
Jun 08, 2021
Jun 08, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamResearchers at the Oxford-Man Institute of Quantitative Finance have used Graphcore’s Intelligence Processing Unit (IPU) to dramatically accelerate the training of advanced price prediction models, using techniques which are typically plagued by computational bottlenecks when run on other types of processor.
The IPU’s designed-for-AI architecture allowed the OMI team to reduce the training times for their multi-horizon forecasting models to the point where they could deliver significant commercial advantage by more accurately estimating market price movements. Such models can be used in the development of alpha for fast trading and in market making strategies.Limit Order Books (LOBs) - the record of bid/ask price levels on financial markets - represent a real-time view of traders’ sentiment, encoded within millions of orders to buy and sell. Analysing LOBs can help predict price moves, which is of great value to market participants, although such insights are less about picking hot stocks, than knowing the optimal moment to execute any trade.
Artificial intelligence has the ability to interrogate the data in LOBs to a far greater degree of complexity, and consequently accuracy, than is possible through manual analysis or conventional computation.
Typically, efforts to apply AI in this area focus on single horizon forecasting, which tries to establish the relationship between a particular set of bid/ask prices and the resulting market pricing at a pre-defined moment (or horizon) in the future.
Multi-horizon forecasting, as the name suggests, analyses price moves over a series of intervals, with results for each horizon informing the next. Cumulatively, these can be used to generate much longer-term predictions.
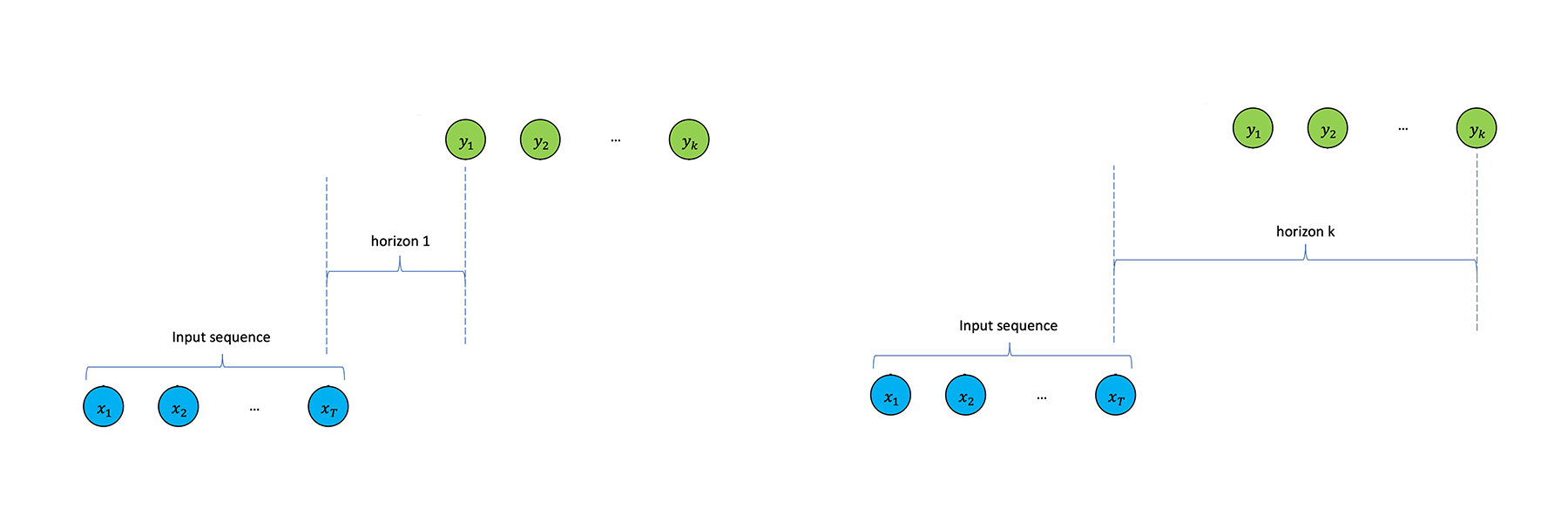 Multi-horizon forecasting
Multi-horizon forecasting
However, the usefulness of multi-horizon forecasting models has been hampered – in large part - by slow training on CPUs and GPUs.
Now OMI researchers Dr Zihao Zhang and Dr Stefan Zohren, have taken advantage of the fact that the IPU’s architecture maps much more closely to the recurrent neural layers used in multi-horizon forecasting, avoiding the computational bottlenecks.
As a result, their solution is able to train multi-horizon models to a high degree of accuracy, significantly faster than previously available techniques.
“We benchmarked with a wide range of interesting state-of-the-art networks and we see the IPUs are at least multiple times faster than the common GPUs. To give a number, I think it would be at least 10x faster,” said Dr Zhang.
The commercial applicability of OMI’s latest research is being considered by Man AHL, the diversified quantitative investment engine of Man Group.
Dr Anthony Ledford, Chief Scientist at Man AHL said: "If we're seeing that the IPU would enable that type of computation to be done at materially faster timescales then I can guarantee that people will be asking for these to be made available.”
Single horizon forecasting is typically approached as a standard supervised learning problem, with the aim of establishing a relationship between buy/sell prices on a limit order book and the resulting market price at a specific moment in time. However, the multitude of factors acting on market pricing and relatively low ratio of useful signals to noise make it hard to infer a longer-term forecasting path from a single horizon.
One technique to achieve multi-horizon forecasting borrows an approach common in natural language processing (NLP), employing Seq2Seq and Attention models, based on complex recurrent neural layers that include an encoder and a decoder. The Seq2Seq encoder summarises past time-series information, while the decoder combines hidden states with future known inputs to generate predictions. The Attention model helps to address certain limitations with Seq2Seq models that prevent them from processing long sequences.
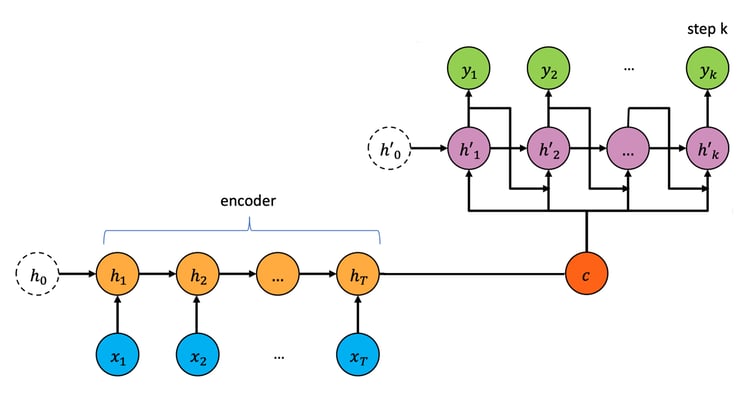
However, the recurrent structure of such models is not conducive to parallel processing on processor architectures such as that of the GPU. This is especially problematic given the high rate at which modern electronic exchanges produce LOB data.
Several solutions have been suggested to this computational problem, including the use of Transformers, with fully connected layers.
However, it was felt by the OMI team that the recurrent structure of the Seq2Seq/Attention combination aligned well with the nature of the time series in multi-horizon forecasting, enabling the summarisation of information from the past and propagation to a subsequent time stamp.
To make this approach practical, they needed a better performing compute platform, and set out to test their approach using Graphcore technology, taking advantage of the IPU’s radically different architecture.
LOB data was used to train a number of models on the IPU, including one - DeepLOB - previously developed by the same OMI team (Zhang et al, 2019). In terms of multi-horizon forecasting, the researchers tested two DeepLOB variants, named DeepLOB-Seq2Seq, and DeepLOB-Attention, which use Seq2Seq and Attention models respectively as their decoders.
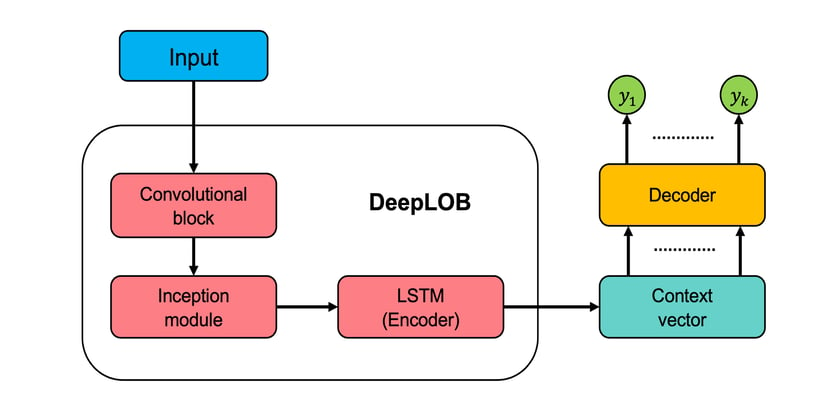 Model architecture: DeepLOB with encoder/decoder structure
Model architecture: DeepLOB with encoder/decoder structureAcross a range of models, including DeepLOB-Seq2Seq and DeepLOB-Attention, the Graphcore IPU system outperformed its GPU competitor in terms of time-to-train.
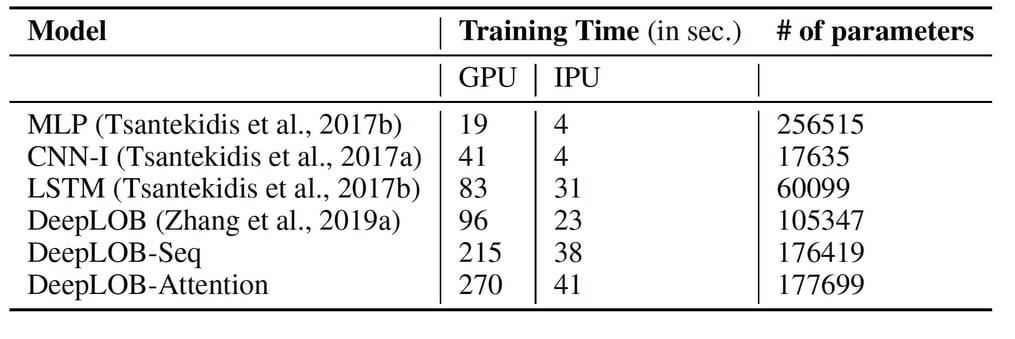
The new models also delivered superior prediction accuracy both at shorter horizons, such as K=10, and crucially, the longest horizons, such as K=50 and K=100. In this case, K represents ‘tick time’, the event time in which messages are received at the exchange. This is a natural time which ticks faster for more liquid stocks and slower for less liquid ones. In particular, the multi-horizon models DeepLOB-Seq2Seq and DeepLOB-Attention achieved the highest levels of accuracy and precision when used to make predictions at larger horizons.
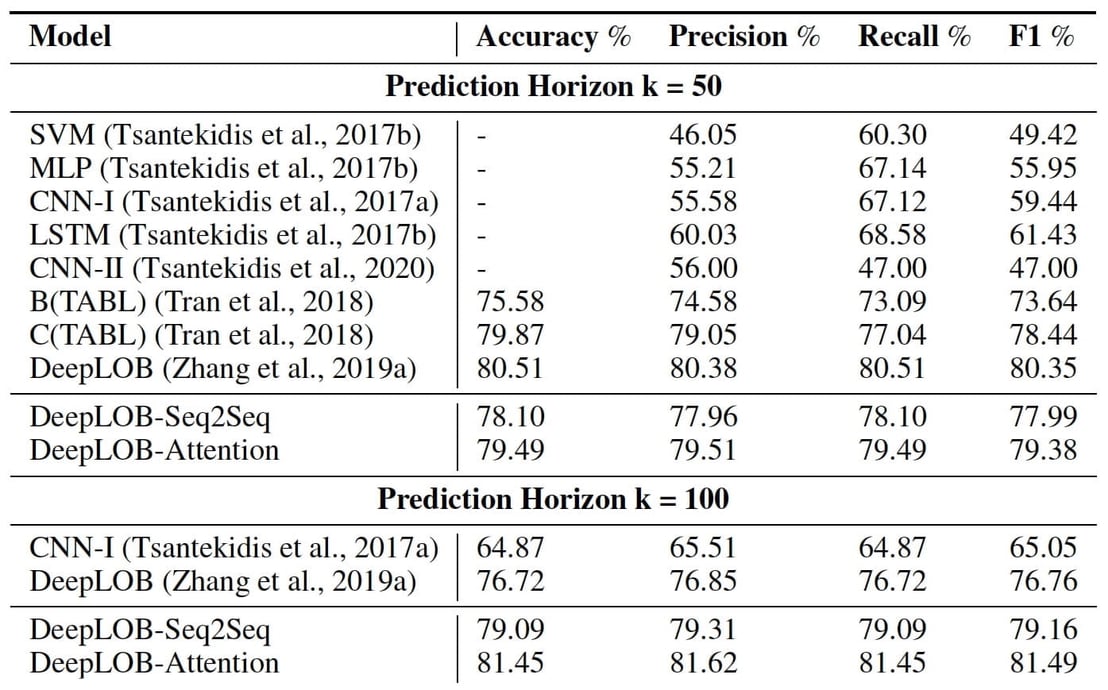 A full table of model types and multi-horizon performance is available in the OMI paper.
A full table of model types and multi-horizon performance is available in the OMI paper.
Next steps for prediction
Dr Zhang and Dr Zohren believe that the principles demonstrated in their research, using the Graphcore IPU, could open up a wide variety of applications, including the application of online learning or reinforcement learning in the context of market-making.
They may also look at applying the encoder-decoder structure to a reinforcement learning framework, as considered in one of their previous research papers.
“Reinforcement learning algorithms provide an excellent framework to apply such multi-horizon forecasts in an optimal execution or market making setting. Given the computational complexity of such algorithms, the speed-ups using IPUs might even be larger in this setup,” said Dr. Zohren.
You can read their current Research paper published on ArXiv and see their code on Github.
Share:


