
Dec 01, 2021 \ Machine Learning, IPU-POD, Benchmarks
Dec 01, 2021 \ Machine Learning, IPU-POD, Benchmarks
共有:
GraphcoreがMLPerfに提出した最新のデータは二つの事実をはっきりと示しています。一つは、当社のIPUシステムがより大きく、より効率的になっているということ。そしてもう一つは、当社のソフトウェアの成熟によって、IPUシステムがより高速で、より使いやすくなっているということです。
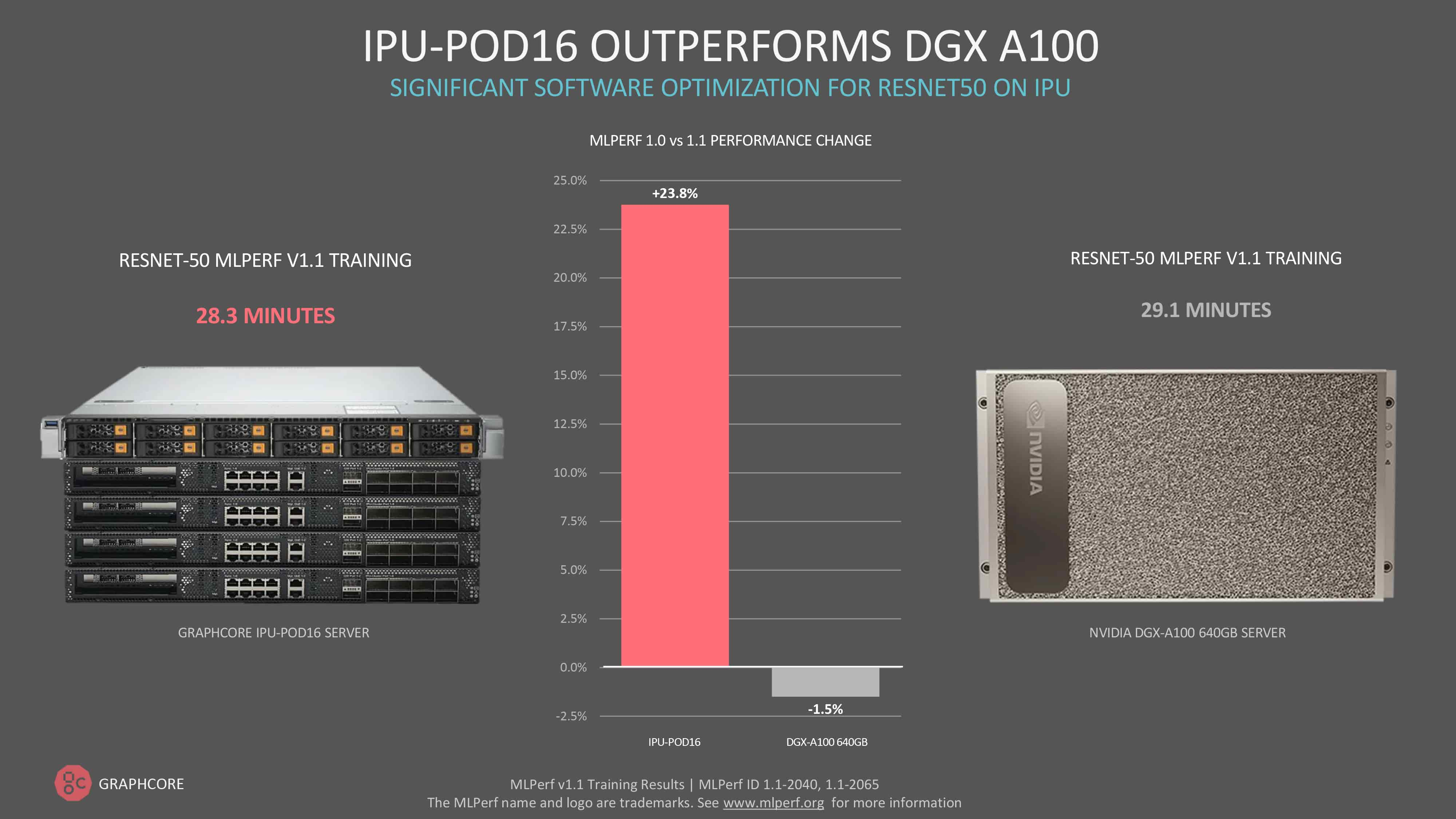
ソフトウェアの最適化によって大幅な性能向上が継続的に達成されることで、当社のIPU-POD16 は今や、コンピュータビジョンモデルResNet-50においてNvidiaのDGX A100をしのぐ性能を発揮するようになりました。
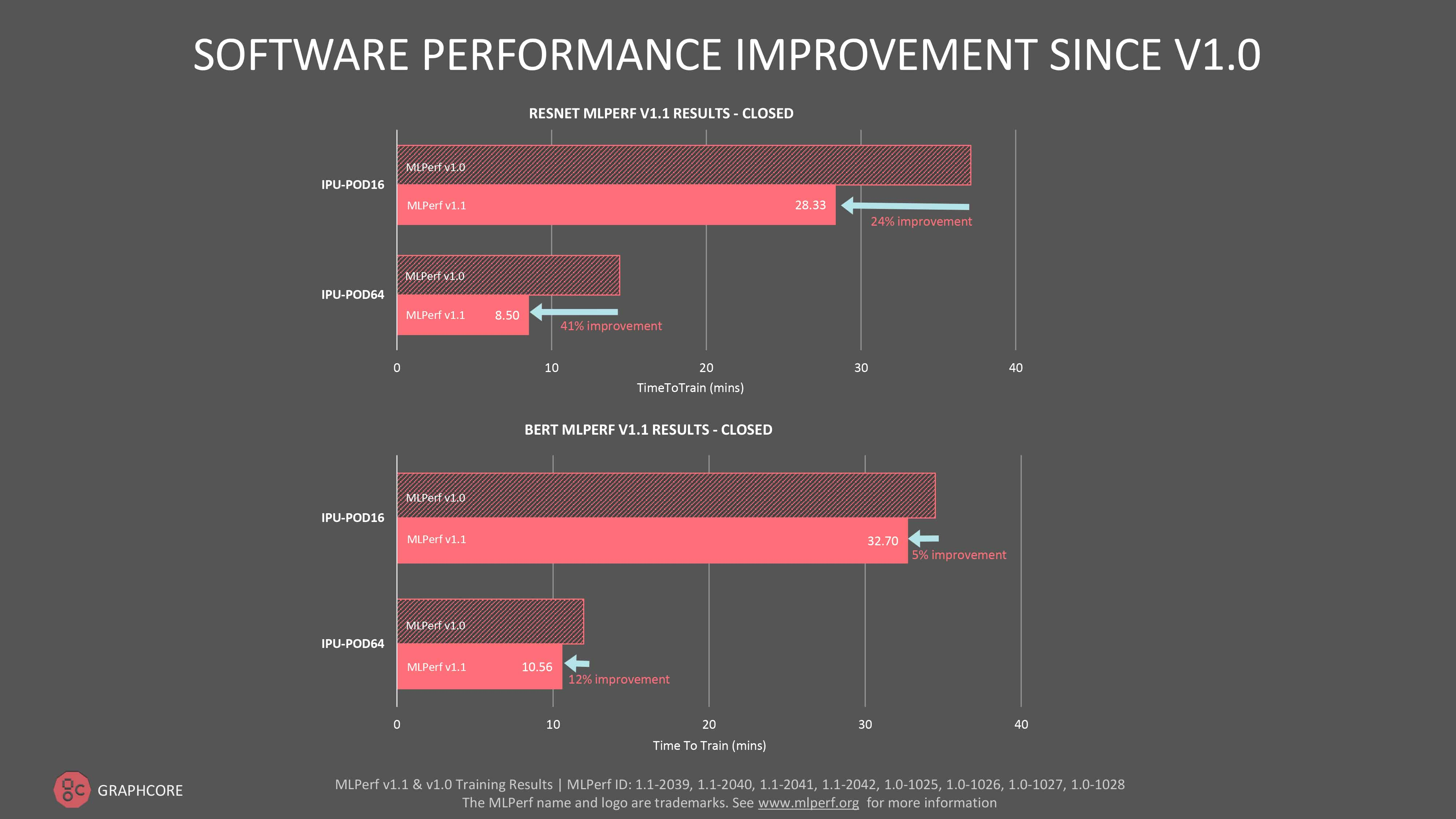
ResNet-50の学習にかかる時間は、DGX A100では29.1分であるのに対し、IPU-POD16では28.3分と、当社がソフトウェアだけで最初に提出したときよりも性能が24%も向上しています。従来ResNet-50がGPUの傑作モデルであったことを考えると、これは意義深いマイルストーンであると言えます。
ResNet-50のソフトウェアによるパフォーマンス向上は、IPU-POD64で41%とさらに大きくなりました。
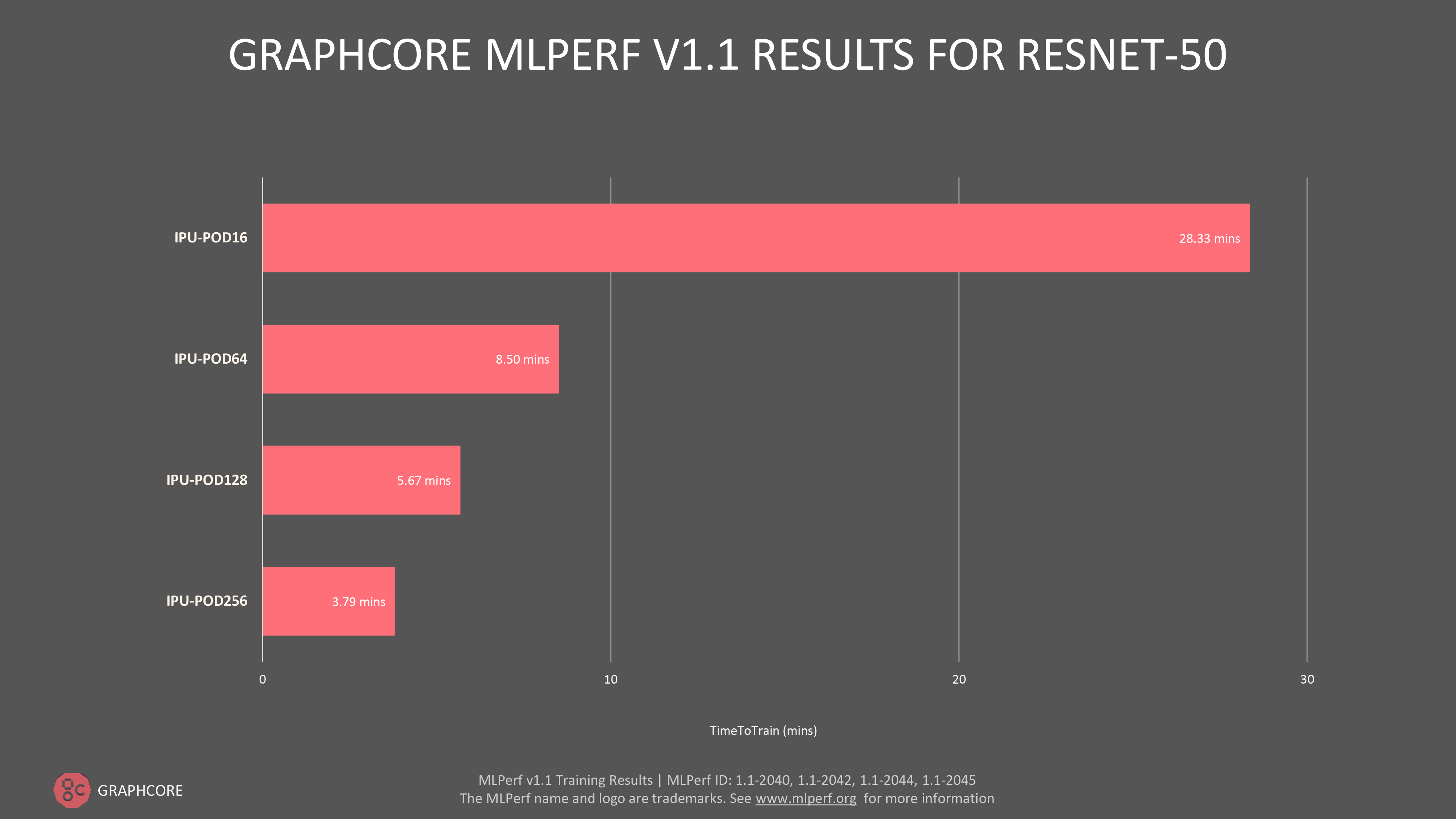
当社はまた、最近発表したIPU-POD128およびIPU-POD256 のスケールアウトシステムでも素晴らしい結果を得ました。当社はこれらのシステムを最初からMLPerfの「市販」カテゴリーにエントリーしましたが、その背景には、スケールアップしても優れた性能を発揮するというGraphcoreのコミットメントがあります。
当社のより大規模なフラッグシップシステムでは、ResNet-50の学習にかかる時間はIPU-POD128で5.67分、IPU-POD256で3.79分でした。
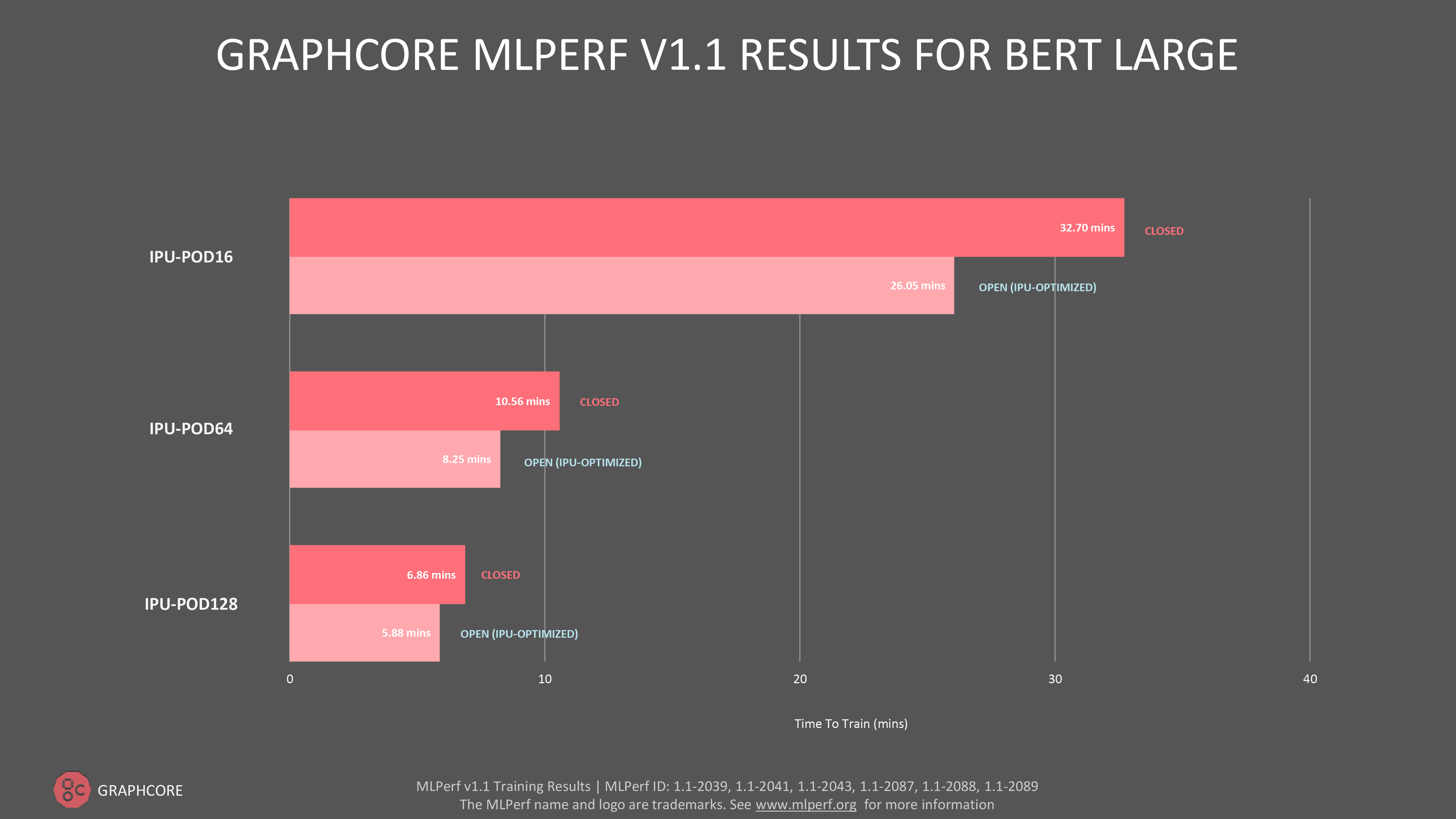
自然言語処理(NLP)モデル「BERT」については、IPU-POD16、IPU-POD64 、およびIPU-POD128でオープンとクローズドの両カテゴリーに提出し、新しいIPU-POD128のオープンの提出において学習時間5.78分という驚異的な結果を得ました。
全体としては、直近のMLPerf学習ラウンドと比較して、IPU-POD16では5%、IPU-POD64 では12%のBERT性能の向上が確認できました。
MLPerfのクローズド部門では、モデルの実装やオプティマイザのアプローチが全く同じであることが提出者に厳格に要求され、これにはハイパーパラメータの状態や学習エポックの定義も含まれます。
オープン部門は、クローズド部門と全く同じモデルの精度と品質を確保しつつ、モデルの実装に柔軟性を持たせることでイノベーションを促進することを目的としています。
私たちはオープン部門のBERT学習の結果を明らかにすることで、Graphcoreのお客様が、最適化された当社製品を利用することで当然のように達成できる現実世界の性能を、読者の皆様にも実感していただけると考えています。
Graphcoreは、MLPerfとその組織団体であるMLCommonsの支援に力を入れています。その第三者による検証が、お客様がAIコンピュートシステムの能力や、さまざまな企業が提供するソフトウェアスタックの成熟度を独自に評価する上で、重要な役割を果たしていることは確かです。
お客様は、ResNetやBERTなどのモデルを実稼働レベルで使い続けながら、もう一方では革新的な新しいモデルを模索したり、大規模な機械知能を提供するためにGraphcoreのより大規模なフラッグシップシステムに期待したりしています。
当社が提出したMLPerfには含まれていませんが、革新的なコンピュータビジョンであるEfficientNet B4は、当社の主力製品であるIPU-POD 256においてわずか1.8時間で学習を完了しました。
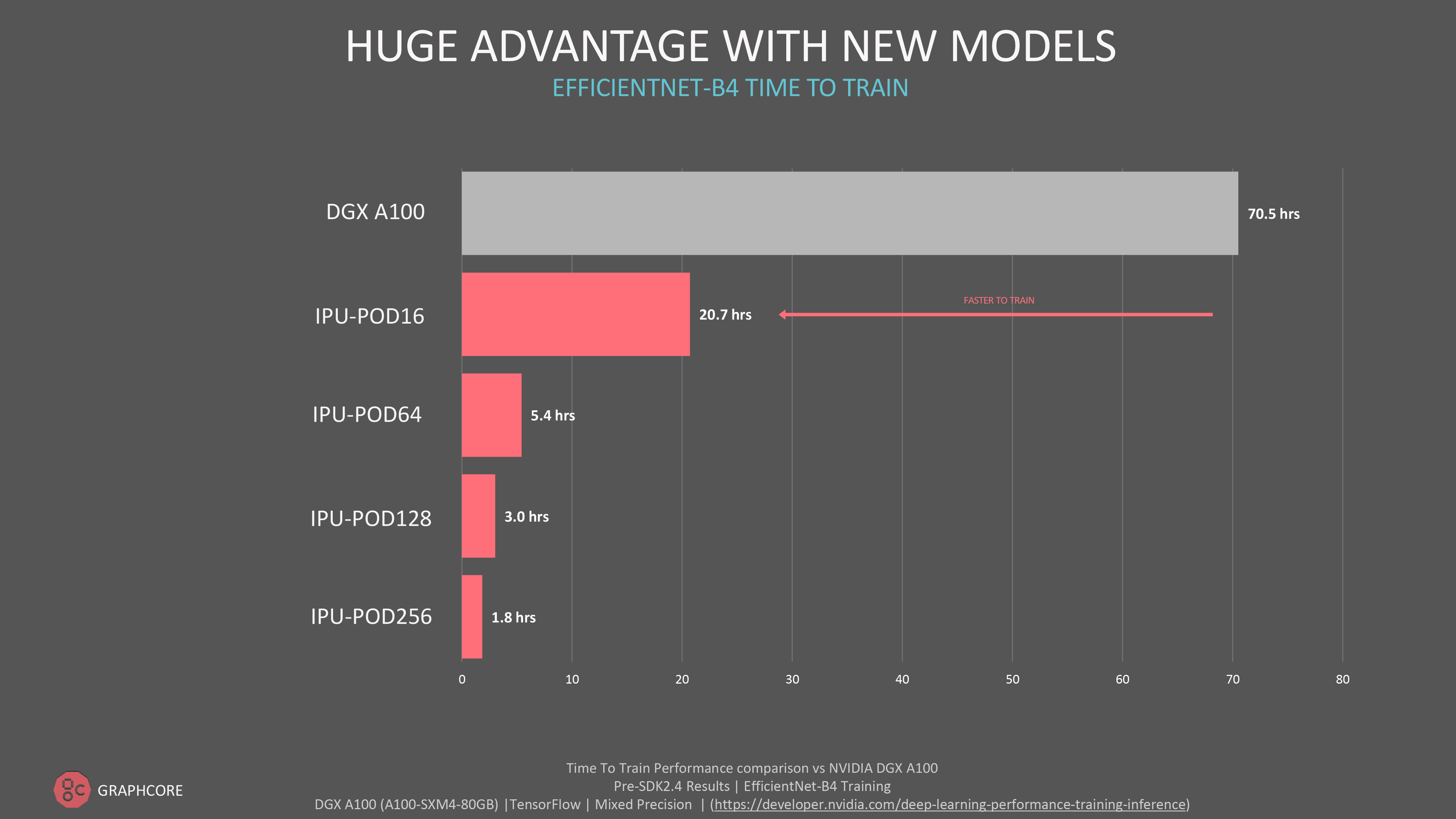
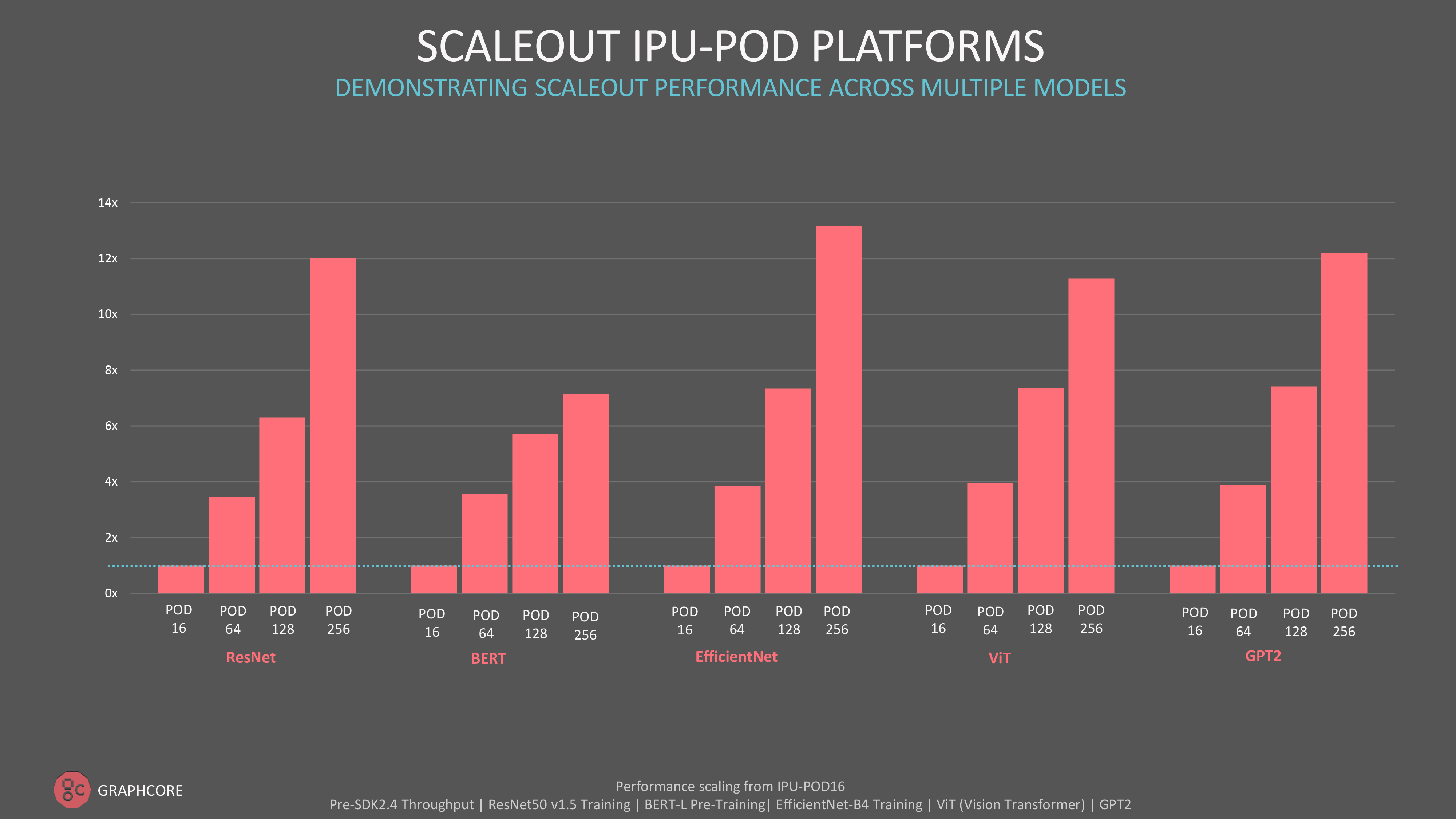
絶対的なスループット性能や、当社のより大規模なIPU-PODシステムへのスケールアウトに関心があるお客様には、自然言語処理モデルのGPTクラスのモデルや、コンピュータビジョンのViT(Vision Transformer)など、MLPerf以外でもさまざまなモデルで素晴らしい結果が得られている事実をご紹介できます。
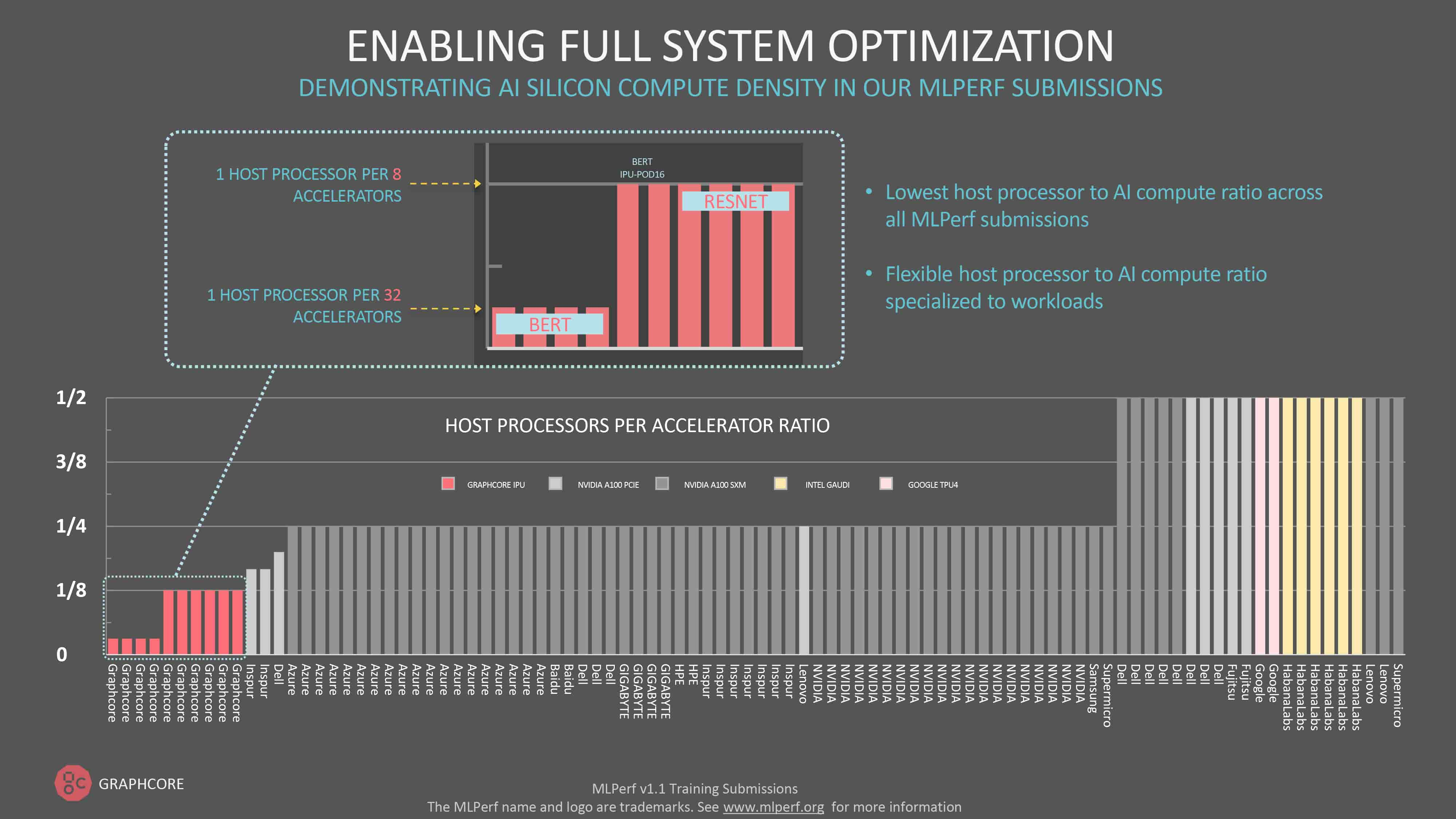
今回、または他の回のMLPerfラウンドの生データを見た人は、各メーカーのシステムに関連付けられているホストプロセッサの数に強い印象を受けるはずです。2つのAIプロセッサに対してCPUを1つという仕様にしている参加企業もあります。
これに対してGraphcoreは、IPUに対するホストプロセッサの比率が常に最も低いのが特徴です。
他のどのメーカーとも異なり、IPUはデータの移動にホストサーバーを使用するだけで、実行時にコードをディスパッチするホストサーバーを必要としません。その結果、IPUシステムに必要なホストサーバーの数が減り、より柔軟で効率的なスケールアウトシステムを実現できます。
BERT-Largeのような自然言語処理モデルの場合、IPU-POD64ではデュアルCPUを搭載したホストサーバーが1台あれば十分です。ResNet-50では画像の前処理により多くのホストプロセッサのサポートを必要とするので、仕様上、IPU-POD64あたり4台のデュアルコアサーバーとしています。この場合の比率は1対8ですが、それでもMLPerfに参加する他のどのメーカーよりも低い値です。
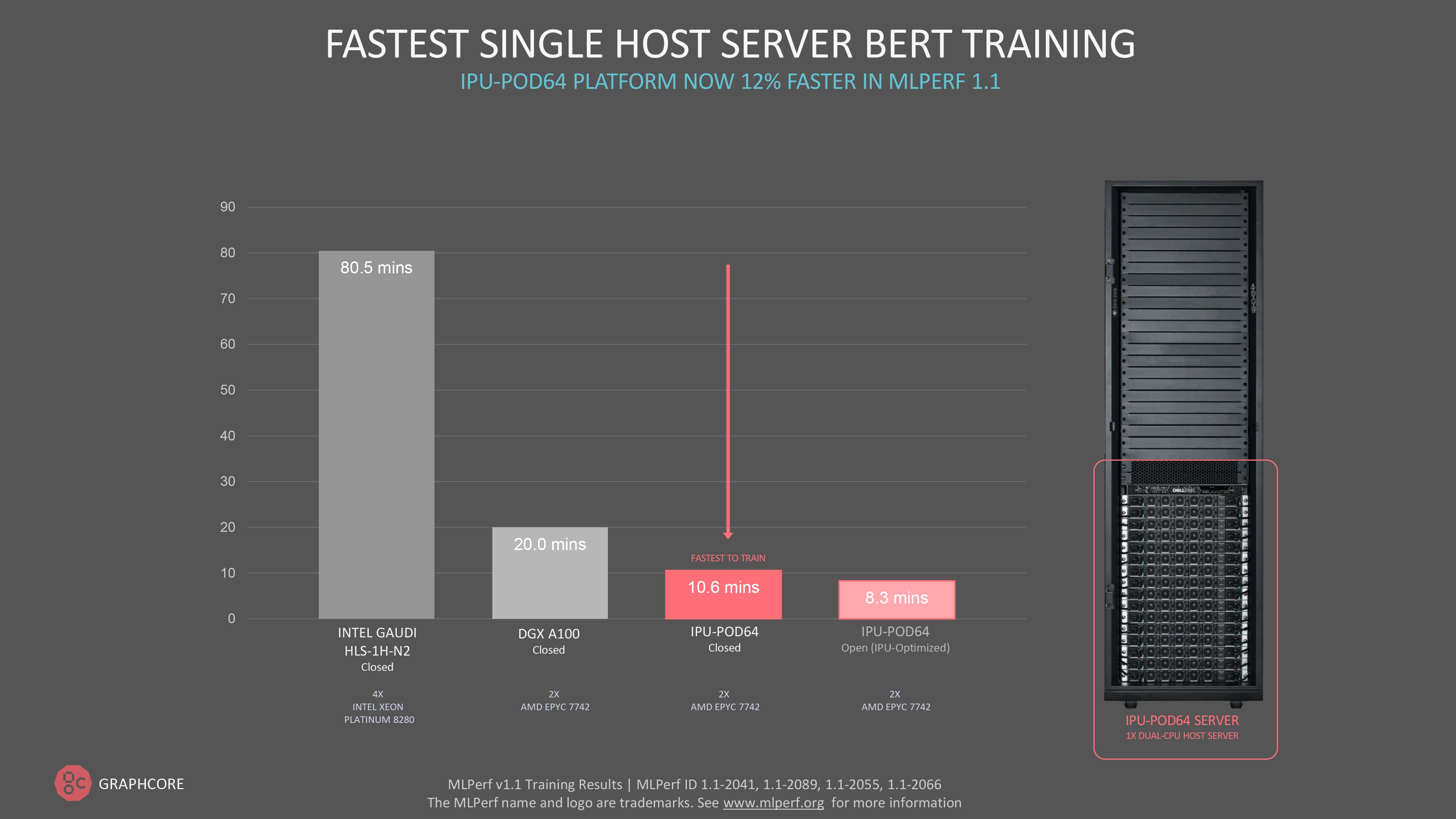
実際、今回のMLPerf 1.1の学習ラウンドにおいてGraphcoreは、シングルサーバーでのBERTの学習を10.6分で完了するという最速の結果を出しました。
Poplar SDKの継続的な最適化とIPU-PODの新製品の導入を同時に進めることで、当社からお客様に提供できるAI学習機能が飛躍的に向上しました。
2021年の初めにGraphcoreが初めてMLPerfの評価に挑戦して以来、そして今年全体で見ても、絶え間ないイノベーションを追求する当社の企業文化を証明するような、驚異的な進歩が続いています。
その始まりは、システムを設計する際のアーキテクチャの選択まで遡ります。例えば、当社のホストサーバーとAIコンピュートを分離するという決定は、この業界の他の企業とは根本的に異なるアプローチですが、今ではその価値が証明されつつあります。
絶え間ないイノベーションを追求する企業文化は、少なくとも3ヶ月ごとにソフトウェアの大幅なアップデートを行うことにも表れており、性能の向上につながっています。もちろん、当社はお客様と協力して、IPUの新しいモデルやワークロードの実装と最適化も進めています。
その熱意は人から人へ広がります。2021年を通して、Hugging FaceやPyTorch LightningからVMWareやDocker Hubまで、数え切れないほどのハードウェアやソフトウェアのパートナーがGraphcoreと協力し、究極のAIコンピュート性能を、誰もが効果的にアクセスできる使いやすいシステムで提供するという共通の目標に向けて取り組んできました。
この短期間で、ここまで進歩しました。12ヶ月後の私たちの姿を想像してみてください。
共有:


