
Dec 21, 2022
Dec 21, 2022
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamGenerative AI has well and truly hit its stride.
GPT3 and its derivatives, including ChatGPT have popularised text generation, while the likes of Dall-E and Midjourney are being used to create stunning original artwork from written prompts.
One of the standout stars of the generative AI revolution is Stable Diffusion. An alternative to Dall-E and Midjourney, this open-source text-to-image model was developed at Ludwig Maximilian University of Munich by the CompVis Group.
Stable Diffusion has received widespread acclaim in the generative art scene for the quality of its images, as well as its versatility. It also looks set to spawn a raft of commercial applications.
Now, AI art enthusiasts and professional developers building out AI platforms and services can run Stable Diffusion for the first time on Graphcore IPUs, with Paperspace Gradient notebooks, as the first step to build a business or just to explore new creative avenues.
Anyone can start generating images in a matter of minutes by simply launching a web-based notebook and running the pre-trained Hugging Face Stable Diffusion model. In addition to text-to-image generation, Stable Diffusion for IPUs also supports image-to-image, and text-guided inpainting.
Developers can take advantage of a six hour free session and try a selection of Stable Diffusion notebooks free of charge. And as of today, developers can now buy more IPU compute time at a flexible hourly rate with options to upgrade to larger or faster IPU systems.
Text-to-Image Generation on IPU![]()
Image-to-Image Generation on IPU![]()
Text Guided In-Painting on IPU![]()
Diffusion models for images work by adding varying amounts of noise to training images, and learning how to reverse the diffusion process to recover the original examples. Stable Diffusion works in a similar fashion, but it operates on compressed image features instead of the images themselves.
To achieve this, Stable Diffusion is composed of three separate neural networks.
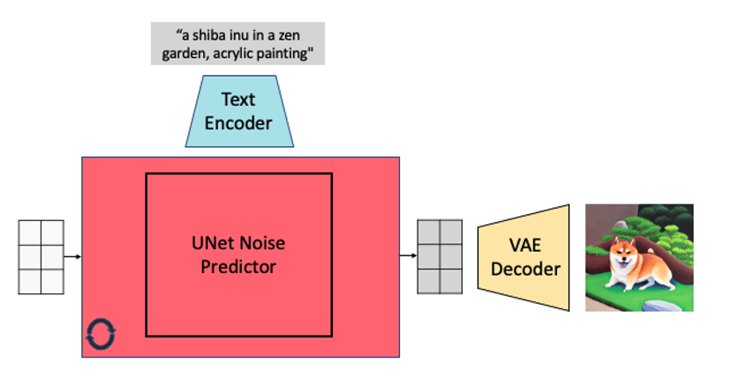
The first is a text encoder, which transforms each token of a user-provided text prompt into a vector of numbers. Technically, this is the encoder of a pretrained CLIP model, with 123M parameters for Stable Diffusion 1.x. Stable Diffusion 2.x uses the OpenCLIP encoder developed by LAION and consists of 340M parameters.
The core model – the UNet Noise Predictor – has the job of learning how to denoise randomly noised images to get back to their source, in an iterative process that is typically run 50 times.
The UNet consists of several downsampling blocks, followed by several upsampling blocks. Upsampling blocks concatenate their intermediate features with the corresponding downsampled features of same resolution. Attention modules present in the blocks integrate the context provided by the encoded user prompt. Overall, the UNet has 860M parameters, and is the most computationally expensive component.
Lastly, an image VAE decoder takes the denoised image features and projects them to generate the final output image.
To download and use the pretrained Stable-Diffusion-v1-5 checkpoint you first need to authenticate to the Hugging Face Hub. Begin by creating a read access token on the Hugging Face website, then execute the following cell and input your read token when prompted:
You will need to accept the User License on the model page in order to use the checkpoint trained by RunwayML.
We use `StableDiffusionPipeline` from upstream 🤗 diffusers, with two minor modifications:
We have made these modifications in our HuggingFace Optimum library optimised for Graphcore IPUs.
These are contained in the `IPUStableDiffusionPipeline` model, which we import below. Creating and running the pipeline requires no other changes.
The first call will be slightly longer as the model is compiled before being loaded on the IPU.
Now you can go ahead and run the pipeline on the provided prompts. We encourage you to try your own. As an example:

The Stable Diffusion pipeline can be used for other image synthesis tasks, such as:
Image-to-image (img2img), using the call:
where init_image is a pillow image object.
Inpainting, using the pipeline call
where image and mask are pillow images objects.
Image-to-Image Generation on IPU![]()
Text Guided In-Painting on IPU![]()
Stable Diffusion 2.0 for Graphcore IPUs will be available soon as Paperspace Gradient Notebooks.
Additional resources:
Blog header image shows: " A futuristic cityscape in the style of J. M. W Turner / Van Gough / Joan Miró", generated by Stable Diffusion running on Graphcore IPUs.
Share:


