
Jun 14, 2022 \ Machine Learning
Jun 14, 2022 \ Machine Learning
공유:
마이클 브론스타인(Michael Bronstein)은 영국 옥스퍼드 대학의 인공지능(딥마인드) 교수이자 트위터(Twitter)의 그래프 학습 연구 책임자입니다. 마이클 브론스타인 교수는 트위터의 머신러닝 연구원 에마누엘 로시(Emanuele Rossi), 그리고 그래프코어의 연구 과학자 다니엘 저스투스(Daniel Justus)와 함께 이 글을 공동 집필했습니다.
그래프 구조 데이터는 엔티티가 상호작용하는 복잡한 시스템을 다루는 많은 애플리케이션에서 나타나는데요. 특히, 최근 몇 년 사이 그래프 신경망(GNN)과 같은 그래프 구조 데이터에 머신 러닝을 적용하는 방법이 큰 관심을 끌고 있습니다.
대부분의 GNN 아키텍처는 그래프가 고정되어 있다고 가정합니다. 하지만 이 가정은 너무 단순할 때가 많습니다. 많은 애플리케이션에서 기반 시스템이 동적으로 움직이기 때문에 그래프가 시간에 따라 변하게 되는데요. 예를 들어, 소셜 네트워크 혹은 추천 시스템에서는 사용자와 콘텐츠의 상호작용을 나타내는 그래프가 실시간으로 변하는 것을 볼 수 있습니다. 최근 들어 동적 그래프를 처리할 수 있는 여러 GNN 아키텍처가 개발되고 있는데요, 여기에는 트위터의 TGN(Temporal Graph Networks)도 포함이 됩니다[1].
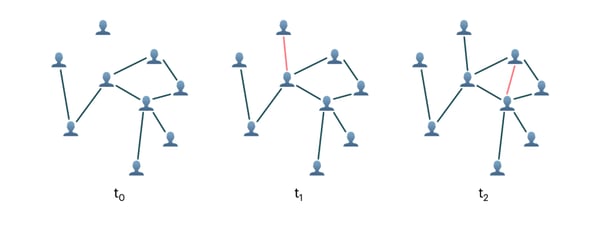
사람들 간의 상호작용 그래프는 타임스탬프 t1 및 t2에서 새로운 엣지(edge)를 얻음으로써 동적으로 변합니다.
해당 포스팅에서는 다양한 크기의 동적 그래프에 TGN을 적용하는 방법을 살펴보고, 대규모 모델이 갖는 연산 복잡성에 대해 자세히 알아보고자 합니다. 이번 연구에서는 TGN 훈련에 그래프코어의 Bow IPU를 사용했습니다. 이를 통해, IPU 아키텍처가 이러한 복잡성을 해결하는데 이상적인 이유를 밝힐 수 있었는데요. 실제로, 단일 IPU 프로세서는 엔비디아 A100 GPU와 비교해 훨씬 빠른 속도를 제공하는 것으로 나타납니다.
TGN 아키텍처는 두 가지 주요 구성요소로 이루어져 있습니다. 먼저, 노드 임베딩은 단일 레이어 GAN(Graph Attention Network)으로 구현된 전형적인 GNN 아키텍처를 통해 생성됩니다[2]. 또한 TGN은 각 노드의 모든 과거 상호작용을 요약하는 메모리를 유지합니다. 이 스토리지는 스파스(sparse) 읽기 및 쓰기 작업을 통해 액세스되며, GRU(Gated Recurrent Network)를 통한 새로운 상호작용으로 업데이트됩니다[3].
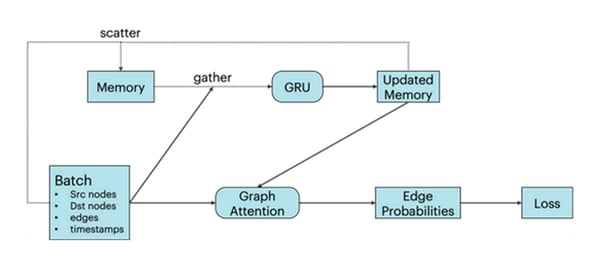
TGN 모델 아키텍처: 하단 행은 단일 메시지 전달 단계가 있는 GNN을 나타내고, 상단 행은 그래프의 각 노드에 대한 추가 메모리를 나타냅니다.
해당 연구는 새로운 엣지를 얻음으로써 시간에 따라 변하는 그래프에 초점을 맞추고 있는데요. 이 경우 특정 노드에 대한 메모리에는 이 노드와 해당 노드를 대상으로 하는 모든 엣지에 대한 정보가 포함됩니다. 특정 노드의 메모리는 간접 기여를 통해 더 멀리 있는 노드에 대한 정보를 보유할 수 있으므로, GAN의 추가 레이어가 필요하지 않습니다.
해당 연구에서는 우선 위키피디아(Wikipedia) 문서와 사용자의 이분 그래프인 JODIE Wikipedia 데이터세트[4]를 사용해 TGN을 실험했습니다. 여기서 사용자와 문서 사이의 각 엣지는 사용자의 문서 편집을 나타냅니다. 그래프는 9,227개의 노드(8,227명의 사용자와 1,000개의 문서)와 타임스탬프가 있는 157,474개의 엣지로 구성되며, 편집 내용을 설명하는 172 차원의 LIWC 특징벡터[5]가 주석으로 표시되어 있습니다.
훈련 과정에서 엣지는 처음에 연결되지 않은 노드 집합에 배치별로 삽입되는 반면, 모델은 실제 엣지와 무작위로 샘플링된 네거티브 엣지의 대조 손실(contrastive loss)을 통해 훈련됩니다. 검증 결과는 무작위로 샘플링된 네거티브 엣지에서 실제 엣지를 식별할 수 있는 확률로 보고됩니다.
직감적으로 알 수 있듯이, 배치 크기가 클 수록 훈련 및 추론 모두에 안 좋은 결과를 가져옵니다. 노드 메모리와 그래프 연결은 둘 다 전체 배치가 처리된 후에만 업데이트됩니다. 따라서 한 배치 내에서 이후 이벤트는 해당 배치의 이전 이벤트를 알지 못하기 때문에 오래된 정보에 의존할 수 있습니다. 실제로 아래 그림에서 배치 크기와 작업성능은 반비례 관계를 갖는 것을 볼 수 있습니다.
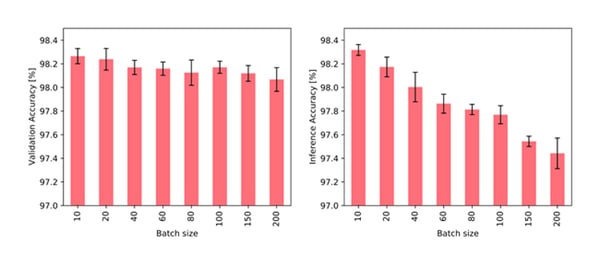
다양한 배치 크기로 훈련하고 고정 배치 크기 10으로 검증할 때(왼쪽)와 고정 배치 크기 10으로 훈련하고 다양한 배치 크기로 검증할 때(오른쪽)의 JODIE/Wikipedia 데이터에 대한 TGN의 정확도
하지만, 배치 크기가 작은 경우에는 훈련 및 추론 과정에서 높은 처리량을 유지하기 위한 신속한 메모리 액세스가 중요합니다. 아래 그림4에서 확인할 수 있듯이, 대규모 인프로세서 메모리가 탑재된 IPU는 배치 크기가 더 작은 GPU보다 더 많은 처리량을 달성할 수 있습니다. 특히 배치 크기 10을 사용할 경우 TGN은 IPU에서 11배 더 빠르게 훈련할 수 있으며, 더 큰 배치 크기인 200을 사용하더라도 IPU에서의 훈련 속도는 여전히 약 3배 더 빠릅니다.
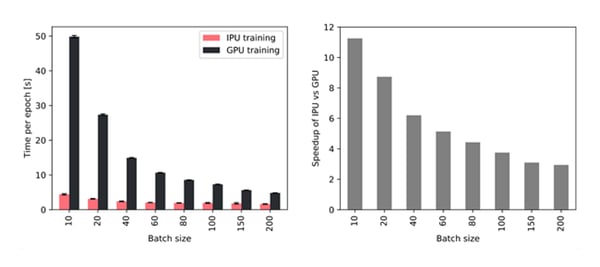
엔비디아 A100 GPU와 비교하여, Bow2000 IPU 시스템에서 단일 IPU를 사용할 경우 다양한 배치 크기에 따른 처리량 향상 정도
그래프코어의 IPU에서 구현되는 TGN 훈련의 처리량 향상을 자세히 이해하기 위해 TGN의 주요 작업에서 다양한 하드웨어 플랫폼이 소요한 시간을 조사했는데요. 특히, Attention 모듈과 GRU 작업에서 IPU는 GPU의 성능을 월등히 능가하는 것을 발견할 수 있었습니다. 또한 모든 작업에 걸쳐, IPU는 작은 배치를 훨씬 더 효율적으로 처리하는 것으로 나타났습니다.
특히 메모리 작업이 더 작아지고 세분화될수록 IPU의 장점이 배가되는 것이 관찰됐습니다. 일반적으로, IPU 아키텍처는 컴퓨팅 및 메모리 액세스가 매우 이질적일 때 GPU 대비 상당한 이점을 보인다는 결론을 내릴 수 있었습니다.
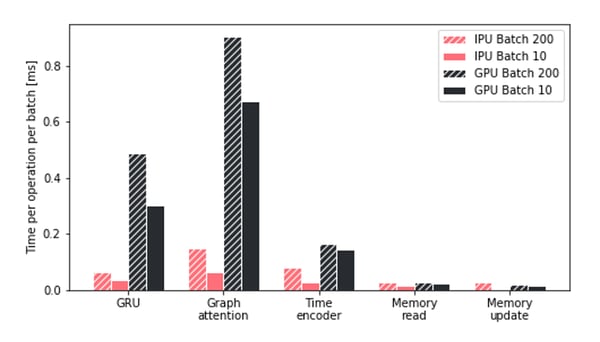
배치 크기가 다를 때 IPU및 GPU에서 소요되는 TGN작업시간 비교
기본 구성의 TGN 모델은 매개변수가 약 260,000개로 비교적 가벼운 반면, 이 모델을 큰 그래프에 적용하면 대부분의 IPU 인프로세서 메모리는 노드 메모리에서 사용됩니다. 하지만 액세스 빈도가 낮기 때문에 이 텐서는 오프칩 메모리로 이동할 수 있으며, 이 경우 인프로세서 메모리 사용률은 그래프 크기와 무관합니다.
큰 그래프에서 TGN 아키텍처를 테스트하기 위해 1,550만 명의 트위터 사용자[6] 사이의 2억 6,100만 팔로우가 포함된 익명화된 그래프에 적용했습니다. 엣지에는 날짜 순서를 따르긴 하지만 팔로우가 발생한 실제 날짜에 대한 정보는 제공하지 않는 728개의 서로 다른 타임스탬프가 할당됐습니다. 이 데이터세트에는 노드 또는 엣지 기능이 없기 때문에 모델은 그래프 토폴로지와 시간 변화(temporal evolution)에 전적으로 의존하여 새 링크를 예측했습니다.
데이터 양이 많으면 네거티브 샘플과 비교하여 포지티브 엣지를 식별하는 작업이 너무 단순해지므로, 무작위로 샘플링된 1,000개의 네거티브 엣지 중에서 실제 엣지의 MRR(Mean Reciprocal Rank)을 유효성 검사 메트릭으로 사용했습니다. 또한, 데이터세트 크기가 커지면 은닉 크기(hidden size)가 커져 모델 성능이 향상된다는 점을 알 수 있었습니다. 또한 주어진 데이터에 대한 정확도와 처리량 사이의 가장 적절한 잠재적 크기는 256인것으로 확인했습니다.
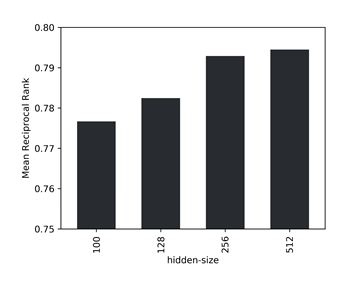
모델의 다양한 은닉 크기에 대한 1,000개의 네거티브 샘플 간의 MRR(Mean Reciprocal Rank)
노드 메모리에 오프칩 메모리를 사용하면 처리량이 약 2배 감소합니다. 하지만 노드 수가 트위터 그래프의 10배이자 무작위 연결이 포함된 합성 데이터세트와 다양한 크기의 유도 하위 그래프를 사용한 결과, 처리량이 그래프 크기와 거의 무관함을 알 수 있었습니다(표 1). IPU에서 이러한 기술을 사용하면 TGN을 거의 임의의 그래프 크기에 적용할 수 있는데요. 이는 사용 가능한 호스트 메모리의 양에 의해서만 제한되며, 훈련 및 추론 동안 매우 높은 처리량을 유지할 수 있음을 의미합니다.
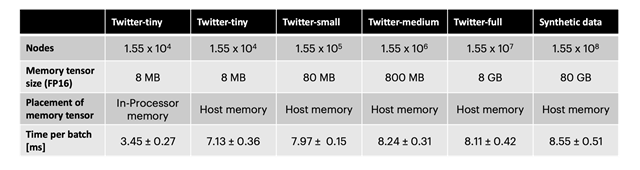
다양한 그래프 크기에서 은닉 크기 256으로 TGN을 훈련할 때 배치 크기 256당 소요되는 시간입니다. Twitter-tiny는 JODIE/Wikipedia 데이터 세트와 비슷한 크기입니다.
그래프 머신 러닝 모델을 구현하기 위한 하드웨어 선택은 매우 중요한 사안임에도 불구하고 종종 간과되곤 합니다. 특히, 연구 커뮤니티 사이에서 하드웨어를 추상화하는 클라우드 컴퓨팅 서비스 도입이 확대되면서, 하드웨어를 선택하는데 있어 일종의 "게으름”이 나타나고 있습니다. 그러나 실시간 레이턴시를 필요로 하는 대규모 데이터세트에서 작동하는 시스템을 구현하는 경우에는 하드웨어를 단순하게 생각해서는 안됩니다. 이번 연구가 이 중요한 주제에 대한 더 많은 관심을 촉구하는 동시에, 그래프 머신 러닝 애플리케이션을 위한 보다 효율적인 알고리즘과 하드웨어 아키텍처가 탄생할 수 있는 포문을 열수 있기를 바라는 바입니다.
[1] E. Rossi et al., Temporal graph networks for deep learning on dynamic graphs (2020) arXiv:2006.10637. See accompanying blog post.
[2] P. Veličković, et al., Graph attention networks (2018) ICLR.
[3] K. Cho et al., On the properties of neural machine translation: Encoder-Decoder approaches (2014), arXiv:1409.1259.
[4] S. Kumar et al., Predicting dynamic embedding trajectory in temporal interaction networks (2019) KDD.
[5] J. W. Pennebaker et al., Linguistic inquiry and word count: LIWC 2001 (2001). Mahwah: Lawrence Erlbaum Associates 71.
[6] A. El-Kishky et al., kNN-Embed: Locally smoothed embedding mixtures for multi-interest candidate retrieval (2022) arXiv:2205.06205.
공유:


