
Aug 30, 2023
Aug 30, 2023
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamWe’re pleased to announce the release of a PyTorch library to facilitate unit scaling — a method for designing models that makes low-precision number formats such as FP16 and FP8 easy to use.
In July, Graphcore researchers presented the paper Unit Scaling: Out-of-the-Box Low-Precision Training at ICML in Hawaii. We’re now releasing the software tools to make this method available to a wider audience.
The development of hardware with FP8 support, such as the Graphcore® C600 IPU-Processor PCIe Card, offers users substantial efficiency improvements. However, naïvely casting values from higher precision down into FP8 tends to degrade performance. Unit scaling addresses this, offering a simple path to making the most of FP8 hardware for training.
Check out the library documentation
Read our ICML paper
To show users how to apply unit scaling to their own models, we’re also releasing a notebook to accompany the library. This demonstrates the training of the nanoGPT model in FP8 with and without unit scaling.
With only a single line of code — model = unit_scale(model) — users can turn their PyTorch module into a unit-scaled model.
We illustrate this in the notebook, training the following models:
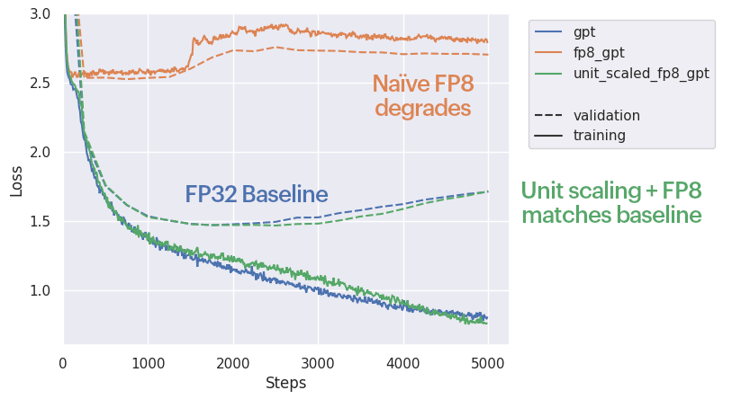
Training the base model directly in FP8 causes a significant degradation. However, full accuracy is recovered by using unit scaling.
This one-line transform can be applied to arbitrary PyTorch models, with negligible overhead when used with torch.compile.
The one-line automatic unit_scale() transform is an experimental feature. We recommend most users implement unit scaling manually, in the following way.
Consider this common approach to importing PyTorch modules/functions:
In this setting unit scaling can be applied by first adding:
and then replacing the letters nn with uu and F with U, for those classes and functions to be unit-scaled. For example:
There are a few additional considerations required to make unit scaling work properly, which are covered in our User Guide. Particular care should be taken to correctly scale skip/residual additions and loss functions.
Unit scaling can be installed with:
unit_scaling is a new library and (despite our best efforts!) we can't guarantee it will be bug-free or feature-complete. We're keen to assist anyone who wants to use the library and help them work through any problems.
Please reach out through our community of developers using our Slack channel or raise a GitHub issue.
Share:


