
Feb 08, 2022
Feb 08, 2022
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamUPDATE: The ability to use notebooks on Spell ended in June 2022, following Reddit's acquisition of Spell.
If you wish to run AI models on Graphcore IPUs within a Jupyter Notebook environment, we recommend Paperspace.
-----------
If you’re looking to train State-of-the-art models from the get-go, you can get up and running with our easy-to use BERT Fine-tuning quickstart notebook on IPU without leaving Spell’s web console.
And if you’re looking to learn more about programming IPUs and how to use our Poplar software, you can access a range of simple hands-on code from our tutorials repository to get you up to speed quickly:
Now with Spell, you can evaluate IPUs for free - either run one of our Spell-supported application examples, adapt one for your own needs, or test entirely new projects.
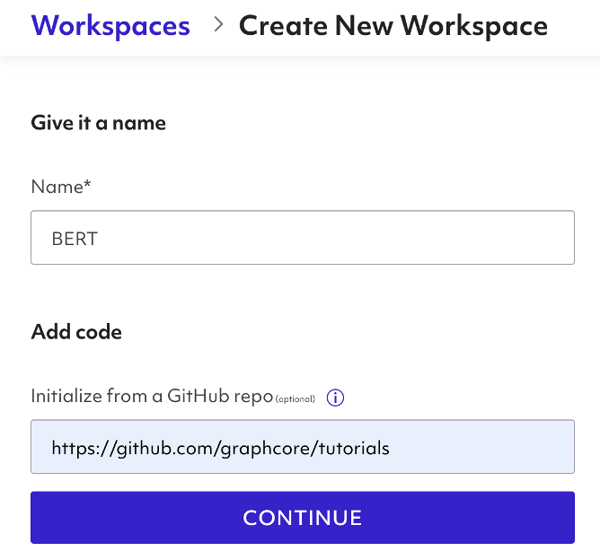
Creating a Spell account gives you free access to IPU compute, through the Workspaces. Workspaces is a managed notebook service containing files, notebooks, and other related resources that can be run using a Jupyter Notebook or JupyterLab.  Workspaces are created using the Create New Workspace button at the top right of the Workspaces section of the web console. You’ll be asked to give your Workspace a name, which we’ll call “BERT” in this example.
Workspaces are created using the Create New Workspace button at the top right of the Workspaces section of the web console. You’ll be asked to give your Workspace a name, which we’ll call “BERT” in this example.
When you create the Workspace, you will have the option to initialise it with code from a GitHub repository. The BERT Fine-tuning quickstart notebook is contained inside Graphcore’s Tutorials Repository.
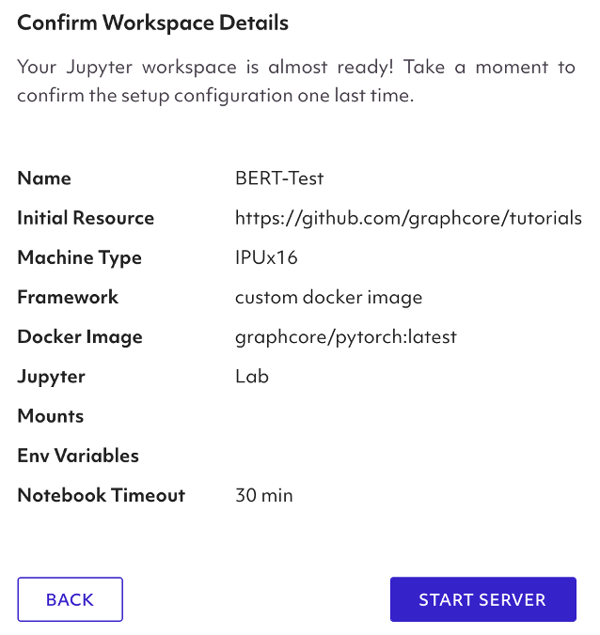
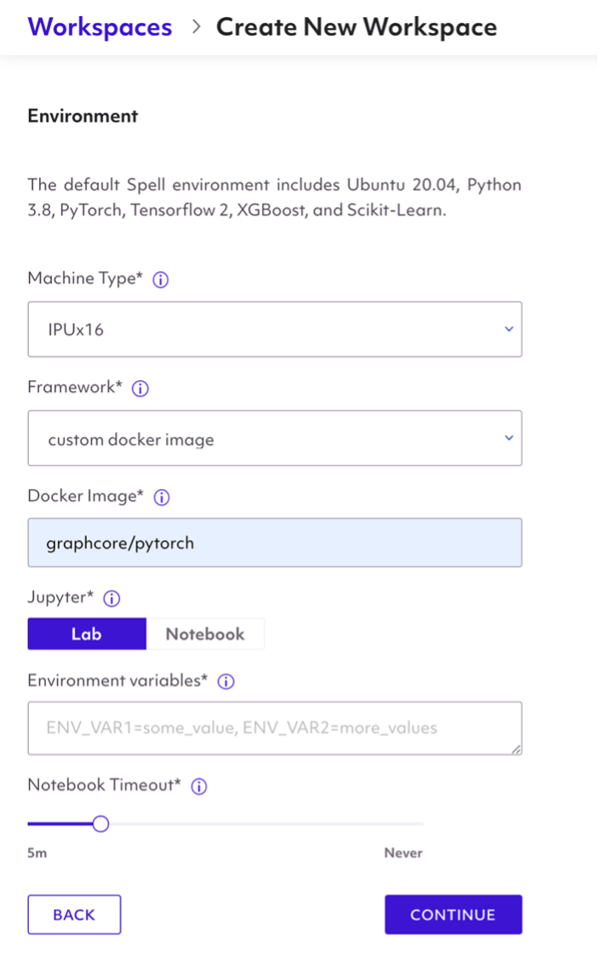
You will then have to setup your environment settings such as machine type, ML framework, requirements, and pip packages.
Select the IPUx16 option, this tells Spell Workspace to run your code on an instance of IPU POD 16. In order to run workloads on IPUs, we must configure communication between IPUs in PODs and the host machine. Luckily, Spell abstracts this process of setting up infrastructure and job execution when you select the IPU option.
In order to load the Poplar SDK into Workspaces, you must select “custom docker image” as the Framework and then point to one of graphcore’s Poplar SDK Docker images. We will use the graphcore/pytorch image for this guide, but you can also choose from three ML frameworks (i.e., Tensorflow, PyTorch, Poplar) available on Graphcore Dockerhub like so:
Pulling from the framework repo downloads the latest version of the SDK compiled for AMD host processor by default. You can check out Docker Image Tags for more info on specific SDK builds and processors.
Once you have completed the setup configuration steps, you can start the notebook server which will contain the BERT tutorial code, Poplar SDK, and the necessary IPU configuration settings. Creating the workspace launches the notebook view automatically, and it will then show up as an entry on the Workspaces list.
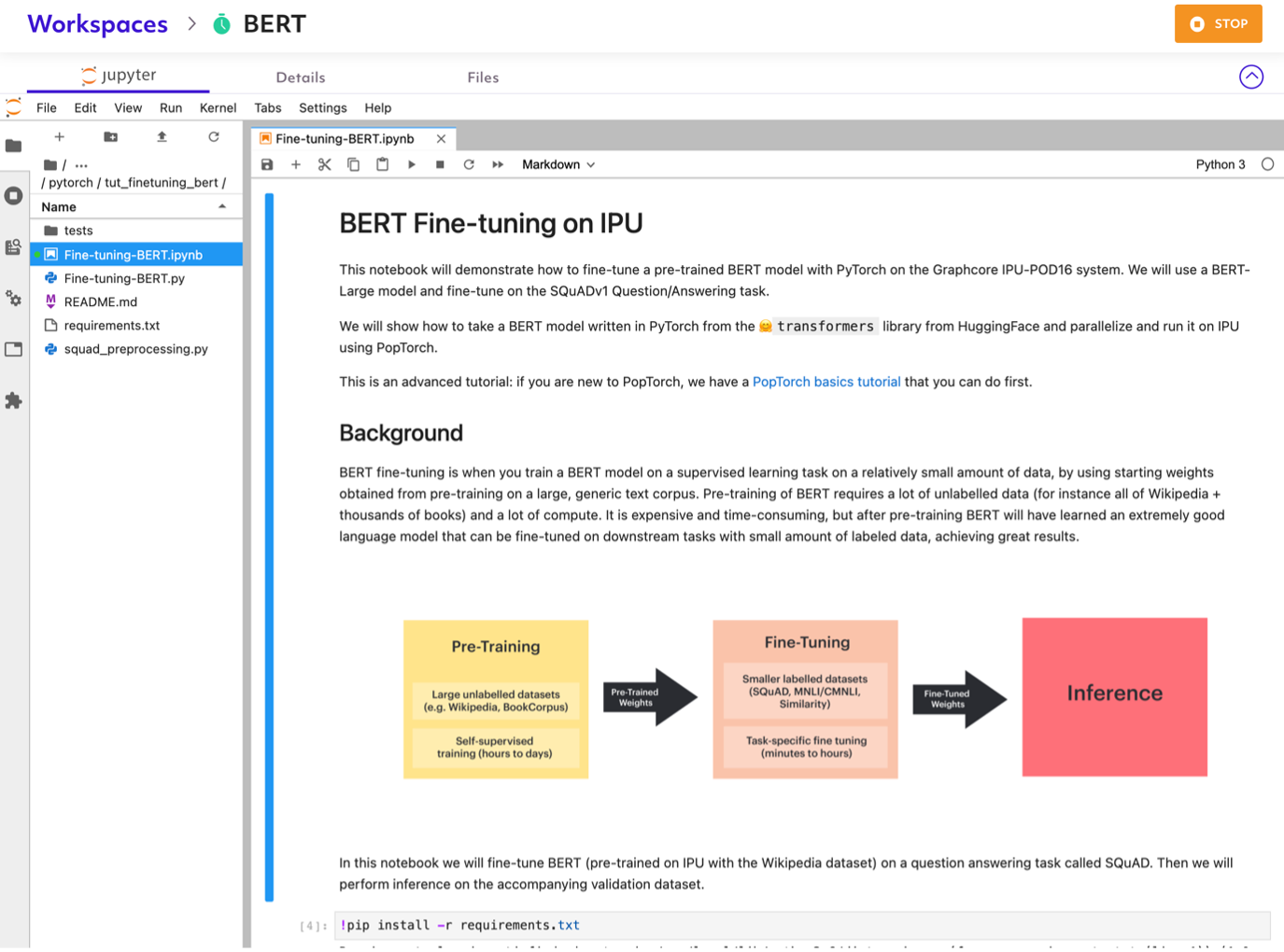
Navigate to the folder tutorials/pytorch/tut_finetuning_bert to find the BERT Fine-tuning tutorial.
The BERT Fine-tuning notebook has additional package requirements. Install the required packages listed in requirements.txt by opening a terminal and running `pip install -r requirements.txt` or running this inside a cell in the jupyter notebook.
This notebook will demonstrate how to fine-tune a pre-trained BERT model (pre-trained on IPU with the Wikipedia dataset) on a question answering task called SQuAD.
Step through the BERT Fine-tuning notebook to see programming principles that maximise the IPU hardware performance, such as the following:
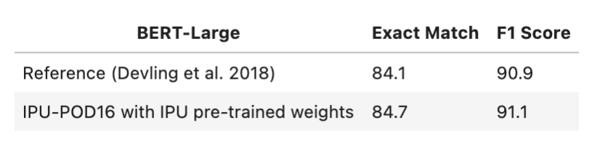
Upon completing the notebook, you will have fine-tuned a BERT model on a 2x8 Pipeline configuration on 16 IPUs, with the validation score for SQuADv1 below:
You can save and export the fine-tuned model for inference jobs. The notebook provides an example that uses the fine-tuned model for inference in Section 6. You can use the code provided to print answers to the question-answering task.
Share:


