯하여 똑같은 모델 구현과 옵티마이저 방식을 사용해야 합니다.
개방형 부문은 폐쇄형 부문과 똑같은 모델 정확도와 품질 달성을 요구하되 보다 유연한 모델 구현을 허용하여 혁신을 촉진합니다.
개방형 부문에서 BERT 훈련에 대한 결과를 공개함으로써 그래프코어는 고객들이 현실 세계에서 최적화를 자연스럽게 활용할 때 얻을 수 있는 성능을 보여 줄 수 있습니다.
그래프코어는 MLPerf와 해당 주관사인 MLCommons를 적극 지지합니다. 그래프코어는 다른 회사에서 제공하는 AI 컴퓨팅 시스템의 기능과 소프트웨어 스택의 성숙도를 고객이 독립적으로 평가하는 데 제3자 검증이 중요한 역할을 한다는 점을 이해합니다.
고객은 ResNet, BERT 같은 모델을 프로덕션에 지속적으로 사용하는 동시에, 혁신적인 신규 모델을 탐색하고 그래프코어의 대형 플래그십 시스템을 통해 머신 인텔리전스를 대규모로 제공하려 하고 있습니다.
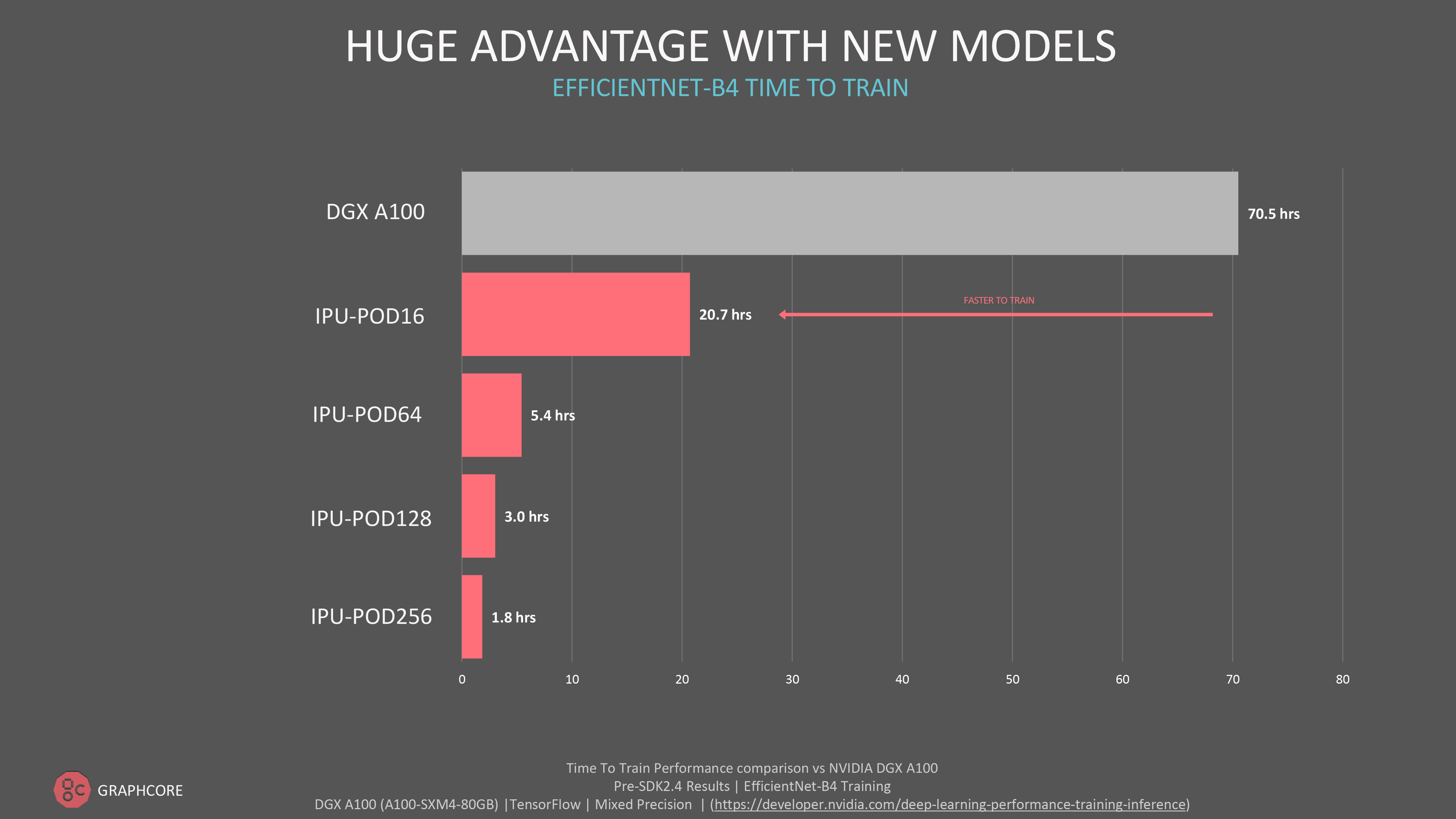
혁신적인 컴퓨터 비전 EfficientNet B4는 MLPerf 제출에 포함되지 않았지만, 그래프코어의 플래그십 IPU-POD256에서 1.8시간이라는 훈련 시간을 기록하며 대규모의 실질적 성능 향상을 보여 주었습니다.
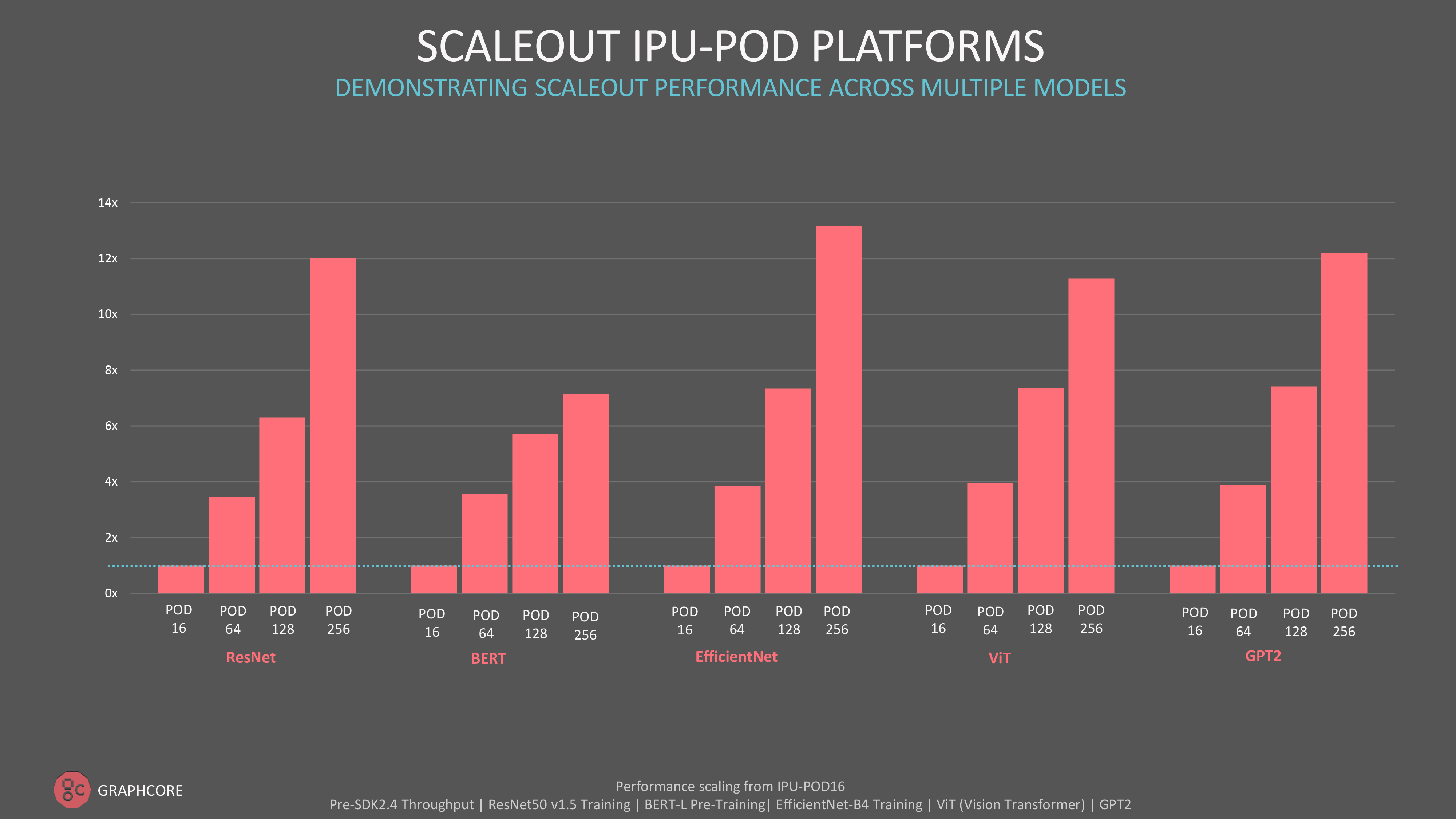
절대적인 처리 성능과 대형 IPU-POD 시스템으로의 스케일 아웃에 관심이 있는 고객들을 위해, 그래프코어는 MLPerf 외부에서도 자연어 처리를 위한 GPT 클래스 모델, 컴퓨터 비전을 위한 ViT(Vision Transformer) 모델을 포함한 다양한 모델에 걸쳐 인상적인 결과를 보여 주었습니다.
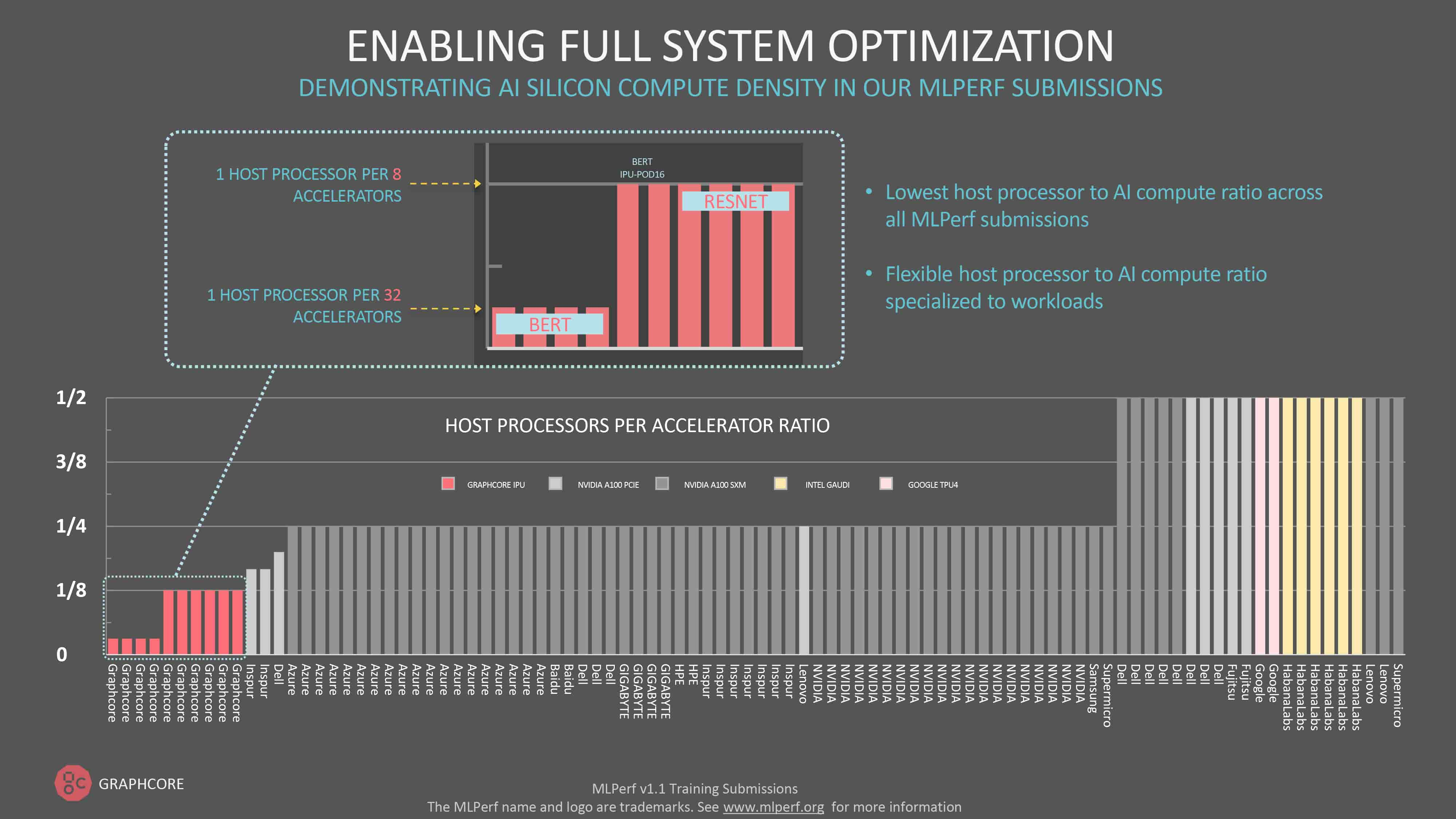
이번 또는 여타 MLPerf 라운드의 원시 데이터를 확인하는 사람들은 각 제조사의 시스템과 연결된 엄청난 수의 호스트 프로세서에 놀라게 될 것입니다. 일부 참여자는 두 개의 AI 프로세서마다 하나의 CPU를 지정합니다.
그래프코어는 가장 낮은 호스트 프로세서 대 IPU 비율을 일관적으로 유지합니다.
다른 시스템들과 달리, IPU는 데이터 이동에만 호스트 서버를 사용하며 런타임 시점에 호스트 서버가 코드를 발송할 필요가 없습니다. 따라서 IPU 시스템에 필요한 호스트 서버 수가 적어, 더욱 유연하고 효율적인 스케일 아웃 시스템이라는 결과로 이어집니다.
BERT-Large와 같은 자연어 처리 모델의 경우, IPU-POD64는 하나의 듀얼 CPU 호스트 서버만 필요로 합니다. ResNet-50은 이미지 사전 처리를 위해 더 많은 호스트 프로세서 지원이 필요하므로 IPU-POD64당 4개의 듀얼 코어 서버가 지정됩니다. 1:8 비율은 여전히 다른 모든 MLPerf 참여자보다 낮습니다.
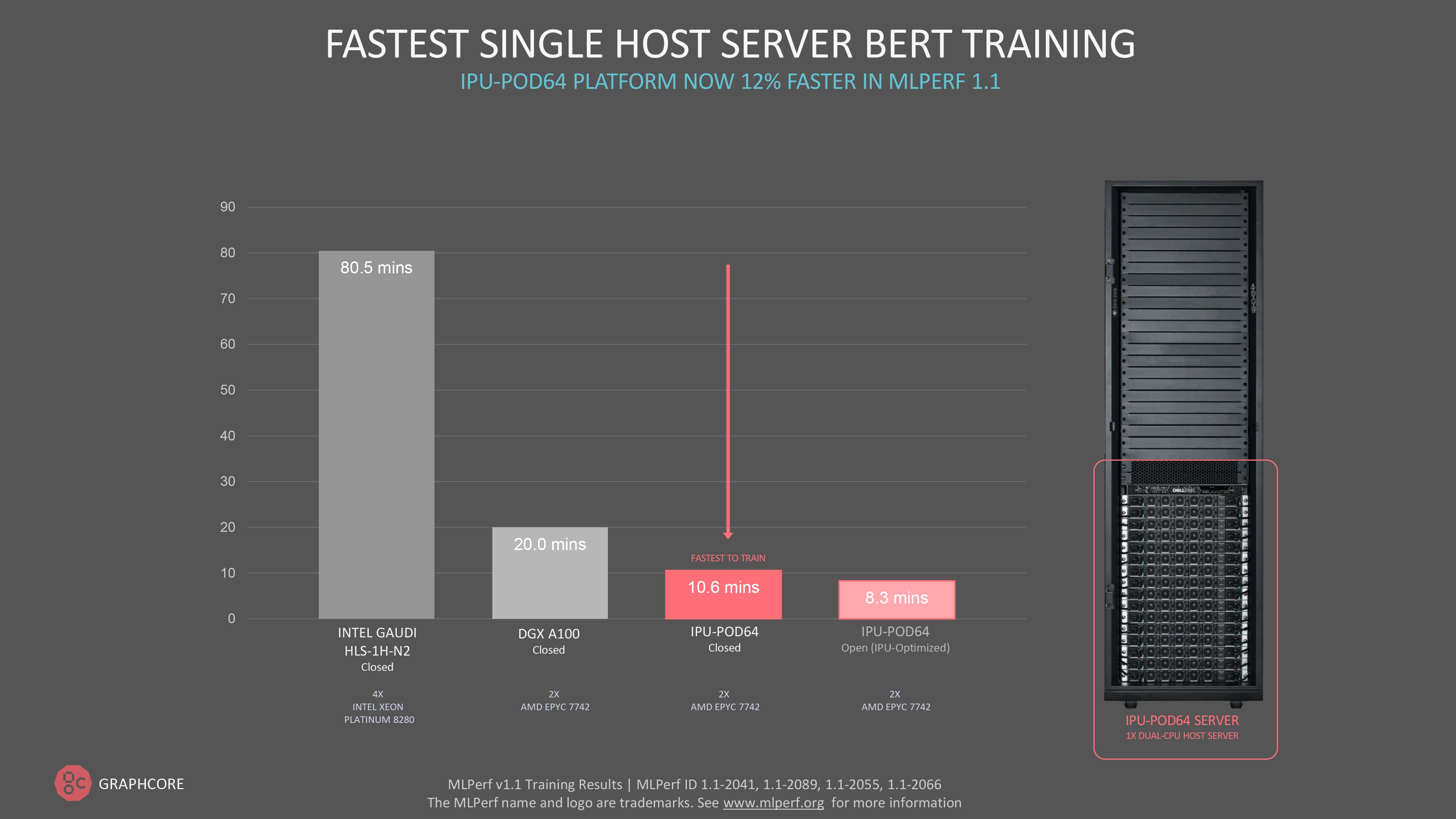
실제로 이번 MLPerf 1.1 훈련 라운드에서 그래프코어는 BERT에 대한 가장 빠른 단일 서버 훈련 시간인 10.6분을 기록했습니다.
그래프코어는 Poplar SDK에 대한 지속적인 최적화와 새로운 IPU-POD 제품의 도입을 통해 고객들에게 AI 훈련 성능의 극적인 향상을 제공했습니다.
2021년 초의 첫 번째 MLPerf 제출 이후, 올해 내내 이룩한 놀라운 발전은 그래프코어의 끊임없는 혁신 지향적 문화를 분명히 보여 줍니다.
이러한 혁신은 시스템 설계 시 아키텍처 선택에서 시작됩니다. 예를 들어, 호스트 서버와 AI 컴퓨팅을 분리하기로 한 결정은 업계의 다른 업체와 근본적으로 다른 접근 방식이나 이제 그 가치를 증명하고 있습니다.
또한 그래프코어는 끊임없는 혁신을 통해 최소 3개월마다 메이저 소프트웨어 업데이트를 제공함으로써 고객과 협업 중인 작업의 성능을 향상하고 IPU를 위한 새로운 모델과 워크로드를 구현 및 최적화합니다.
이러한 열정은 주변에 전파되기 마련입니다. 2021년 내내 Hugging Face, PyTorch Lightning, VMWare, Docker Hub 등을 비롯한 수많은 하드웨어 및 소프트웨어 파트너들이 시스템에서 최고의 AI 컴퓨팅 성능을 제공하고 누구나 쉽게 액세스하여 이용할 수 있도록 만들겠다는 그래프코어의 목표를 지원했습니다.
그래프코어는 매우 짧은 시간 동안 이러한 성과를 이루었습니다. 향후 12개월 후에는 얼마나 더 발전할지 상상해 보세요.
공유:


