
Jul 07, 2020
Jul 07, 2020
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamOur 1.2 Poplar SDK release showcases some features we have been looking forward to going public with at Graphcore for a while: the start of our Exchange Memory management features which take advantage of the IPU's existing unique hardware features and advanced architectural design with respect to memory and data access.
Overall, the combination of the unique way that the IPU accesses memory, the class-leading In-Processor Memory design and the Exchange Memory software features enable users to execute machine learning models fast no matter how large the model is or where the data is stored.
IPU Memory Access Design
When the IPU was originally created we spent a lot of time thinking about memory. This was one of the most exciting and forward-looking aspects of the way the IPU was designed. It had a radical new approach to memory organisation. Firstly, we focused on having a huge amount of In-Processor Memory – each MK2 Colossus GC200 IPU has 900MB of memory which is unprecedented and enough to hold the entire model in many cases (especially if you do not waste memory). Secondly, we made sure that the IPU could access other memory sources through its unique Exchange Memory communication techniques to enable larger models and programs. This design is crucial for modern machine learning workloads – how you access memory is as important as how you perform the compute once you have fetched the data.
The Exchange Memory access design was centred around two principles:
- Design as few as possible assumptions about memory access behaviour into the hardware.These two principles were designed in for both the very fast In-Processor Memory on the IPU and for access to Streaming Memory outside of the chip.
Streaming Memory
Like many modern processors, the IPU can deal with a layered memory hierarchy. Since IPUs work together in many-chip computations, the best way to think about it is the memory specification of a system, for example the IPU-Machine M2000:
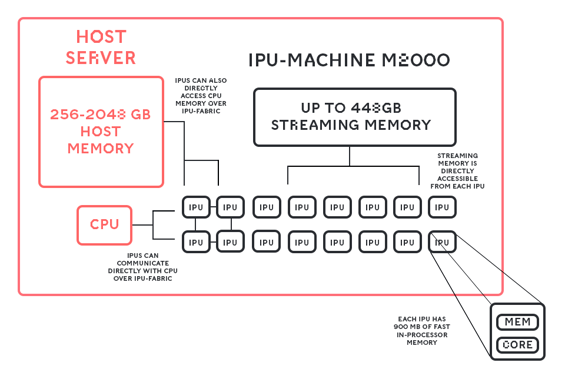 IPU-Machine Memory System
IPU-Machine Memory System
Each IPU-Machine has up to 450GB of memory addressable by the 4 IPUs. This is split into the 900MB per IPU of In-Processor Memory and up to 112GB per IPU of Streaming Memory. The Streaming Memory is contained in DDR4 DIMMs on the IPU-Machine 1U Server (in the same server as the IPUs) and the exact amount of memory will depend on the size of those DIMMs.
Software support for using In-Processor and Streaming Memory
As already mentioned, one of the guiding principles of the IPU design is that memory use is highly directed by the software. This enables us to provide a platform for applications with the most flexibility for high-efficiency memory access. So, what are the software features that enable this?
Exchange Memory
Exchange Memory is the umbrella term we use for the Poplar SDK features that manage the use of both In-Processor and Streaming Memory. We started shipping these features in the 1.2 SDK and will continue to expand on them during 2020 and beyond. The features are multiple and require quite considered design. Like with any memory hierarchy, the tools have to efficiently balance between fast local memory (of which the IPU has vastly more than most processors) and Streaming Memory (which gives a large amount of space but has slower access times).
Explicit Memory Management in the Poplar® Graph Programming Framework
In the lower-level Poplar graph programming framework, all memory spaces are explicit. Remote buffers can be created in Streaming Memory and the control program controls exactly when data is copied from these buffers to a variable in the In-Processor Memory and vice-versa.
// Add a remote buffer in streaming memory
auto r = graph.addRemoteBuffer("MyRemoteBuffer", FLOAT, 128, 10);
// Add a 2D graph variable in in-processor memory
auto v = graph.addVariable(FLOAT, {8, 16});
...
...
// Copy the variable into the remote buffer
prog.add(Copy(v, r));
...
Poplar code using explicit memory control
Intelligent Variable Placement in ML Frameworks
At the ML Framework (e.g. TensorFlow) level, intelligent variable placement chooses when variables in the computation graph are in Streaming Memory and when they are in In-Processor Memory. Currently, the decisions on which variables reside in which memory is based on user annotations. Going forward, we plan to add more flexible annotations and automated methods to ease development.
When training neural network models in PopART™ (the Poplar Advanced RunTime) the program can mark sections of the computation graph as “phases”. Before each phase, all required model parameters (and stored activations for the backward pass of neural network training) are moved from Streaming Memory into In-Processor Memory. After each phase, any parameters or activations that need saving are moved into Streaming Memory. This means only part of the model needs to reside in In-Processor Memory at any one time.
# Add a matmul on a particular IPU (virtualGraph) for a particular
# ping-pong phase
with builder.virtualGraph(vgid), builder.pingPongPhase(i):
x = builder.aiOnnx.matmul([x, qkv])
PopArt code showing annotations of a model section
In the above code, the pingPongPhase annotation marks the graph section to have its parameters and activations stored in Streaming Memory and also sets the execution scheme for that phase to be “ping-pong”. In a ping-pong scheme, one IPU will do compute whilst another IPU loads/saves data from Streaming Memory. At the end of the phase, the IPUs will swap roles so the data loaded in the previous phase is now computed on and the IPU doing compute previously can load/save more data. In effect, you have two IPUs implementing a memory fetch pipeline. Ping-pong is just one of the execution schemes available in the frameworks for using Streaming Memory.
The software can exploit the phased execution of the model along with re-computation to further reduce memory access times. This is only possible with the very large In-Processor Memory space. In the backwards pass of a gradient descent training algorithm, the activations can all be recomputed from the start of the phase and stored in that large memory. This means that only one set of activations needs to be stored and re-loaded from Streaming Memory for the entire phase.
When you move weights into Streaming Memory, another optimisation that can be enabled in PopART is replicated weight sharding. This optimisation partitions the weights to be fetched in parallel by multiple IPUs that are participating in data parallel training. This project by Microsoft shows a proof point of this technique. On the IPU this is further enhanced by using the fast native IPU-Links™ between the chips to then share the weights between the data parallel replicas. The combination of using parallel data loading and IPU-Links reduces the weight loading/storing time to a very small fraction of the total runtime.
In TensorFlow models, by default all variables reside in In-Processor Memory apart from optimiser state variables (momentum terms etc.) which default to Streaming Memory. This default can be changed. We will be continually adding new options for controlling variable placement to TensorFlow in the future.
return pipelining_ops.pipeline(computational_stages=...,
pipeline_depth=...,
...
offload_weight_update_variables=True,
...
TensorFlow code configuring optimiser state variables to live in streaming memory
Optimised Data Communication
Streaming memory can be used to optimise the time taken to move data to and from the local IPUs (either to the CPU or to other IPUs in other servers). The Streaming Memory can act as an intermediate buffer for the communication. These optimisations will be introduced into the Poplar SDK over the coming year. One of the great aspects of these optimisations is that they can work automatically with your application – no changes to code are required.
Summary: Intelligent Memory for Intelligent Computing
Good memory and data management is the key for high-performance machine learning workloads. At Graphcore, we see it as one of the most essential and exciting features of our technology. At the centre of our approach is a new way of thinking about memory which is centred around software/hardware co-design. This enables us to explore and innovate in both our software and new hardware platforms to get the best use of memory possible.
Share:


