.png?width=1440&name=Papers%20wide%20(1).png "Papers header")
Mar 07, 2024
Mar 07, 2024
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamImproving LLM inference is a key research topic at the moment, and something we’re particularly interested in at Graphcore because of its hardware implications. February saw several developments in this area, focussing on both the efficiency and capabilities of LLM inference.
Microsoft contributed two of this month’s papers, with the first showing a method of extrapolating to long sequences, and the second an approach to storing 6-bit weights. Researchers from Cornell University have gone further and pushed the limits of quantisation to as few as 3 bits for inference. Apple also introduced their new speculative streaming method, which makes efficiency gains by asking the model to predict multiple future tokens, improving over the popular speculative decoding technique.
Here’s a summary of some of our favourite papers over the last month:
Authors: Yiran Ding et al. (Microsoft Research)
Language models are generally limited to performing well only on sequence lengths seen during training. Building upon this observation and prior work, this paper introduces a method for greatly extending the context length of pretrained language models using RoPE embeddings through a sequence of relatively inexpensive fine-tuning steps.
%20(1).png?width=749&height=392&name=figure_1%20(2)%20(1).png)
Widely used open-source language models such as Mistral-7B and Llama2-7B use rotary position embeddings (RoPE) and are trained on sequences containing up to 4k tokens. Although longer sequences can in theory be easily encoded and processed by the models, the performance tends to quickly deteriorate as the sequences become longer than the ones observed during training.
RoPE encodes the positions within the sequence by dividing each (query and key) vector’s dimensions into consecutive pairs and applying a 2D rotation to each pair. The angle rotated is proportional to the position id (ensuring that the query-key dot product is a function of the relative distance between the tokens), and is scaled differently for each dimensional pair: initial dimensions are rotated more (capturing high frequency dependencies), while the latter dimensions are rotated less (lower frequency dependencies).
.png?width=1727&height=835&name=figure_2%20(1).png) Several approaches have been previously proposed to address the issue of generalising past trained sequence lengths:
Several approaches have been previously proposed to address the issue of generalising past trained sequence lengths:
Utilising the observations from YaRN, the authors propose further refinements:
The authors note that just finding the best scaling factors without fine-tuning was able to extend the sequence length up to 32k, but incurred performance degradation for longer sequences. Therefore, in order to stretch the context window length to 2M tokens, the authors follow a sequence of steps:
Model perplexity is used throughout each step to guide the search/fine-tuning.
The authors test the method using three evaluation setups: long-context perplexity, accuracy on a synthetic passkey retrieval task (find a passkey in a long unrelated text), as well as downstream tasks on short-context lengths to evaluate degradation on the original sequence length.
As state-of-the-art models such Gemini 1.5 are starting to showcase capabilities to process extremely long sequences, methods for extending the sequence length of short-context language models remain exceedingly important.
The paper provides useful insights into extending context window length of language models, confirming the importance of using different RoPE frequency scaling factors introduced in previous approaches such as YaRN and “NTK-aware” scaling, but noting that the previously used factors are not necessarily optimal. Although the method is able to extend the context window to an impressive 2M tokens length, the model still tends to perform worse on the original shorter sequence lengths, implying that further improvements may be possible.
Understanding the proper steps for robustly extending the context length of models, as well as the comparative pros and cons of such techniques vs retrieval-based approaches, remain essential research questions in the LM community, highlighting the importance of contributions such as LongRoPE.
Full paper: LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Authors: Albert Tseng, Jerry Chee, et al. (Cornell University)
Enable extreme compression by transforming weights to something less heavy-tailed before quantising with a set of spherical (rather than grid-like) codes!
.png?width=1189&height=225&name=FIG-Scheme%20(1).png)
LLM token generation is memory-bandwidth bound, i.e. limited by the rate at which model state can be read. This means that any reduction in #GB to store model weights and KV cache can increase #tokens/sec.
Widely adopted LLM compression techniques typically stop at 4-bits since this hits a sweet spot with:
One reason these techniques struggle to quantise to fewer bits is that the tails of LLM weights and activations distributions affecting the majority of computation become increasingly susceptible to quantisation error. To address this, the authors previously proposed QuIP in which weights are transformed to have a less heavy-tailed distribution. Here they present two key improvements to QuIP.
QuIP is comprised of two key components:
A quantisation algorithm 𝑄 that maps $\tilde{W}$ to some quantised space in such a way that minimises quantisation error of outlier activations.
Which you can summarise with:
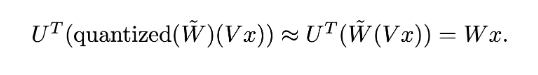 QuIP# improves both the method for generating 𝑈 and 𝑉 and the quantisation algorithm 𝑄.
QuIP# improves both the method for generating 𝑈 and 𝑉 and the quantisation algorithm 𝑄.
𝑈, 𝑉 generation: To exploit GPU parallelism and decrease bounds on outlier features, the authors propose using a Randomised Hadamard Transform (RHT), in which U and V can be represented as Hadamard matrices along with randomly generated sign flips of weight columns. They prove that the largest singular values of transformed weight matrices scale logarithmically with the size of the weight matrices, meaning lower probability of outliers in weights needed to be quantised.
Q algorithm: As with other recent methods (e.g. AQLM, GPTVQ), the authors explore vector quantisation as a means to provide a high-density quantised space to map uncompressed points onto. The key idea behind vector quantisation is that you can define arbitrary prototypes to discretise a multi-dimensional space, rather than regular grid-like points that would result from elementwise, scalar quantisation. A key choice for any vector quantisation algorithm is the set of prototypes, or codebook 𝐶 that is used to discretise the space. Here the authors choose the E8-Lattice, since it has both high packing density in multi-dimensional space and can be exploited for symmetries to compress further. Choices on how to combines sets of lattices define the #bits a vector is compressed to.
Compressing to 3-bits introduces very little degradation in perplexity compared to an FP16 baseline. So much so that it looks like the trade-off of using a slightly larger model compressed to fewer bits is worthwhile.
.png?width=1334&height=463&name=TBL-perplexity-2048%20(1).png) It’s worth noting that the perplexity gains over AQLM are only realised if you use both the lattice codebook and finetune.
It’s worth noting that the perplexity gains over AQLM are only realised if you use both the lattice codebook and finetune.
.png?width=573&height=502&name=TBL-perplexity-4096%20(1).png) As is often the case, low perplexity doesn’t always translate to better zero-shot performance on typical QA tasks, although it looks as though QuIP# stands up well in many cases.
As is often the case, low perplexity doesn’t always translate to better zero-shot performance on typical QA tasks, although it looks as though QuIP# stands up well in many cases.
.png?width=908&height=315&name=TBL-zero-shot%20(1).png) In terms of practical speed-ups that can be gained from using this, a lot seems to depend on how efficiently the Randomized Hadamard transform and lookups into the E8-lattice can be implemented. Both are memory bandwidth bound operations, but might also be difficult to achieve peak bandwidth. Notably, the authors don’t publish #tokens/sec for their eye-catching 3-bit compression scenario, only 2- and 4-bit.
In terms of practical speed-ups that can be gained from using this, a lot seems to depend on how efficiently the Randomized Hadamard transform and lookups into the E8-lattice can be implemented. Both are memory bandwidth bound operations, but might also be difficult to achieve peak bandwidth. Notably, the authors don’t publish #tokens/sec for their eye-catching 3-bit compression scenario, only 2- and 4-bit.
This is a compelling proof-of-concept that 3-bit compression can be effective work. Concurrent work also seems to suggest that vector quantisation is critical for sub 4-bit compression, although it remains to be seen how practical speedups can be realised (even in other works). It is also worth noting that GPTVQ (published within the last week) appears to obtain better 3-bit perplexity results for larger models than QuIP#. This promises to be an exciting race to find the best schemes with suggestions for how future low-precision hardware might look!
Full paper: QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks
Authors: Nikhil Bhendawade et al. (Apple)
Speculative decoding is great for speeding up LLM inference, but has the downside of requiring a well-aligned external draft model. Speculative streaming addresses this by modifying a model to produce its own tree of draft tokens in one parallel inference step.
%20(1).png?width=730&height=465&name=figure_1%20(3)%20(1).png) Background
BackgroundOver the last year, speculative decoding (or speculative sampling) has become popular for LLM inference. This works by using a smaller draft model alongside the main target model, whose job it is to generate a sequence of draft tokens at each step. The target model then verifies those proposed tokens (checking to see if they are sufficiently aligned with its own probability model) and accepts them up to some point in the draft sequence. Accepted tokens become part of the “true” output of the model and rejected ones are disposed of.
This process has two crucial properties that make it appealing:
However, off-the-shelf draft models can give quite different predictions to the target model so often need fine-tuning for alignment, and running two models simultaneously can be complex and memory-intensive.
The authors address this by adapting existing models and fine-tuning, such that the model can generate its own draft tokens.
%20(1).png?width=868&height=596&name=figure_2%20(2)%20(1).png) This is done via a process of parallel pruning, speculation and verification. This can be a little tricky to understand, as each inference step is now doing three things: verifying the previous draft tokens, generating a new token after the draft sequence, and generating the next draft tokens. It works as follows:
This is done via a process of parallel pruning, speculation and verification. This can be a little tricky to understand, as each inference step is now doing three things: verifying the previous draft tokens, generating a new token after the draft sequence, and generating the next draft tokens. It works as follows:
Each iteration takes as input the sequence so far, along with a (flattened) tree of draft tokens. A special pruning layer in the middle of the network uses the final embedding layer to generate an early prediction of which trees look promising, dropping low-probability branches. This is followed by a stream embedding layer, which uses the regular tokens’ hidden state to generate a set of hidden states for a tree of “new” draft tokens.
These new draft tokens are processed in the usual way until the end of the network, where the model uses the standard speculative decoding accept/reject sampling to decide which “input” draft tokens to accept. The “new” draft tokens generated for that branch then become the “input” draft tokens for the next iteration.
Speculative streaming is substantially faster than regular auto-regressive inference, and is marginally faster than the competing Medusa method (which also adapts a single model to produce a draft) but uses many fewer additional parameters.
The comparison against standard speculative decoding is harder. Their empirical results show a 2x speedup, but depend on various practical considerations and hyperparameters. More useful is their theoretical analysis showing the regimes in which speculative streaming should give a speedup. There are clearly circumstances in which it’s beneficial, though this heavily depends on the relative quality of the draft models:
.png?width=526&height=438&name=figure_4%20(1).png) Takeaways
TakeawaysThis is a really neat paper, even if it feels like a bit of a “hack” in the context of auto-regressive LLMs. Predicting multiple tokens in parallel is not really something that LLMs should excel at, and they only get away with it here because of the speculative setting. But because it allows a single model to do both draft and target modeling in a single step, it appears to be worthwhile.
Given all that, their execution of the idea is great. The authors are clearly concerned with making this work in practical settings, which is reflected by their addition of tricks like tree pruning. The results look promising, though it remains to be seen which areas of their speedup-modeling correspond to practical use-cases, which will ultimately determine how widely speculative streaming is used.
Full paper: Speculative Streaming: Fast LLM Inference without Auxiliary Models
Authors: Haojun Xia et al. (Microsoft)
Post training quantisation of LLMs can reduce the cost of inference as models are typically memory bound. Compressing the weights of the model into lower precision reduces the burden of memory transfers. Currently there is no good hardware support for post-training quantisation in non-power-of-2 bits and the authors propose a full stack GPU kernel for floating-point weights of various bit widths (e.g. FP6). The authors follow on from previous work showing that FP6 can be used without a noticeable drop in accuracy. They provide an end-to-end inference pipeline for FP6 training and using this, show a substantial speedup on the FP8 baseline for a variety of models.
The main challenges in quantising to non-power-of-2 values is that GPU registers are generally designed to read at the granularity of 32-bit words. To read 6-bit weights this means a large fraction of the memory read will be unused and therefore wasted. To solve this problem the authors propose a method of ahead-of-time bit-level pre-packing. In which you can combine the memory read of every 32 x-bit weights, resulting in x requests of 4-byte words per GPU thread. In this case, all the memory access would be aligned at the granularity of 32-bit words rather than irregular bit width. In order to do this is it required to rearrange the weights in memory but it is only required to do this once and this cost can be amortised over many inference calls.
.png?width=651&height=620&name=figure_5%20(1).png) The other challenge the authors face is how to best hide the latency of the FP-x to FP16 cast during dequantisation. They leverage parallelism by using the SIMT cores to do the dequantisation while the Tensor Cores run the model. Furthermore, they can dequantise multiple FP-x weights in parallel due to the bit level parallelism within each 32 bit register, reducing SIMT overhead by 4x.
The other challenge the authors face is how to best hide the latency of the FP-x to FP16 cast during dequantisation. They leverage parallelism by using the SIMT cores to do the dequantisation while the Tensor Cores run the model. Furthermore, they can dequantise multiple FP-x weights in parallel due to the bit level parallelism within each 32 bit register, reducing SIMT overhead by 4x.
.png?width=816&height=382&name=figure_6%20(1).png) Results
ResultsEvaluation is conducted with reference to an FP16 base model and quantised FP8 model. They show consistent speedups over these models by around 2.2x and 1.3x respectively. Furthermore quantising to FP6 allows LLaMA-70B to be deployed using only a single GPU, achieving a speedup of 1.69-2.65x the FP16 baseline. Overall we think this is a promising method to break the hardware lock of quantising to powers of 2 and allow more flexible and efficient LLM inference.
.png?width=3460&height=1100&name=figure_9%20(1).png) Full paper: FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
Full paper: FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
Discover more on the Graphcore Research team's Github, and subscribe to the Papers of the Month newsletter.
Share:


