Jun 30, 2021
Jun 30, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamWe are delighted to be sharing the results of Graphcore’s first ever training submission to MLPerf™, the AI industry’s most widely recognised comparative benchmarking process.
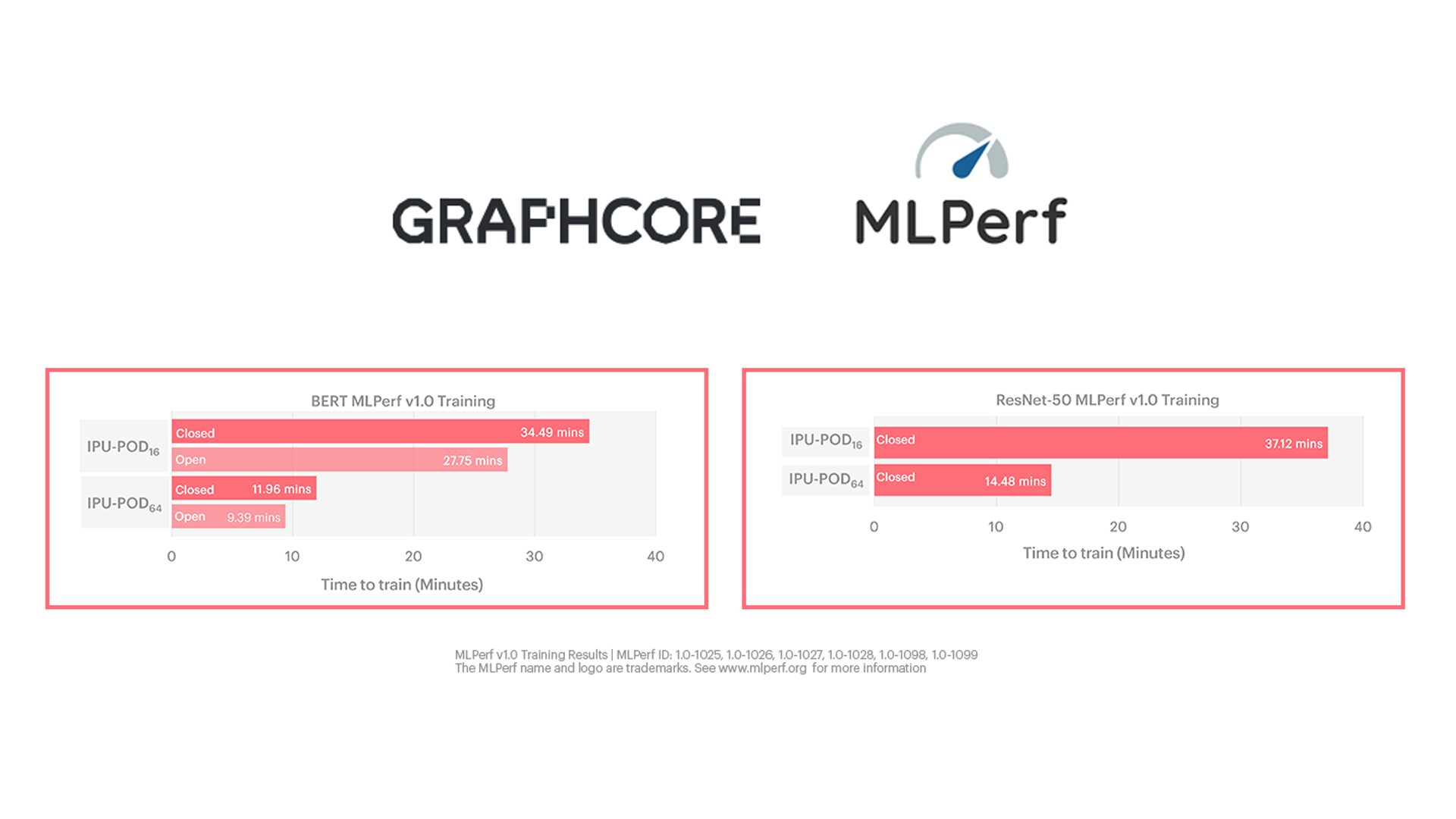
The results are outstanding, with a BERT time-to-train of just over 9 minutes and ResNet-50 time-to-train of 14.5 minutes on our IPU-POD64. This is supercomputer levels of AI performance.
MLPerf also shows how commercially available Graphcore systems stack up against the latest from NVIDIA, putting us firmly ahead on performance-per-dollar metrics.
For our customers, it is a significant third-party confirmation that Graphcore systems aren’t just designed to excel at next-generation AI, they’re also better at today’s most widely used applications.
There can now be no doubt that Graphcore, with our mature software stack, our innovative architecture and our highly performant systems, is the company to watch in AI compute.
MLPerf is overseen by MLCommons™, of which Graphcore is a founding member, alongside more than 50 other members and affiliates, non-profits and commercial companies from across the field of artificial intelligence.
The mission of MLCommons is to “accelerate machine learning innovation and to increase its positive impact on society” - an ambition that we fully support.
Training and inference results are published quarterly, on an alternating basis. Raw data for the latest training round, in which Graphcore participated, can be viewed here.
For our very first submissions to MLPerf (Training version 1.0), we have chosen to focus on the key application benchmark categories of Image Classification and Natural Language Processing.
The MLPerf Image classification benchmark uses the popular ResNet-50 version 1.5 model, trained on an ImageNet dataset to a defined accuracy that is common for all submissions.
For NLP, the BERT-Large model is used, with a segment taken that represents approximately 10% of the total training compute workload and is trained using a Wikipedia dataset.
Our decision to submit in image classification and NLP, with ResNet-50 and BERT, is driven in large part by our customers and potential customers, for whom these are some of the most commonly used applications and models.
Our strong performance in MLPerf is further evidence that our systems can deliver on today's AI compute requirements.
We submitted MLPerf training results for two Graphcore systems, the IPU-POD16 and IPU-POD64.
Both systems are already shipping to customers in production, so we entered them both in the ‘available’ category rather than preview – a significant achievement for our first ever MLPerf submission.
The IPU-POD16 is Graphcore’s compact, 5U, affordable system for enterprise customers beginning to build their IPU AI compute capability. Consisting of four 1U IPU-M2000s and a dual-CPU server, it offers four PetaFLOPS of AI processing power.
Our scale-up IPU-POD64, comprises 16 IPU-M2000s and a flexible number of servers. Because Graphcore systems disaggregate servers and AI accelerators, customers can specify the CPU-to-IPU ratio depending on the workload being undertaken. Computer vision tasks, for example, are typically more demanding of servers than natural language processing.
For MLPerf, the IPU-POD64 made use of a single server for BERT, and four servers for ResNet-50. Each server was powered by two AMD EPYC™ CPUs.
MLPerf has two divisions for submissions – open and closed.
The Closed division strictly requires submitters to use exactly the same model implementation and optimizer approach, which includes defining hyperparameter state and training epochs.
The Open division is designed to foster innovation by allowing more flexibility in the model implementation while ensuring exactly the same model accuracy and quality is reached as the Closed division. As a result, it supports faster model implementations, more tuned to different processor capabilities and optimizer approaches.
For an innovative architecture like our IPU, the open division is more representative of our performance, but we have chosen to submit in both the Open and Closed results divisions.
 The results show how well Graphcore systems perform, even on the out-the-box closed division, with its restrictive specifications.
The results show how well Graphcore systems perform, even on the out-the-box closed division, with its restrictive specifications.
Even more impressive are the results in the open division, where we are able to deploy the sort of optimisations that make the most of our IPU and system capabilities. These more closely reflect real-world use cases, where customers can take advantage of available performance improvements.
MLPerf is known as a comparative benchmark and is often referenced when attempting to evaluate one manufacturer’s technology against another.
In reality, making direct comparisons can be complex. Today’s processor and system architectures vary widely – from relatively simple silicon, up to complex stacked chips with expensive memory.
Like our customers, we find it most informative to look at the results on a performance-per-$ basis.
Graphcore’s IPU-POD16 is a 5U system, with a list price of $149,995. As we’ve already explained it is made up of four IPU-M2000 accelerators each with four IPU processors and a choice of industry standard host server. The NVIDIA DGX-A100 640GB used in MLPerf is a 6U box with a list price of around $300,000 (based on market intelligence and published reseller pricing) and eight DGX A100 chips. The IPU-POD16 is half the price and for those observers who try to cut the results by accelerator we can see that in this system, an IPU-M2000 is the same price as a single A100-80GB, or on a more granular level, one IPU is a quarter of the price.
In our MLPerf comparative analysis, we have taken the results from the tightly regulated closed division and normalised them for system price.
For both ResNet-50 and BERT, it is clear that Graphcore systems deliver significantly better performance-per-$ than NVIDIA’s offering.
In the case of ResNet-50 training on the IPU-POD16, this is a factor of 1.6x, while the Graphcore advantage for BERT is 1.3X.
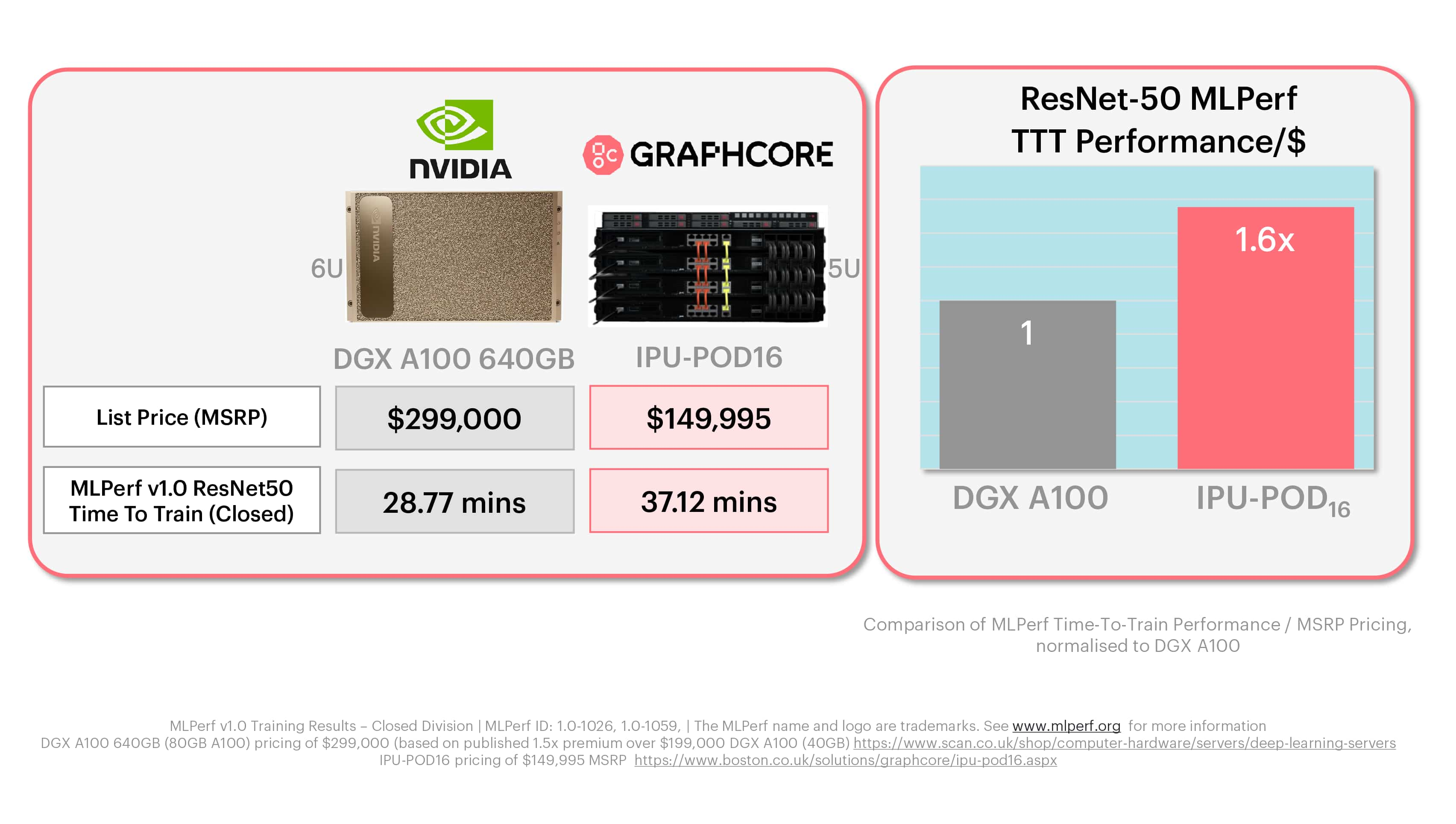
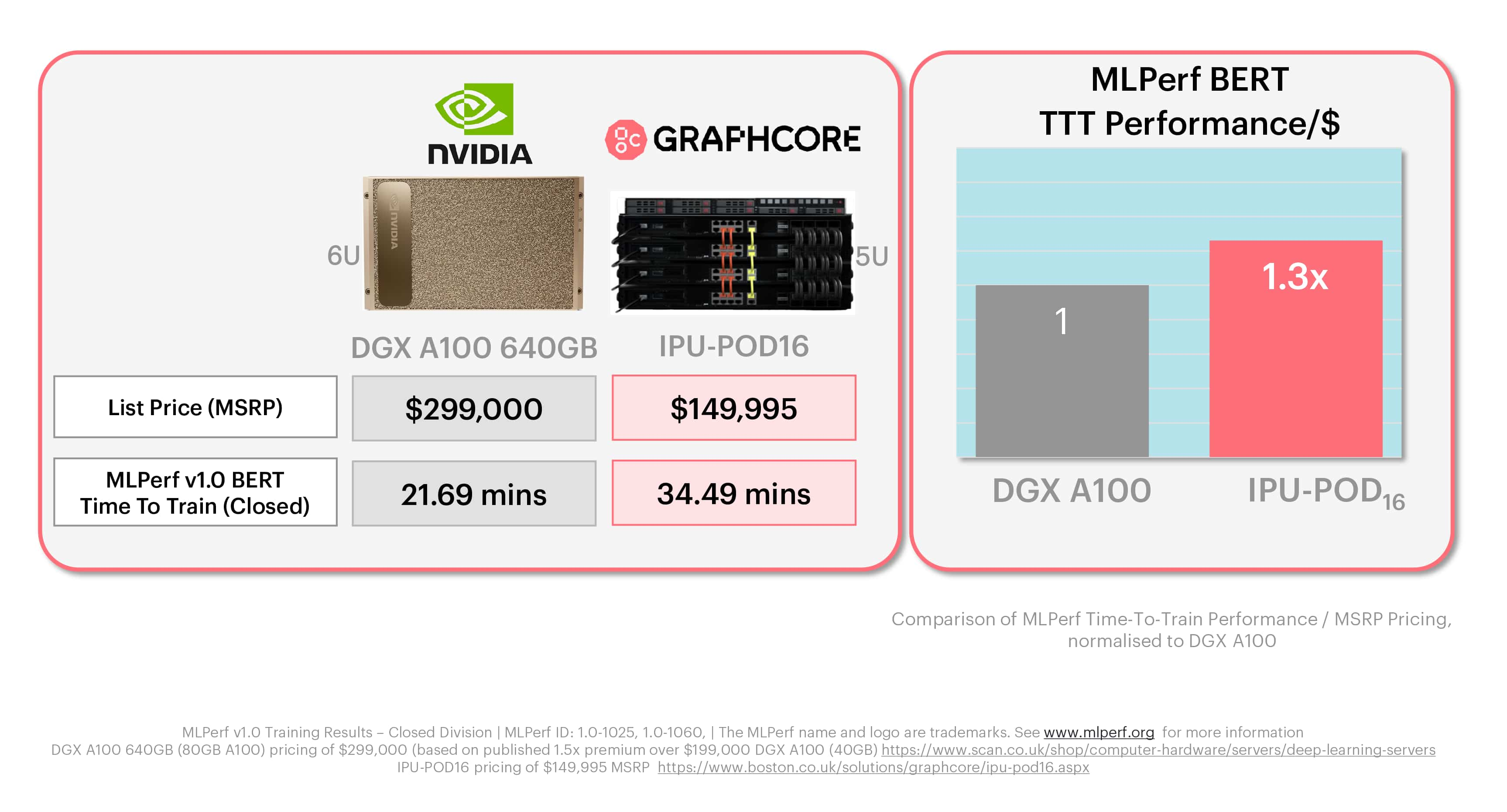 These MLPerf charts reflect what real Graphcore customers are finding – that the economics of our systems can better help them meet their AI compute goals, while also unlocking next-generation models and techniques, thanks to the IPU’s built-for-AI architecture.
These MLPerf charts reflect what real Graphcore customers are finding – that the economics of our systems can better help them meet their AI compute goals, while also unlocking next-generation models and techniques, thanks to the IPU’s built-for-AI architecture.
To have such a strong set of results for our first MLPerf submission is something we are extremely proud of. A small team of engineers from our Customer Engineering group, along with colleagues throughout the company, have worked extremely hard to get us to this point.
And there is a much wider value to our participation, as all of the improvements and optimisations that support our submission are now built into our software stack. Graphcore users around the world are already benefitting from the MLPerf dividend across far more models than BERT and ResNet-50.
We are committed to continued participation in MLPerf, across both training and inference rounds. And we do so in pursuit of three goals: better performance, greater scale and the addition of more models.
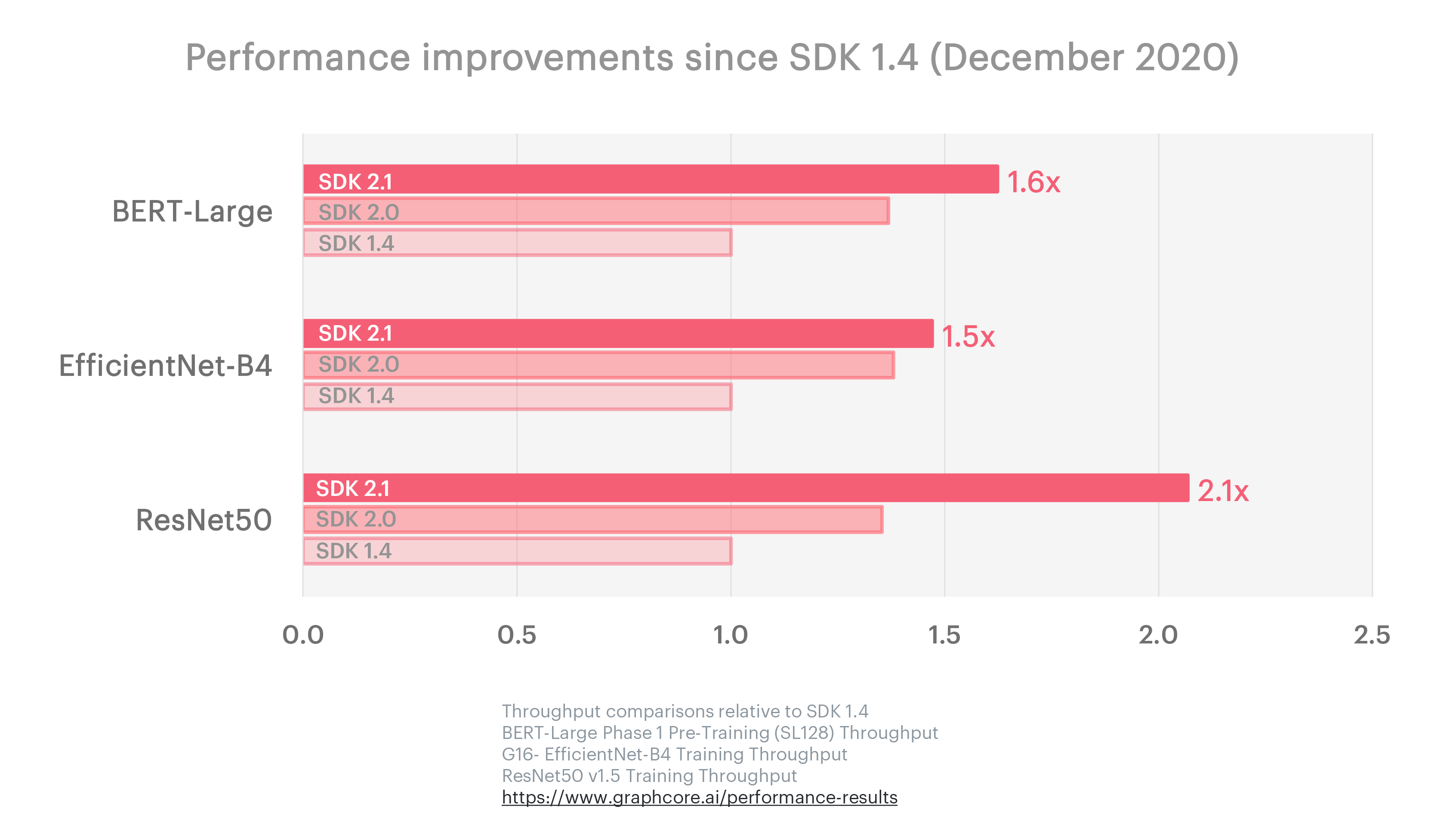
Our focus on continuous software improvement is also evident in the benchmark progress made across recent releases of the Poplar SDK. Over three updates in the six months from December 2020 to June 2021, we delivered a 2.1x performance improvement on ResNet-50, 1.6x improvement on BERT-Large and 1.5x on EfficientNet, the computer vision model with a focus on even higher accuracy than ResNet.
 Allied with our pursuit of continuous software improvement, Graphcore’s research team is also pushing the boundaries of what is possible with current and next generation models. Their recent publications on Making EfficientNet more efficient and Removing batch dependence in CNNs by proxy-normalising activations are directly related to work done in preparation for MLPerf, and benefit not just Graphcore customers, but the wider AI community.
Allied with our pursuit of continuous software improvement, Graphcore’s research team is also pushing the boundaries of what is possible with current and next generation models. Their recent publications on Making EfficientNet more efficient and Removing batch dependence in CNNs by proxy-normalising activations are directly related to work done in preparation for MLPerf, and benefit not just Graphcore customers, but the wider AI community.
Submitting to MLPerf first on ResNet-50 and BERT was important to show our performance on today’s most widely used AI models.
But Graphcore’s IPU and the systems that it powers were designed to excel at next-generation AI applications, and to enable users to develop new models and techniques, free from the limitations of legacy processor architectures.
One such model is EfficientNet-B4, a more advanced, but still widely used computer vision model that illustrates the widening gap between the IPU and GPU, in terms of performance-per-dollar.
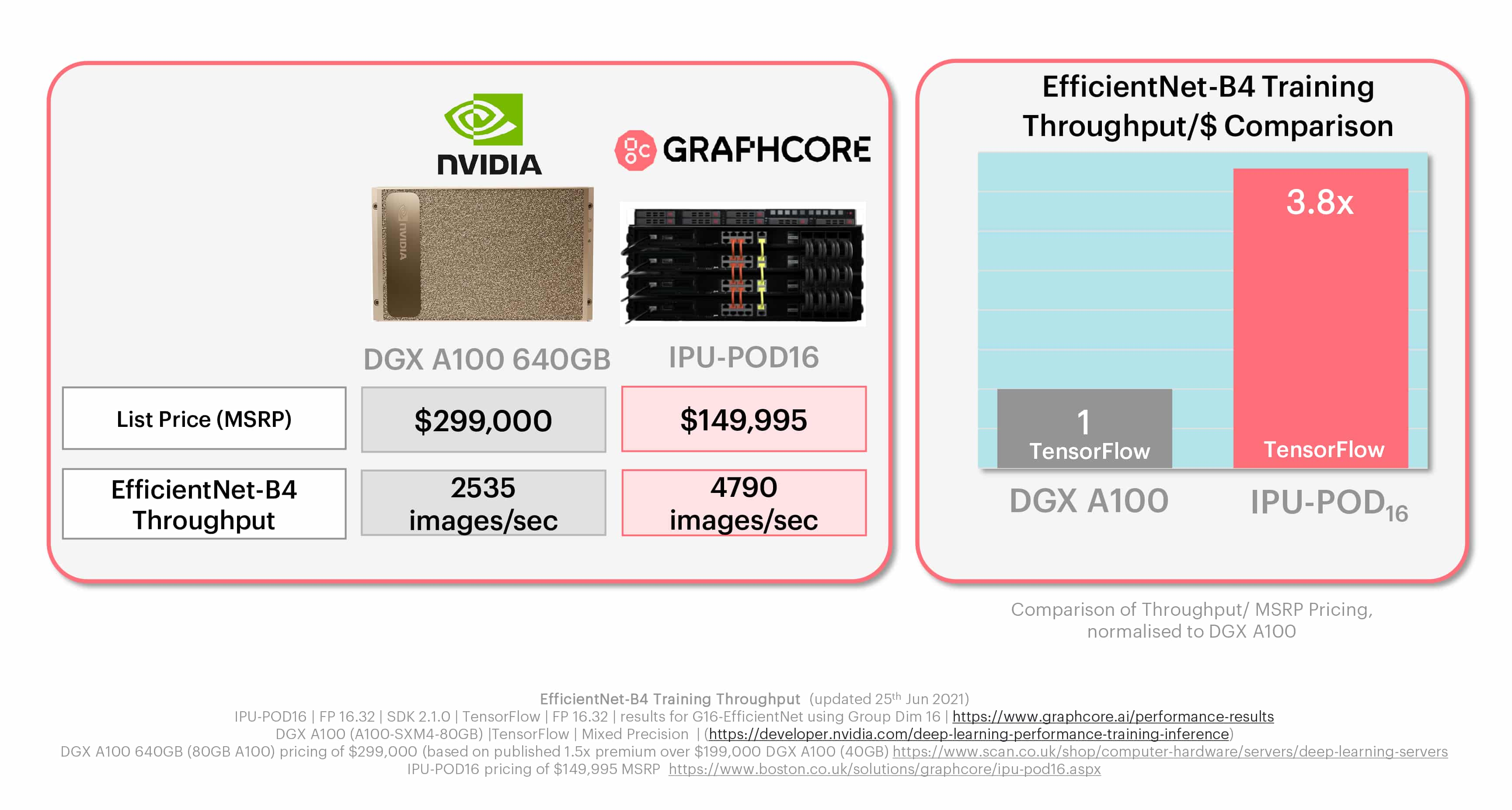 We believe that customers and the AI industry will benefit from MLPerf continuing to keep pace with such innovative models, while also reflecting the most common use cases of today.
We believe that customers and the AI industry will benefit from MLPerf continuing to keep pace with such innovative models, while also reflecting the most common use cases of today.
Graphcore will be an active and progressive member of MLCommons for the benefit of those who use our technology, as well as those who don’t.
For now, we are extremely happy with our first submission, and are already preparing for the next.
Share:


