Aug 09, 2021 \ Research, Natural Language Processing
Aug 09, 2021 \ Research, Natural Language Processing
共有:
新しいパッキングアルゴリズムを使用することで、GraphcoreはBERT-Largeの学習中に自然言語処理を2倍以上高速化しました。この新しいパッキング技術はパディングを排除して、計算効率を大幅に向上させます。
この技術は、ゲノミクスやタンパク質の折り畳みモデルなど、長分布が歪んでいるモデルにも応用できるので、さまざまな業界やアプリケーションにとても大きな影響を与えるのではないかと考えています。
Graphcoreの高効率なNNLSHP(Non-Negative Least Squares Histogram-Packing、非負最小二乗ヒストグラムパッキング)のアルゴリズムと、パッキングされたシーケンスに適用されるBERTアルゴリズムについて、私たちは新しい論文で紹介しました。
私たちは、MLPerfTMに提出した最近のベンチマークに取り組んでいる間に、BERTの学習を最適化する新しい方法を検討し始めました。その目的は、実際のアプリケーションで簡単に採用できる便利な最適化を開発することでした。BERTは産業界や当社の多くのお客様に広く使用されているため、そのような最適化について注力すべきモデルの1つとして当然の選択でした。
Wikipediaのデータセットを使用した私たち独自のBERT-Large学習アプリケーションでは、データセット内のトークンの50%がパディングであり、結果的に多くの計算が無駄になっていることを知ったときはとても驚きました。
シーケンスをパディングして同じ長さに揃えるのは、GPUでは一般的なアプローチですが、それとは違うアプローチを試してみる価値があると考えたのです。
シーケンスの長さのばらつきが多くなるのには、次のような2つの理由があります。
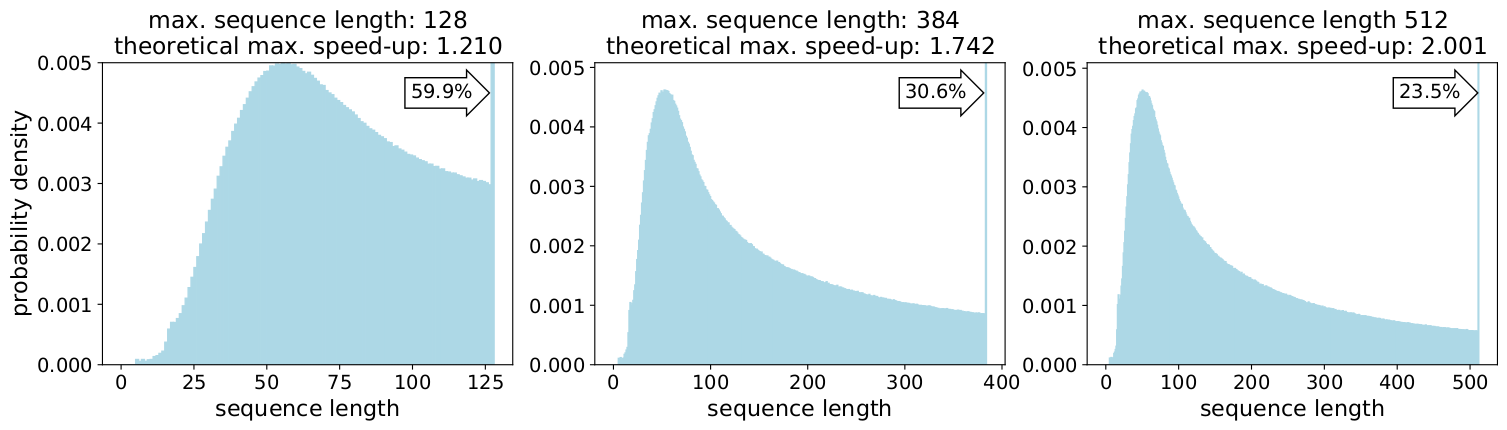
最大長の512まで長さを詰めると、全トークンの50%がパディングトークンになります。50%のパディングを実データに置き換えることで、同じ計算量で処理できるデータ量が50%増加し、最適な条件で2倍の高速化が可能になりました。
これはWikipedia特有のものなのでしょうか?いいえ、違います。
それでは、言語特有のものなのでしょうか?それも違います。
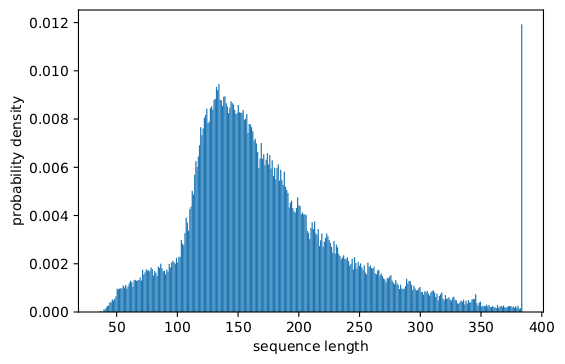
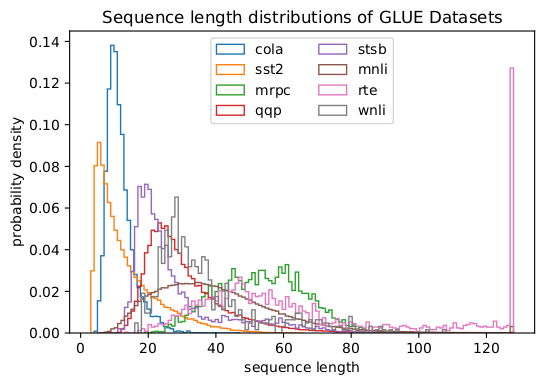
事実、歪んだ長分布は言語、ゲノミクス、タンパク質の折り畳みなど、あらゆるところで見られます。図2と図3はSQuAD 1.1データセットとGLUEデータセットの分布を表しています。
計算の無駄を省きながら、異なる長さに対応するにはどうすればよいのでしょうか?
現在のアプローチでは、長さに応じて異なる計算カーネルを必要としたり、エンジニアがプログラムでパディングを除去してから、Attentionブロックや損失計算ごとに繰り返しそのパディングを追加しなければならなかったりします。計算量を節約するために大げさなコードを作って複雑にするのは魅力的ではないので、私たちは異なるアプローチを探しました。複数のシーケンスを最大長のパック1つにまとめて、それをまとめて処理することはできないだろうか?それが可能であることがわかったのです!
このアプローチには重要な要素が3つ必要です。
当初は、Wikipediaのような大規模なデータセットを効率的にパッキングすることはできないと思われていました。この問題は一般的に「ビンパッキング」と呼ばれています。パッキングを3つ以下のシーケンスに限定した場合でも、結果として強いNP完全問題で残り、効率的なアルゴリズム解法はありません。既存の経験則によるパッキングアルゴリズムは、シーケンスの数をnとすると、最低でも\(O(n log(n))\)の複雑さになるため、期待できるものではありませんでした(Wikipediaでは最大で16M)。私たちが求めていたのは、何百万ものシーケンスにも十分に対応できるアプローチでした。
そこで、次のような2つのトリックを使って複雑さを大幅に軽減しました。
私たちが用いた最大シーケンス長は512でした。そこで、ヒストグラムに移行することで、1600万個のシーケンスから512個の長さカウントに次元と複雑さが減りました。1つのパックに最大3つのシーケンスを入れることで、許容される長さの組み合わせは22Kになりました。これにはすでに、パックの中でシーケンスを長さ順に並べることを要求するトリックが含まれています。それでは、4つのシーケンスではどうでしょうか?そうすると、組み合わせの数は22Kから940Kに増え、最初のモデル化のアプローチには多すぎました。さらに、深さ3ではすでに、非常に高いパッキング効率を実現していました。
当初私たちは、4つ以上のシーケンスを1つのパックで使用すると、計算オーバーヘッドが増えて、学習中の収束挙動に影響するだろうと考えていました。しかし、さらに高速でリアルタイムなパッキングを必要とする、推論などのアプリケーションに対応するために、高効率なNNLSHP(Non-Negative Least Squares Histogram-Packing、非負最小二乗ヒストグラムパッキング)アルゴリズムを開発しました。
ビンパッキングはかなりの頻度で数学的最適化の問題として定式化されます。しかし、1600万個(またはそれ以上)のシーケンスでは、これは現実的ではありません。問題となる変数だけでも、ほとんどのマシンのメモリを超えてしまいます。ヒストグラムベースのアプローチのための数学的プログラムは、実に無駄がありません。私たちはヒストグラムベクトル\(b\)を用いた最小二乗法(\(Ax=b\))を採用して簡素化しました。そしてそれを、戦略ベクトルxを非負にすることを要求し、小さなパディングを可能にするための重み付けを加えることで拡張したのです。
厄介だったのは戦略マトリクスです。縦の列それぞれの最大の和は3で、どのシーケンスが目的の全長(今回の例では512)にぴったり合うようにパッキングされるかをコード化します。横の列は、全長の長さに到達するための潜在的な組み合わせをそれぞれコード化します。私たちが求めていたのは、20kの組み合わせのうち、どれをどのような頻度で選択するのかを表す戦略ベクトル\(x\)です。面白いことに、最終的に選ばれたのは約600の組み合わせだけでした。厳密解を得るためには、xの戦略カウントが正の整数である必要がありますが、非負の\(x\)だけで丸められた近似解が得られることに気づきました。近似解であれば、すぐに使えるシンプルな解法を使用して、30秒以内に結果を得ることができます。
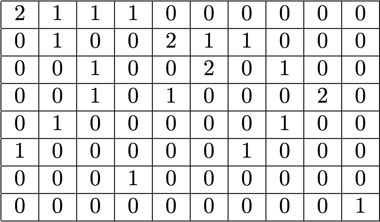
そして最後に、戦略が割り当てられなかったサンプルを修正する必要がありましたが、それは最小限度だけ行いました。各シーケンスがパッキングされ(パディングによる可能性もある)、パディングに依存した重み付けが行われることを強制するバリアント解法も開発しましたが、それは時間がかかり、解法もそれほど良いものではありませんでした。
このように私たちは、NNLSHPから十分なパッキングアプローチを得ることができました。しかし理論的には、より高速なオンライン対応のアプローチが可能で、3つのシーケンスしか組み合わせられないという制限を取り除くことができないかと考えていました。
そこで、既存のパッキングアルゴリズムからヒントを求めながらも、ヒストグラムにもう一度着目しました。
最初のアルゴリズムであるSPFHP(Shortest-pack-first histogram-packing、最短パック最優先ヒストグラムパッキング)には4つの要素があります。
このアプローチは最も簡単に実装することができ、0.02秒しかかかりませんでした。
さらに、一番短いシーケンスの代わりにシーケンス長の最大の合計を取り、カウントを分割することによって、より完璧な適合を得るというアプローチもありました。このアプローチでは概して、効率はあまり変わらなかったものの、コードの複雑さは格段に増しました。
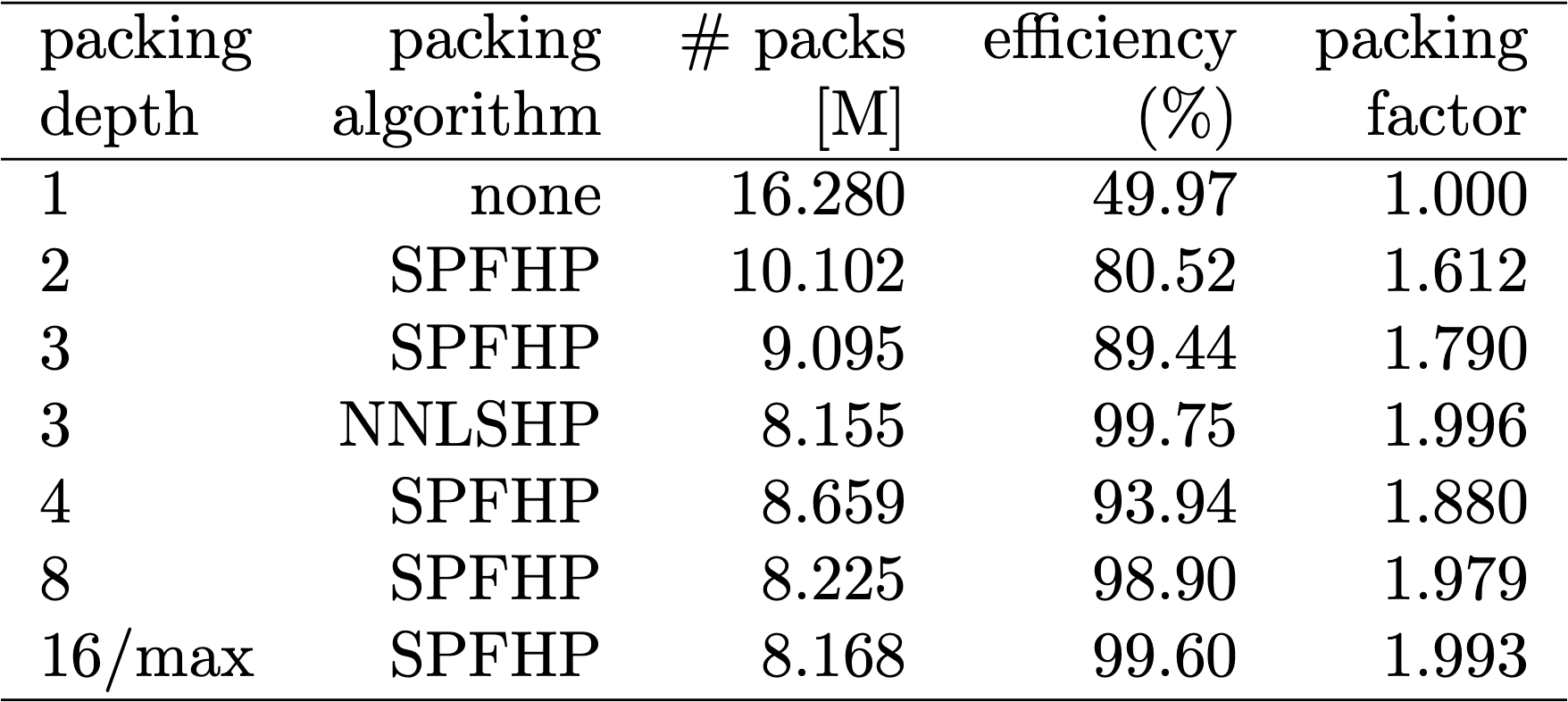
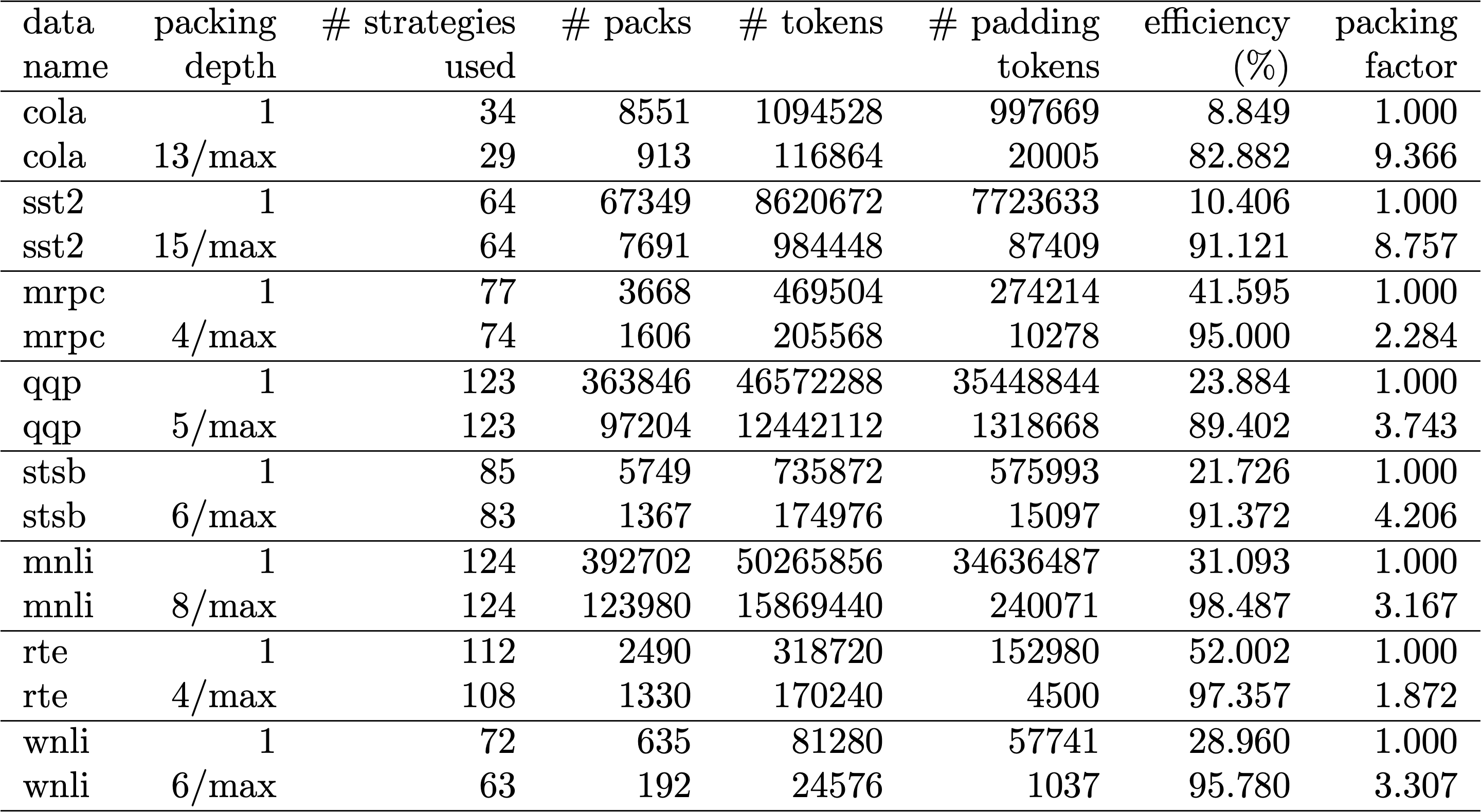
表1、2、3は、私たちが試した2つのアルゴリズムのパッキング結果です。「パッキング深さ」は、パッキングされたシーケンスの最大数を表しています。パッキング深さ1はベースラインのBERT実装です。制限を設けない場合に発生する最大のパッキング深さは、追加の「max」で表されています。「パックの数」は、新しいパッキングされたデータセットの長さを表しています。「効率」は、パッキングされたデータセットに含まれる、実在するトークンの割合です。「パッキング係数」は、パッキング深さ1と比較した場合の加速化の可能性を表しています。
私たちは主に、次のような4つの観察結果を得ました。

BERTアーキテクチャの興味深い点は、ほとんどの処理がトークンレベルで行われるため、私たちのパッキングに干渉しないということです。調整が必要になる要素はAttentionのマスク、MLM損失、NSP損失、精度の4つだけです。
異なった数のシーケンスに対応するための4つすべてのアプローチにおいて、ベクトル化と、連結可能な最大数のシーケンスを使用することが鍵でした。Attentionについては、パディングに対処するためのマスクがすでに用意されていました。次のTensorFlowの疑似コードで確認できるように、これを複数のシーケンスに拡張するのは簡単でした。Attentionが個別のシーケンスに限定され、それを超えてはならない仕組みになっています。
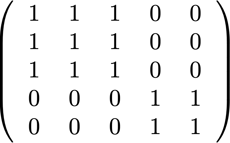
損失の計算は、原則としてシーケンスをアンパッキングして個別に損失を計算し、最終的には(パックではなく)シーケンス全体の損失の平均値を求めます。
MLM損失の場合、コードは次のようになります。
NSPの損失と精度については、原理は同じです。私たちが公開しているサンプルの中に、当社が開発したPopARTフレームワークを使ったそれぞれのコードがあります。
BERTを変更したことで、次のような2つの疑問が生まれました。
BERTのデータ作成は面倒なことがあるので、近道を使って、複数の異なるパッキング深さ用にコードをコンパイルし、それぞれの(測定された)サイクルを比較しました。その結果を表4に示します。「オーバーヘッド」では、パッキングを可能にするためにモデルを変更したことによるスループットの低下率を表しています(Attentionのマスキングスキームや変更された損失計算など)。「実現される高速化」は、パッキングによる高速化(「パッキング係数」)と「オーバーヘッド」によるスループットの低下を組み合わせた結果です。
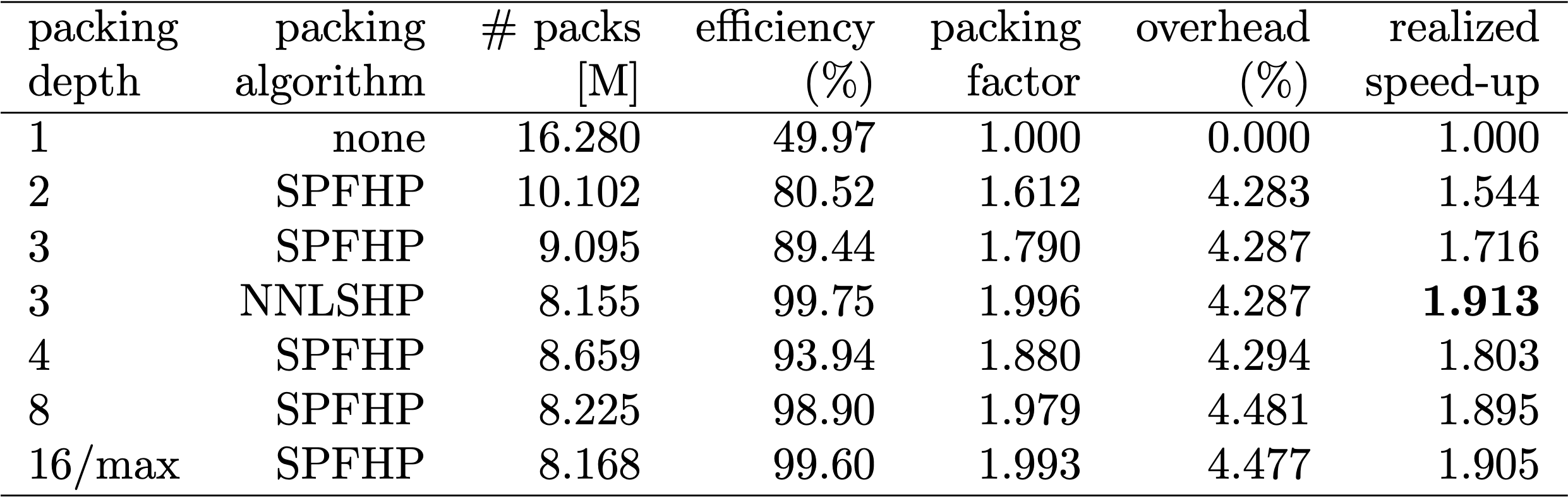
ベクトル化技術のおかげで、オーバーヘッドは驚くほど小さく、多くのシーケンスをまとめてもデメリットはありません。
私たちはパッキングを使って、有効なバッチサイズを(平均で)2倍にしています。つまり、学習のハイパーパラメータを調整する必要があります。簡単なトリックとして、勾配蓄積カウントを半分にして、学習前と同じ効果を持つ平均バッチサイズを維持する方法があります。事前に学習させたチェックポイントを用いてベンチマーク設定を行うことで、精度曲線が完全に一致していることがわかります。
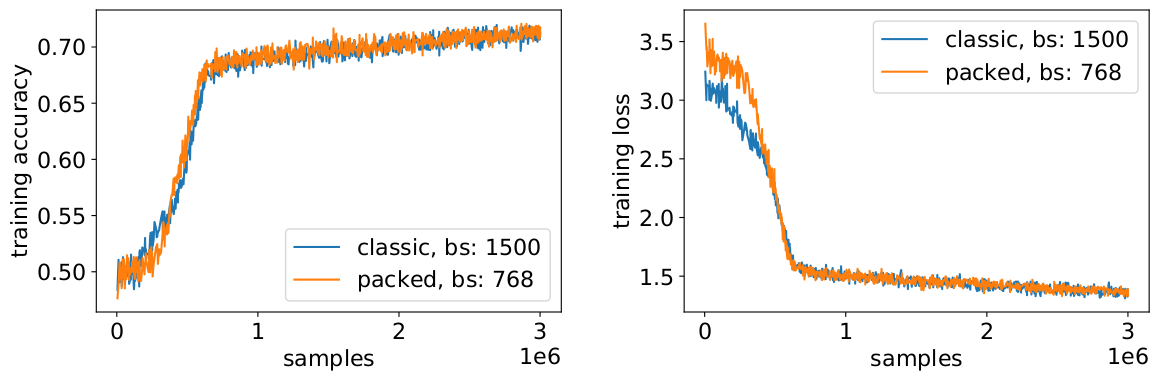
精度は一致しています。MLMの学習損失は、最初はわずかに違うかもしれませんが、すぐに追いつきます。この最初の違いは、前回の学習で短いシーケンスに偏っていたAttention層がわずかに調整されたことによるものと考えられます。
速度低下を避けるためには、元のバッチサイズをそのままにして、有効なバッチサイズの増加(2倍)に合わせてハイパーパラメータを調整することが役立つ場合があります。考慮すべき主なハイパーパラメータはベータパラメータと学習率です。一般的なアプローチとしてバッチサイズを2倍にする方法がありますが、この場合はパフォーマンスが低下します。LAMBオプティマイザの統計値を見ると、ベータパラメータをパッキング係数の累乗まで上げることは、モメンタムと速度を同等に保つために複数のバッチを連続して学習することに相当することが証明できました。
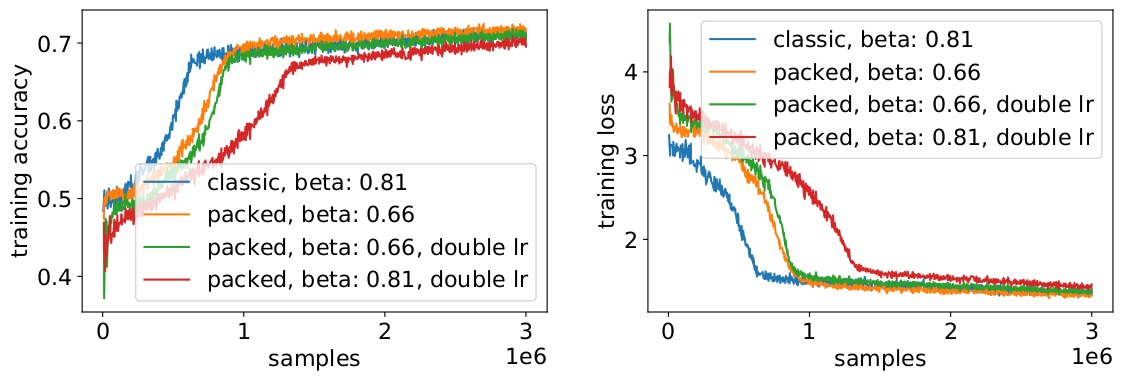
私たちの実験では、ベータ値を2の累乗にすることが良い経験則であることがわかりました。このシナリオでは、バッチサイズを大きくすると、目標とする精度に到達するまでのサンプル/エポック数の意味での収束速度が低下するため、曲線が一致することは期待できません。
そこで問題になるは、実践的なシナリオで期待通りの高速化が実際に得られるかどうかです。
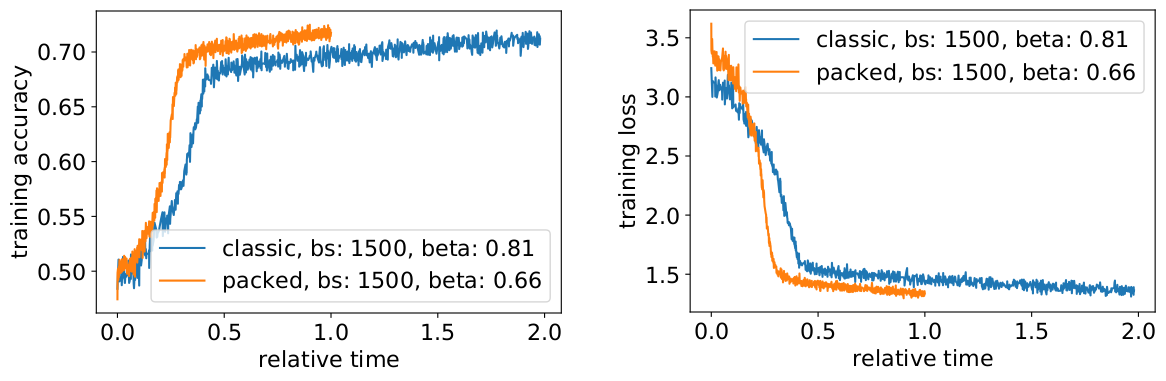
そう、得られるのです!データ転送を圧縮したことで、さらに高速化できました。
センテンスをまとめてパッキングすることによって、計算の手間も環境も節約できます。この手法は、PyTorchやTensorFlowを含むあらゆるフレームワークで実装できます。その結果、2倍の高速化を実現するとともに、パッキングアルゴリズムの技術を進化させることにも成功しました。
他にも、似たようなデータ分布が見られるゲノミクスやタンパク質の折り畳みなどのアプリケーションにも私たちは興味を持っています。またビジョントランスフォーマーも、異なるサイズのパッキングされた画像を応用できる、興味深い分野です。あなたはどのようなアプリケーションが有効だと思いますか?ぜひ、ご意見をお聞かせください!
今回の取り組みに貢献していただいたGraphcoreアプリケーションエンジニアリングチームのSheng Fu氏とMrinal Iyer氏に感謝いたします。また、貴重なフィードバックをいただいたGraphcoreリサーチチームのDouglas Orr氏にも感謝いたします。
共有: