For more performance results, visit our Performance Results page




Grow
IPU-POD
When you're ready to scale, choose IPU-POD128 for production deployment in your enterprise datacenter, private or public cloud. Experience massive efficiency and productivity gains when large language training runs are completed in hours or minutes instead of months and weeks. IPU-POD128 delivers for AI at scale.
- Superior scaling & blazing fast performance
- Full systems integration support for datacenter installation.
- AI expert support to develop & deploy models at scale.
Start growing your AI compute capacity in the cloud or in your datacenter with IPU-POD128.
IPU-POD128 is designed for straightforward deployment, integrating effectively with standard datacenter infrastructure, including VMWare virtualization, OpenStack. Slurm and Kubernetes support, so it's simple to automate application deployment, scaling, and management. Virtual-IPU™ technology offers secure multi-tenancy. Developers can build model replicas within and across multiple IPU-PODs and provision IPUs across many IPU-PODs for very large models.


In order to continuously support the increasing super-scale AI HPC environment market demand, we are partnering with Graphcore to upgrade our IPU-POD64s to an IPU-POD128 to increase the “Hyperscale AI Services” offering to our customers. Through this upgrade we expect our AI computation scale to increase to 32 PetaFLOPS of AI Compute, allowing for more diverse customers to be able to use KT’s cutting-edge AI computing for training and inference on large-scale AI models.
Mihee Lee, SVP Cloud/DX Business
Korea Telecom



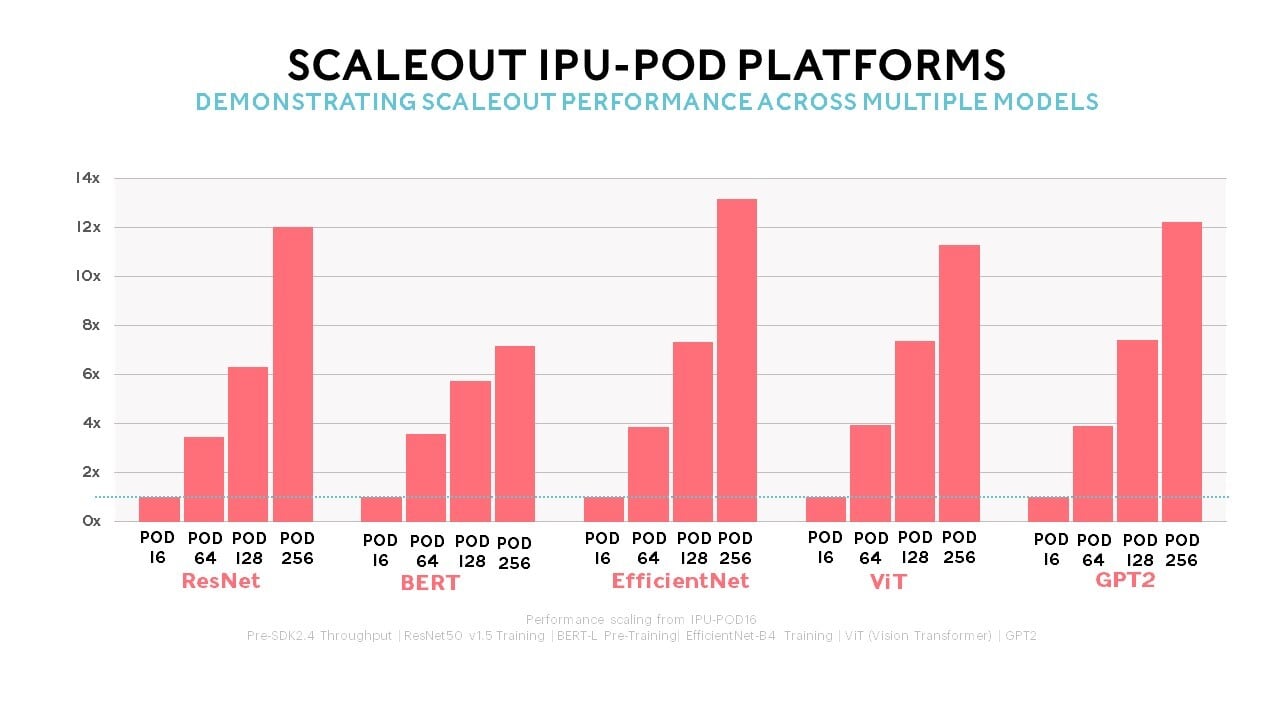
Performance
World-class results whether you want to explore innovative models and new possibilities, faster time to train, higher throughput or performance per TCO dollar.
EXTENSIVE ECOSYSTEM
Software tools and integrations to support every step of the AI lifecycle from development to deployment to improve productivity and AI infrastructure efficiency. And just make it easier to use.















| IPUs | 128x GC200 IPUs |
| IPU-M2000s | 32x IPU-M2000s |
| Memory | 115.2GB In-Processor-Memory™ and up to 8.2TB Streaming Memory |
| Performance | 32 petaFLOPS FP16.16 8 petaFLOPS FP32 |
| IPU Cores | 188,416 |
| Threads | 1,130,496 |
| IPU-Fabric | 2.8Tbps |
| Host-Link | 100 GE RoCEv2 |
| Software |
Poplar TensorFlow, PyTorch, PyTorch Lightning, Keras, Paddle Paddle, Hugging Face, ONNX, HALO OpenBMC, Redfish DTMF, IPMI over LAN, Prometheus, and Grafana Slurm, Kubernetes OpenStack, VMware ESG |
| System Weight | 900kg + Host servers and switches |
| System Dimensions | 32U + Host servers and switches |
| Host Server | Selection of approved host servers from Graphcore partners |
| Thermal | Air-Cooled |

Explore
IPU-POD
Ideal for exploration, the IPU-POD16 gives you all the power, performance and flexibility you need to fast track your IPU prototypes and speed from pilot to production. IPU-POD16 is your easy-to-use starting point for building better, more innovative AI solutions with IPUs whether you're focused on language and vision, exploring GNNs and LSTMs or creating something entirely new.
View Product
Build
IPU-POD
Ramp up your AI projects, speed up production and see faster time to business value. IPU-POD64 is the powerful, flexible building block for world-leading AI performance in your enterprise datacenter, private or public cloud. Whether you're running large language models or rely on fast and accurate vision models, IPU-POD64 will deliver the results you need today as well as giving you the opportunity to explore innovative AI solutions for tomorrow.
View Product
Grow
IPU-POD
When you're ready to explore AI compute at supercomputing scale, choose IPU-POD256 for production deployment in your enterprise datacenter, private or public cloud. Experience massive efficiency and productivity gains when large language training runs are completed in hours or minutes instead of months and weeks. IPU-POD256 delivers AI at scale.
View Product