
Nov 13, 2019
Nov 13, 2019
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamThis blog post was updated on 4th June 2020 following further optimisations to our Poplar software stack. Please visit our Performance Benchmarks page for our most recent benchmarks.
We are delighted to share a selection of performance benchmarks based on IPU systems that are now available as an IPU Cloud preview on Microsoft Azure and as IPU-Server products from Dell with full support from our production release Poplar® software stack.
Customers are able to replicate our benchmarks using code which is available as public examples on the Graphcore GitHub site. Code for all of the benchmarks in this blog can be downloaded from GitHub, plus several other application examples. Customer implementations have not been made available as public examples, as you would expect. Please check back regularly as we will be adding more applications on an ongoing basis.
The Graphcore IPU is a new type of processor designed from the ground up for machine intelligence. The IPU has a number of distinguishing architectural features that result in much higher performance for both training and inference, especially on new, more complex machine learning models. Below we have identified some of the benefits that the IPU enables:
Many of today’s standard benchmarks are backward looking and do not take into account the important characteristics and performance capabilities that will be required to support the next breakthroughs in machine intelligence. So rather than focus on these older approaches we have instead focused on working with customers to support real world applications and to help them try out new approaches and solve more complex problems. We are delighted to share a selection of performance benchmarks that include newer model structures and approaches.
The IPU does deliver state of the art performance on today’s image processing and language models but we are also seeing significant performance gains in several new model types, like ResNeXt and models using MCMC (Markov Chain Monte Carlo) based methods.
Machine Intelligence innovation is just in the very early stages and we expect to see many new innovations developed over the next few years. The IPU has been designed to help innovators create these new breakthroughs.
BERT (Bidirectional Encoder Representations from Transformers), published by researchers at Google AI Language, represents an important development in the field of Natural Language Processing (NLP). Attention based Transformer models allow for unsupervised learning of language structure and meaning in text. With BERT, a key innovation is the application of bidirectional training of the Transformer attention model, to provide a more complete and accurate sense of language understanding and interpretation. In addition, after pre-training the BERT model on a wide corpus of language, fine tuning on more specific language data can be used to target the model to the specific NLP use case.
Graphcore shows >25% faster time to train and state of the art accuracy with BERT-base at 20% lower power, a significant proof point for the IPU architecture. To date, only three processor providers have demonstrated training capability with BERT: Google, NVIDIA, and Graphcore. In addition, the architecture of the IPU is particularly well suited to the next breakthroughs in NLP, including such innovations as Block-Sparse based Transformer models.

For NLP Inference, as with many other inference use cases, there is a strong emphasis on the highest possible throughput at the lowest possible latencies. For example, this requirement is highlighted in a report on the importance of performance, in particular latency, for search engine companies. The report mentions an Amazon analysis showing that a 100ms slowdown decreases sales by 1%. Likewise experiments by Microsoft Bing indicated a 100ms speedup improves revenue by 0.6%.
The inference benchmark reported below is therefore focused on evaluating throughput at the lowest possible latency. Throughput becomes less meaningful as batch sizes increase since the required latency for larger batch sizes becomes problematic in a real application. Graphcore is able to demonstrate with BERT-base inference 2x higher throughput at the lowest latency compared to today’s solutions.
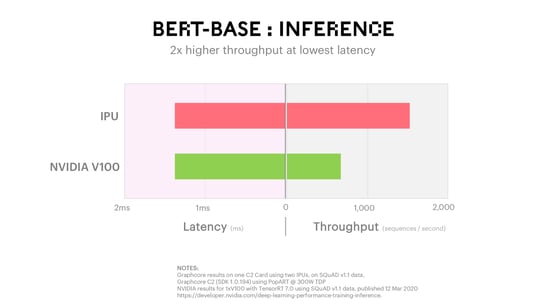
In addition to the importance of high throughput at low latency, accuracy also has a strong impact on revenue for internet companies. In ad placement or search engine use cases, a percentage point increase in accuracy directly maps to revenue gains. In medical imaging applications, higher accuracy is even more important.
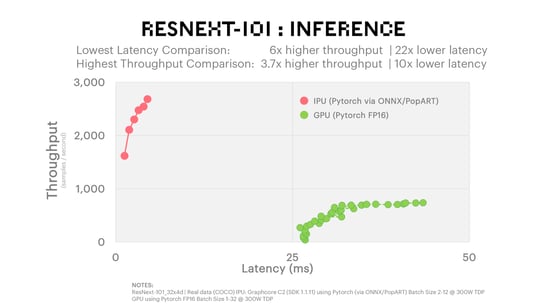
As an example of a new class of image classification models, ResNext uses innovative approaches, like group and depthwise separable convolutions, to increase accuracy while reducing the parameter count. These approaches are not well suited to legacy architectures that struggle with the unaligned data accesses critical for these newer, more accurate models. This means companies have been held back from moving beyond today's simple CNN models that work well on legacy processor architectures.
However, the use of group separable convolutions, which involves splitting the convolution filters into smaller separable blocks, is much more suited to the IPU’s massively parallel architecture.
As seen in the chart below, the Graphcore C2 IPU-Processor PCIe card achieved 6x throughput advantage and 22x lower latency (at the lowest possible latency for each solution). High throughput at the lowest possible latency is key in many of the important use cases today, and particularly for internet applications and medical imaging as mentioned, where lag can have a direct impact on sales and, crucially, on patient health.
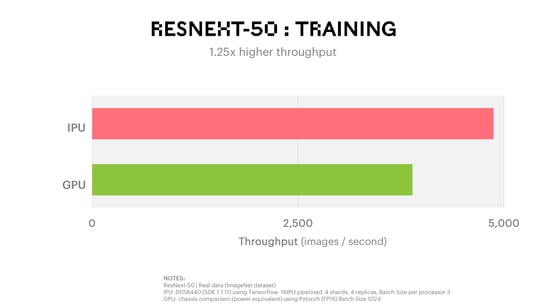
ResNeXt-50 is another model from the innovative ResNeXt class which offers accuracy advantages for image classification. We used the Dell DSS8440 IPU Server which contains 8 C2 cards to assess ResNeXt-50 training performance on the IPU in TensorFlow. The model was trained with real data from ImageNet - a database of over 14 million images intended for computer vision research. To exploit the massive parallelism of our IPU hardware, we employed pipelining and sharding techniques to partition ResNeXt-50 for parallel execution and improved processor efficiency. The result was state of the art time to train resulting in 1.25x higher throughput and almost 5000 images processed per second, compared with 3888 images per second on the GPU.
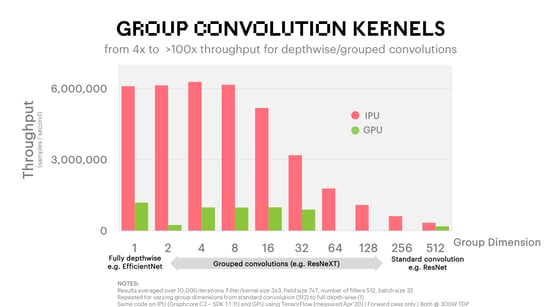
The micro-benchmarks below provide greater insight into how the architecture of the IPU fits with increasing degrees of separable convolution. The IPU is able to support increasing levels of group separable convolutions with its ability to flexibly map smaller blocks of data to thousands of fully independent processing threads and as a result of its much more flexible and higher throughput memory architecture. In this micro-benchmark, we vary the group dimension to show coverage from a standard convolution with a group size dimension of 512, through multiple group convolutions, all the way down to group size dimension of 1 which corresponds to a fully depthwise convolution (filter depth of a single layer).
The chart below shows the results for a Graphcore C2 IPU-Processor PCIe card versus a leading alternative processor at equivalent power, starting with standard convolution on the far right, moving right to left through increasingly smaller group convolutions, until the fully depthwise convolution (group dimension 1) on the far left. The results show the IPU advantage across the sweep of group convolutions, with significant advantage for group convolutions, and delivering from 4x up to >100x throughput advantage.
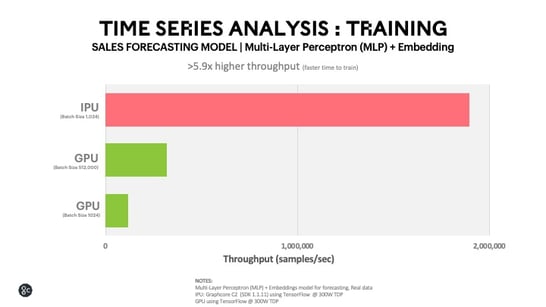
This benchmark shows a typical model used in time series analysis consisting of MLP (Multi-Layer Perceptron) networks combined with feature embeddings. The model predicts the amount of sales on a particular day given a set of features in the original Rossmann competition dataset. The results from our comparative testing show a performance advantage for the Graphcore C2 IPU-Processor PCIe card of 16x versus an alternative leading processor at equivalent power and batch size (batch size - 1,024). Even when we increase the batch size for the leading alternative processor up to 512,000 to maximise its throughput we still see >5.9x improvement in throughput for the Graphcore C2 platform that is using the smaller 1,024 batch size.
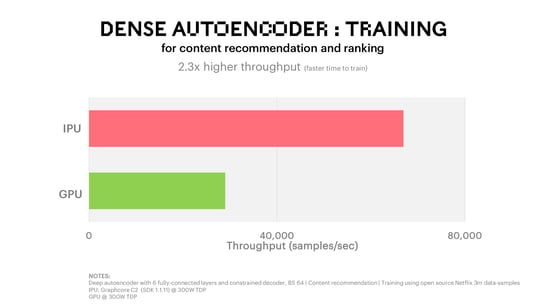
Autoencoder models can be used to perform collaborative filtering in recommender systems in order to provide useful predictions, for example recommending films for online TV viewers based on previous viewing experiences. This autoencoder model shows significant improvement in results compared to previous models when tested using a publicly available Netflix dataset made up of 3m data samples.
The model architecture is a deep autoencoder with 6 fully connected layers and a constrained decoder. Dense re-feeding is used for training to overcome the sparseness of data in collaborative filtering. It is implemented in TensorFlow with a model size of about 10 million parameters. This model is taken from the paper “Training Deep AutoEncoders for Collaborative Filtering”.
The results from our comparative testing show a performance advantage for the Graphcore C2 card of more than 2x versus a leading alternative processor at equivalent power.
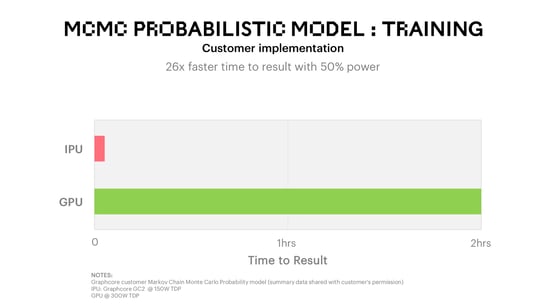
Customers in the finance sector have been able to train their proprietary, optimised models using MCMC in just 4 ½ minutes on IPUs, compared to over 2 hours with their existing hardware. This represents a 26x speed up in training time using only half the power required by the alternative processor.
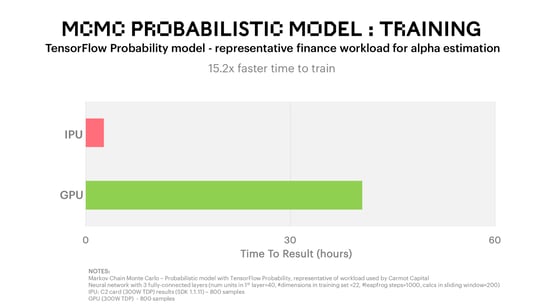
Using the off the shelf TensorFlow Probability (TFP) library to assess the performance of probabilistic models on IPU, we see that the MCMC algorithms train >15x faster on an IPU platform compared to the next best alternative.
In this example, the model is a neural network with three fully connected layers and is a representative finance workload for alpha estimation. The input data set are features generated from a time series of stock prices. Distributions of model parameters are represented by their samples. The samples are obtained using the Hamiltonian Monte Carlo (HMC) algorithm, which is an MCMC method efficient in high-dimensional cases. Sampling is performed in a sliding time window on subsets of the data. This is done to test the historical predictive power of the model. Using the IPU platform, we were able to train the model in 2 hours 40 minutes down from over 40 hours on the best alternative processor.
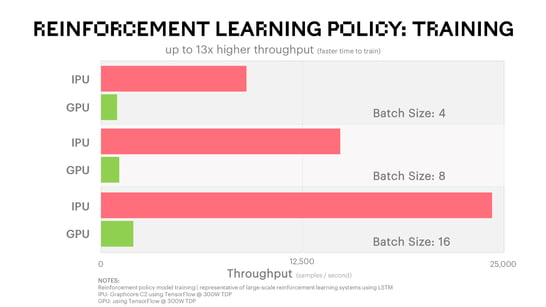
Reinforcement Learning (RL) can be thought of as a framework for solving complex problems and is fundamental to the future of machine intelligence. Reinforcement learning provides a clean, simple language to state general AI problems. In reinforcement learning, there is a set of actions, a set of observations and a reward. The goal in reinforcement learning is to learn a policy which is a function of the observations, the rewards and the actions, and which maps histories to actions so as to try and maximise the expected sum of observed rewards. As an example, reinforcement learning has been used to teach machines how to play games completely unsupervised.
Reinforcement learning requires the machine intelligence system to remember previous histories and uses these to help learn the policy. Low latency and fast access to complex state spaces is critical. To show the potential performance of IPU on reinforcement learning policy training problems, we have taken a typical policy model such as those found within RL problems and compared performance against existing processor solutions. With no optimisation, the IPU delivers an order of magnitude (10x) improvement in throughput which results in much faster time to train for these complex and compute intensive problems. Work with some of our customers has shown even higher levels of performance gain.
We are only at the beginning of exploring ongoing optimisation in our performance across a wide range of models for training and inference and will continue to share code and results publicly.
For more information or to be contacted by one of our sales team, please register your interest here.
The products, systems, software, and results are based on configurations existing at the time of the measurements, and as such are subject to change at any time, without notice. For more information regarding methodology or results, please contact Graphcore.
Share:


