Dec 12, 2021
Dec 12, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamAt Wave Summit+ 2021 Deep Learning Developer Summit, Graphcore and PaddlePaddle formally announced support on the PaddlePaddle framework for Graphcore’s IPU hardware. Developers programming with the PaddlePaddle framework can now choose IPU hardware for AI training or inference. Graphcore officially joined the PaddlePaddle hardware ecosystem in May 2020 and is an important partner of PaddlePaddle for cloud training and inference.
PaddlePaddle is Baidu's open-source, commercial deep learning framework, which is widely used inside Baidu's internal business and within the AI industry. Today, the PaddlePaddle community is made up of over 4 million developers and provides services for 157,000 businesses. More than 476,000 models have been created based on the PaddlePaddle open-source deep learning platform. For a long time, PaddlePaddle has helped developers to realize AI concepts faster, accelerate the launch of AI services, and help more and more industries leverage the power of AI to advance their machine learning applications.
PaddlePaddle’s architecture is exceptionally well designed. Its core AI compiler has a well-defined IR (Intermediate Representation) system and an IR Pass system for graph optimization. Being a mature AI framework, PaddlePaddle has excellent scalability. Developers can support new hardware types by extending new Device types, new Operators, new Passes, and new Executors.
During the development process, the Graphcore R&D team used the IR layer of PaddlePaddle as an entry point to support the IPU. The aim was to minimize intrusive modifications to the native code of the PaddlePaddle framework, and instead increase it incrementally by extending the IR Pass and the Operator development as much as possible to reduce the impact on the original PaddlePaddle code logic.
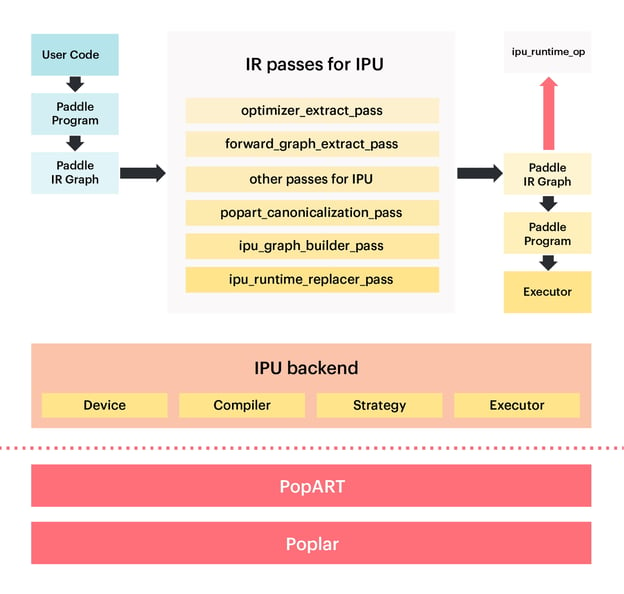
Today, Graphcore's IPU not only supports large-scale model training tasks through PaddlePaddle, but also supports high-performance inference tasks through the Paddle Inference library.
Pretrain Phase1(sequence_length=128):
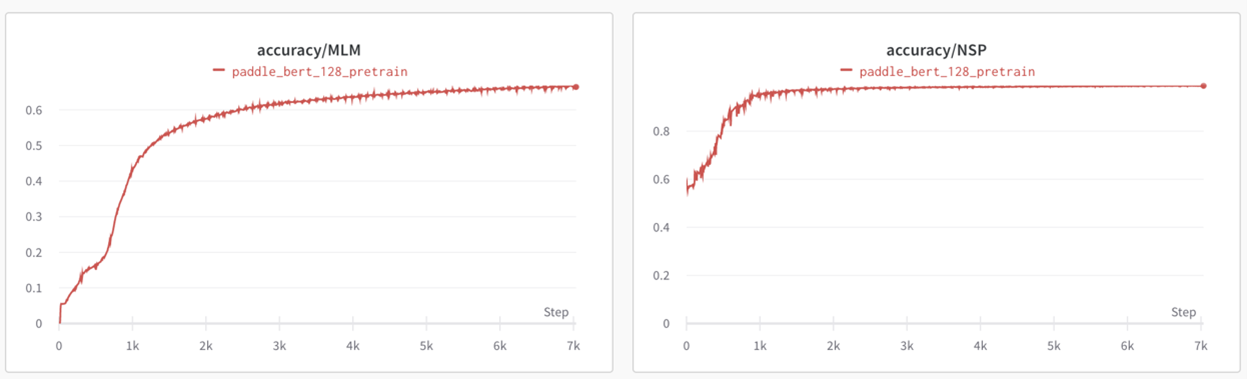
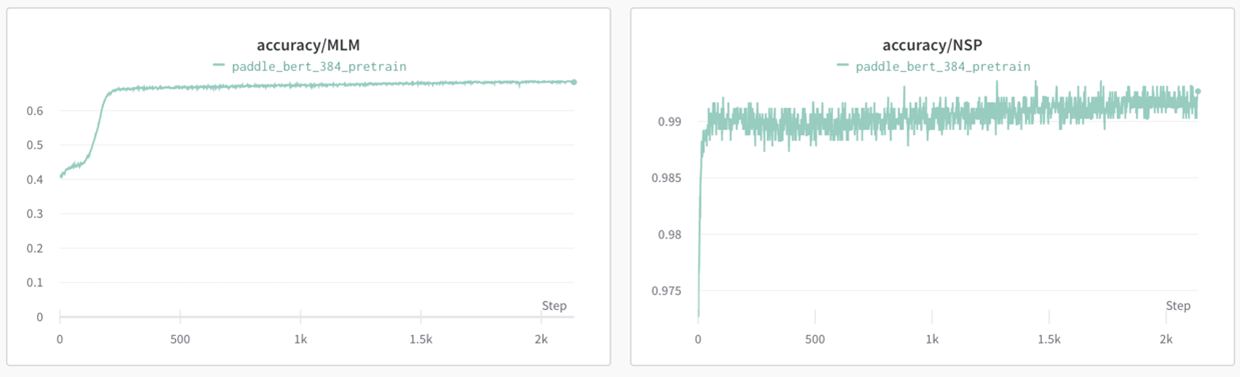
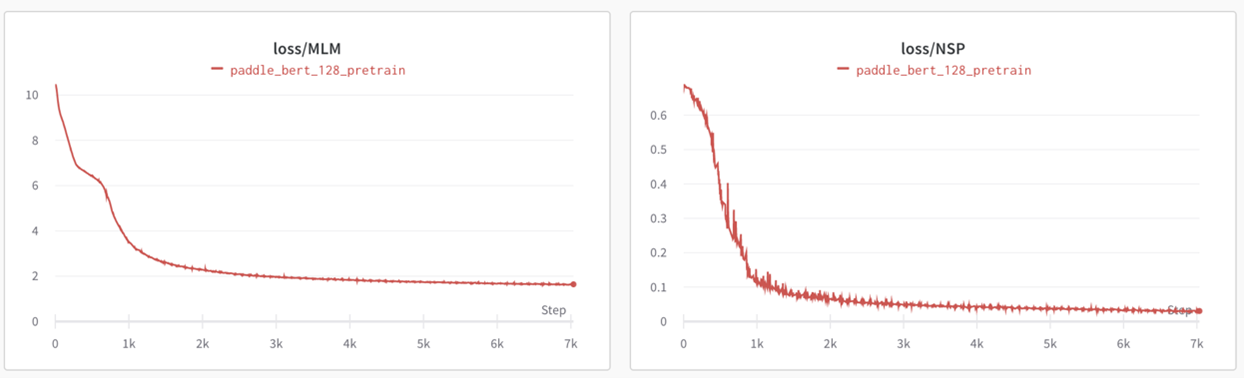 Pretrain Phase2(sequence_length=384):
Pretrain Phase2(sequence_length=384):
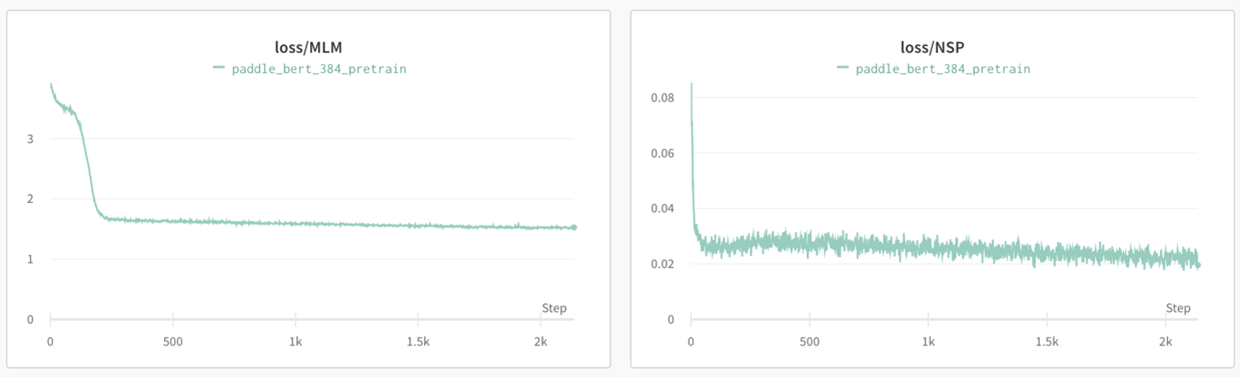 SQuAD:
SQuAD:
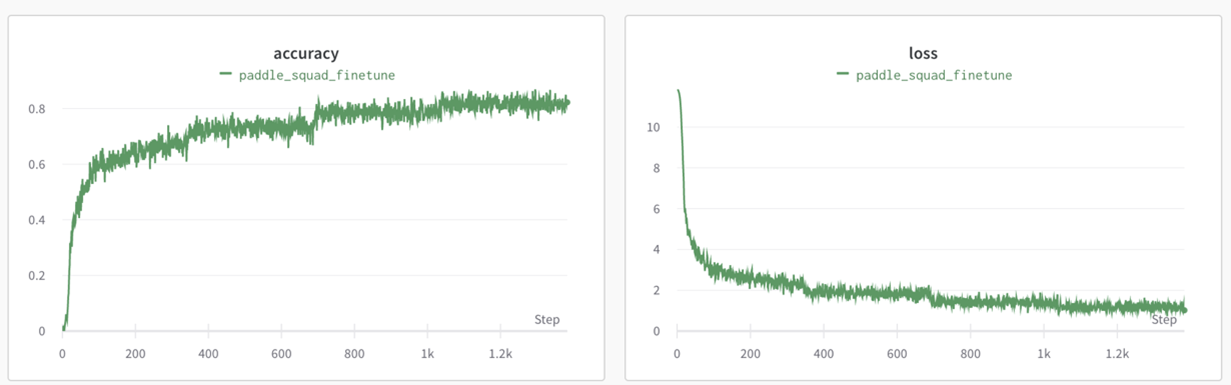

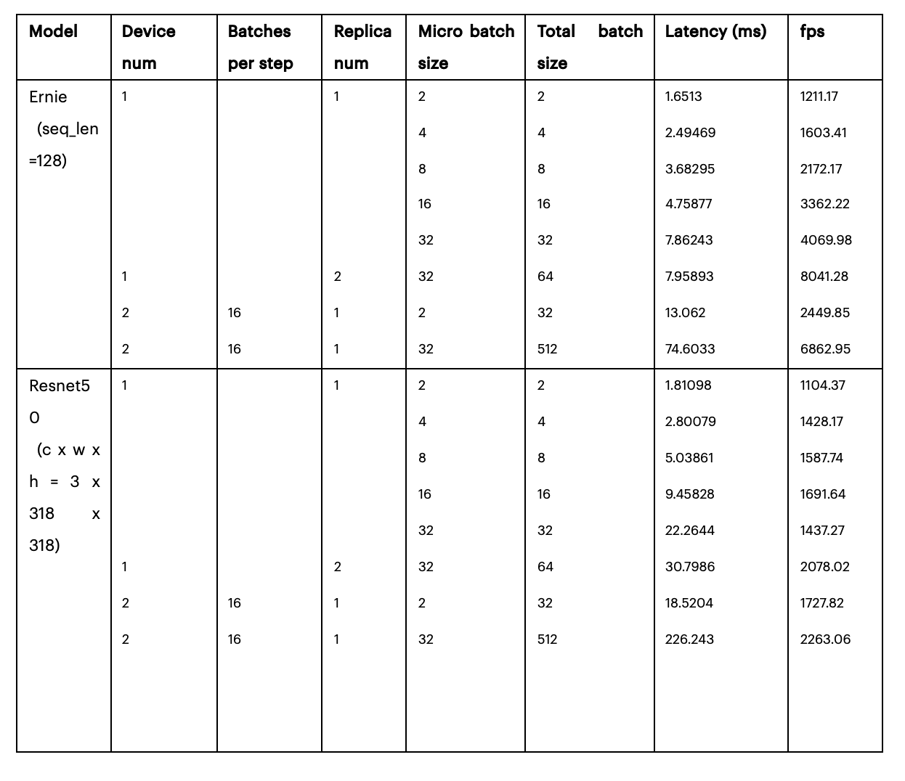
PaddlePaddle Inference(FP16)
Graphcore’s Poplar SDK has certain hardware, operating system and software environment requirements. For details, please refer to our documentation.
# Download Source Codegit clone -b paddle_bert_release https://github.com/graphcore/Paddle.git# Build Docker Imagedocker build -t paddlepaddle/paddle: dev-ipu-2.3.0 \-f tools/dockerfile/Dockerfile.ipu .# Create and Run Docker ContainerIPU relies on the ipu.conf configuration file for partitioning, and an available ipu.conf is required to obtain IPU devices. If ipu.conf is not available, please refer to the following command to generate it.For example: to generate POD16 (16 IPUs) configuration files:vipu create partition ipu --size 16ipu.conf will be generated in the following path:ls ~/.ipuof.conf.d/Please replace ${HOST_IPUOF_PATH} in the following command with the absolute path of ipu.conf in the host.docker run --ulimit memlock=-1:-1 --net=host --cap-add=IPC_LOCK \--device=/dev/infiniband/ --ipc=host --name paddle-ipu-dev \-v ${HOST_IPUOF_PATH}:/ipuof \-e IPUOF_CONFIG_PATH=/ipuof/ipu.conf \-it paddlepaddle/paddle:dev-ipu-2.3.0 bashNote: All subsequent operations are performed in the container.
# Verify IPU device#You can view all the current IPU devices and the ID of the IPU device in use by the following command:gc-monitorThe following picture shows that the IPU device can be obtained normally. If it cannot be obtained, please check whether the correct ipu.conf is provided.
# Compile PaddlePaddlegit clone -b paddle_bert_release: https://github.com/PaddlePaddle/Paddle.gitcd Paddlecmake -DPYTHON_EXECUTABLE=/usr/bin/python \-DWITH_PYTHON=ON -DWITH_IPU=ON -DPOPLAR_DIR=/opt/poplar \-DPOPART_DIR=/opt/popart -G "Unix Makefiles" -H`pwd` -B`pwd`/buildcmake --build \`pwd`/build --config Release --target paddle_python -j$(nproc)
# Installation Instructionpip install -U build/python/dist/paddlepaddle-0.0.0-cp37-cp37m-linux_x86_64.whl# Verification and Installationpython -c "import paddle; print(paddle.fluid.is_compiled_with_ipu())"# Expected Results:> True
Check out the code for this example on GitHub here
Bert-Base Training includes the following tasks:1. phase 1: sequence length=128 pre-training2. phase 2: sequence length=384 pre-trainig3. SQuAD fine-tune4. SQuAD validationData preparation:1. Pre-train dataset (data generated by script provided by NVIDIA)git clone https://github.com/NVIDIA/DeepLearningExamples.gitcd DeepLearningExamples/TensorFlow/LanguageModeling/BERTbash scripts/docker/build.sh cd data/ vim create_datasets_from_start.shModify line 40 --max_seq_length 512 to --max_seq_length 384Modify line 41 -- max_predictions_per_seq 80 to--max_predictions_per_se 56cd ../
Tfrecord input data with sequence_length=128 and 384 will be generated.2. SQuAD dataset# Fine-tune datasetcurl --create-dirs -L https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json -o data/squad/train-v1.1.json # Validation datasetcurl --create-dirs -L https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json -o data/squad/dev-v1.1.jsonPaddleNLP:In addition to relying on Paddlepaddle (installed above), this example also relies on PaddleNLP for model building and data processing. Please install PaddleNLP through the following operations:#Installation reliance:pip3.7 install jieba h5py colorlog colorama seqeval multiprocess numpy==1.19.2 paddlefsl==1.0.0 six==1.13.0 wandbpip3.7 install torch==1.7.0+cpu -f https://download.pytorch.org/whl/cpu/torch_stable.htmlpip3.7 install torch-xla@https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.7-cp37-cp37m-linux_x86_64.whlInstall PaddleNLPpip3.7 install git+https://github.com/graphcore/PaddleNLP.git@paddle_bert_releaseRun:Modify the --input_dir in run_stage.sh to the corresponding input data path:Phase1: The storage path of the tfrecord(sequence_length=128) file;Phase2: The storage path of the tfrecord(sequence_length=384) file;Fine-tune: storage path of train-v1.1.json;Validation: the storage path of dev-v1.1.json;run_stage.sh has 4 parameters:device: ipu or cpustage: phase1, phase2, SQuAD or validationinput_pdparams: path + prefix of imported pdparamsoutput_pdparams: path + prefix of exported pdparamsNote: The program uses wandb to record running data. The following prompt will pop up when running, and you need to select the corresponding mode to run. If there is no wandb account, please enter 3.#Run Phase1:#phase1 No need to import params, initialize weights randomly./run_stage.sh ipu phase1 _ pretrained_128_model#Run Phase2:#phase2 needs to import params trained in phase1 ./run_stage.sh ipu phase2 pretrained_128_model pretrained_384_model#Run SQuAD fine-tune:#fine-tune needs to import params trained in phase2 ./run_stage.sh ipu SQuAD pretrained_384_model finetune_model#Run validation:./run_stage.sh ipu validation finetune_model _
#Generate Paddle inference libraryBased on the previous Paddlepaddle compilation command, -DON_INFER=ON is added. After the compilation is completed, the paddle_inference_install_dir directory will be generated in the build directory. This directory is the Paddle inference library directory.cmake -DPYTHON_EXECUTABLE=/usr/bin/python \-DWITH_PYTHON=ON –DON_INFER=ON -DWITH_IPU=ON -DPOPLAR_DIR=/opt/poplar \-DPOPART_DIR=/opt/popart -G "Unix Makefiles" -H`pwd` -B`pwd`/build cmake --build \`pwd`/build --config Release --target paddle_python -j$(nproc)The directory is as follows: #You can refer to the following ipu_word2vec_sample.cc to use Paddle inference library for inference:
#You can refer to the following ipu_word2vec_sample.cc to use Paddle inference library for inference:
Download the model:
wget -q http://paddle-inference-dist.bj.bcebos.com/word2vec.inference.model.tar.gz
/* Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at: http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
/*
* This file contains a simple demo for how to take a model for inference with IPUs.
*/
#include <iostream>
#include <vector>
#include <numeric>
#include <string>
#include "paddle/fluid/inference/api/paddle_inference_api.h"
#include "gflags/gflags.h"
#include "glog/logging.h"
DEFINE_string(infer_model, "", "Directory of the inference model.");
using paddle_infer::Config;
using paddle_infer::Predictor;
using paddle_infer::CreatePredictor;
void inference(std::string model_path, bool use_ipu, std::vector<float> *out_data) {
//# 1. Create Predictor with a config.
Config config;
config.SetModel(FLAGS_infer_model);
if (use_ipu) {
// ipu_device_num, ipu_micro_batch_size
config.EnableIpu(1, 4);
}
auto predictor = CreatePredictor(config);
//# 2. Prepare input/output tensor.
auto input_names = predictor->GetInputNames();
std::vector<int64_t> data{1, 2, 3, 4};
// For simplicity, we set all the slots with the same data.
for (auto input_name : input_names) {
auto input_tensor = predictor->GetInputHandle(input_name);
input_tensor->Reshape({4, 1});
input_tensor->CopyFromCpu(data.data());
}
//# 3. Run
predictor->Run();
//# 4. Get output.
auto output_names = predictor->GetOutputNames();
auto output_tensor = predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_tensor->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1,
std::multiplies<int>());
out_data->resize(out_num);
output_tensor->CopyToCpu(out_data->data());
}
int main(int argc, char *argv[]) {
::GFLAGS_NAMESPACE::ParseCommandLineFlags(&argc, &argv, true);
std::vector<float> ipu_result;
std::vector<float> cpu_result;
inference(FLAGS_infer_model, true, &ipu_result);
inference(FLAGS_infer_model, false, &cpu_result);
for (size_t i = 0; i < ipu_result.size(); i++) {
CHECK_NEAR(ipu_result[i], cpu_result[i], 1e-6);
}
LOG(INFO) << "Finished";
}
Compilation method:
CMakeList.txt:
cmake_minimum_required(VERSION 3.0)
project(cpp_inference_demo CXX C)
include_directories("${PADDLE_LIB}/")
set(PADDLE_LIB_THIRD_PARTY_PATH "${PADDLE_LIB}/third_party/install/")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}protobuf/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}glog/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}gflags/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}xxhash/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}cryptopp/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}mkldnn/include")
include_directories("${PADDLE_LIB_THIRD_PARTY_PATH}mklml/include")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}protobuf/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}glog/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}gflags/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}xxhash/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}cryptopp/lib")
link_directories("${PADDLE_LIB_THIRD_PARTY_PATH}ipu")
link_directories("/opt/poplar/lib")
link_directories("/opt/popart/lib")
link_directories("${PADDLE_LIB}/paddle/lib")
set(EXTERNAL_LIB "-lrt -ldl -lpthread")
set(DEPS ${DEPS}
${PADDLE_LIB_THIRD_PARTY_PATH}mkldnn/lib/libdnnl.so.2
${PADDLE_LIB_THIRD_PARTY_PATH}mklml/lib/libiomp5.so
paddle_inference paddle_ipu flags
glog gflags protobuf xxhash cryptopp
${EXTERNAL_LIB})
set(CMAKE_CXX_FLAGS "-std=c++11")
add_executable(${DEMO_NAME} ${DEMO_NAME}.cc)
target_link_libraries(${DEMO_NAME} ${DEPS})
Compile script compile.sh:
Note: Please replace ${PADDLE_INFERENCE_INSTALL_DIR} with the corresponding paddle_inference library path
#!/bin/bash
mkdir -p build
cd build
rm -rf *
DEMO_NAME=ipu_word2vec_sample
LIB_DIR=${PADDLE_INFERENCE_INSTALL_DIR}
cmake .. -DPADDLE_LIB=${LIB_DIR} -DDEMO_NAME=${DEMO_NAME}
make –j
Compile:
./compile.sh
#Run:
This test example will complete inference on IPU and CPU respectively, and compare the results of the two
./ipu_word2vec_sample –-infer_model=word2vec.inference.model
Share:


