
Jul 09, 2021
Jul 09, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamA Université de Paris researcher has used Graphcore IPUs to accelerate neural network training for cosmology applications.
In the newly published paper, researcher Bastien Arcelin explores the suitability and performance of IPU processors for two deep learning use cases in cosmology: galaxy image generation from a trained VAE latent space, and galaxy shape estimation using a deterministic deep neural network and Bayesian neural network (BNN).
An unprecedented amount of observational data will be produced in upcoming astronomical surveys. One such project is the Vera C. Rubin Observatory’s Legacy Survey of Space and Time (LSST) which is expected to generate 20 Terabytes of data every night, and around 60 Petabytes in total during its 10 years of service.
Cosmology researchers are increasingly using neural networks to manage such large and complex datasets.
However, the sheer amount of unknowable or uncontrollable variables involved in real-world observations can make training neural networks on this type of data extremely challenging.
As in many AI applications, simulated data – where precise parameters can be known and controlled, is best suited to training.
Ideally, the quantity and quality of such data should be as close as possible to the real data recorded by photometric galaxy surveys like the LSST.
Because this simulation data is also large and complex, the associated neural network needs to be fast, accurate and, for some applications, able to accurately characterise epistemic uncertainty.
Such computational demands beg the question; can hardware specifically designed for AI deliver superior performance for deep learning in cosmology?
Graphcore’s IPU was designed to efficiently process graphs – the fundamental structure behind every AI algorithm – which makes it an ideal example processor to test this theory.
In this research, the performance of a single first generation Graphcore chip, the GC2 IPU, was compared with one Nvidia V100 GPU.
When training neural networks with small batch sizes, the IPU was found to perform at least twice as fast as the GPU for the DNN and at least 4 times faster for the BNN. The GC2 IPU attained this performance with only half the power consumption of the GPU.
The framework TensorFlow 2.1 was used during all the experiments, since TensorFlow 1 & 2 are fully supported on the IPU with an integrated XLA backend.
Data based on simulations of cosmological sources, such as galaxies, has traditionally been based on simple analytic profiles like Sérsic profiles, a slow generation technique which heightens the risk of introducing model biases.
Deep learning methods have the potential to simulate data much faster. Generative neural networks are increasingly being employed to model galaxies for various applications in cosmology (for example, Lanusse et al., 2020, Regier, McAuliffe, and Prabhat, 2015 or Arcelin et al., 2021).
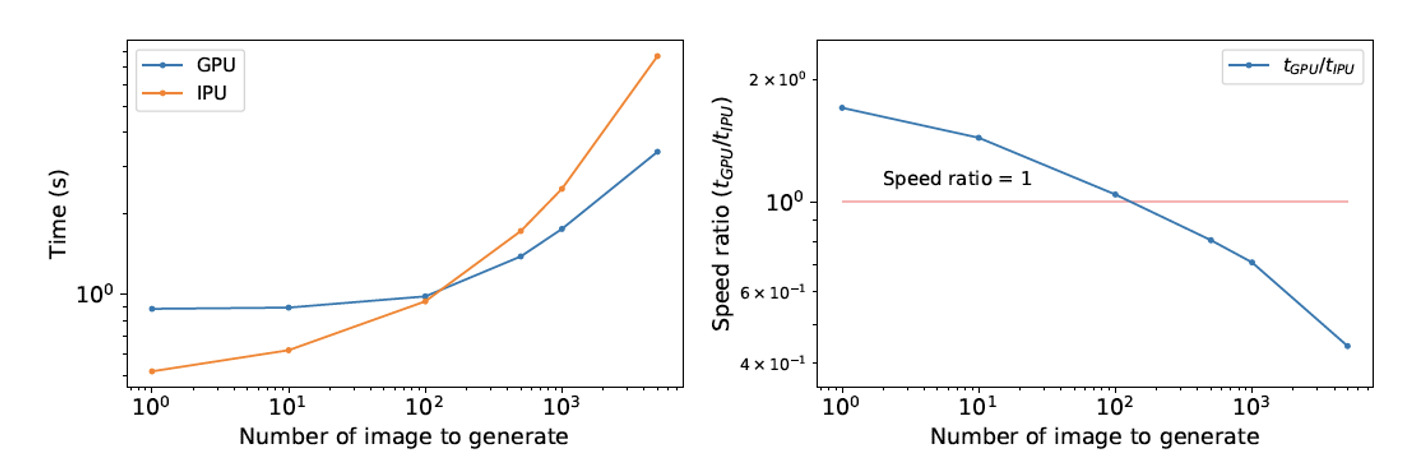
Images are generated by sampling the latent space distribution of a variational autoencoder (VAE) which has been trained on isolated galaxy images.
In this case, the IPU can be seen to outperform the GPU when generating small batches of images.
It is likely that running this workload on Graphcore’s second generation IPU, the GC200 would enable significantly improved performance when generating larger batches, due to the processor’s greatly expanded on-chip memory.
Next generation astronomical surveys will look deeper into the sky than ever before, resulting in a higher probability of blended (i.e. overlapped) objects. Clearly, it is much harder to measure the shape of galaxies when they are partly covered.
Existing galaxy shape measurement methods do not perform accurately on these overlapping objects, so new techniques will be needed as surveys continue to observe further in the sky.
Université de Paris researcher Bastien Arcelin has been developing a new technique featuring deep neural networks and convolutional layers in order to measure shape ellipticity parameters on both isolated and blended galaxies.
The first experiment was carried out with a deterministic neural network and the second test used a BNN. Once they have been trained, trainable parameters in a deterministic network have a fixed value and do not change even if the network is fed twice with the same isolated galaxy image. This contrasts with BNNs where the weights themselves are assigned probability distributions rather than single values. This means that feeding a BNN network twice with the same image results in two different samplings of the probability distributions, leading to two slightly different outputs. By sampling these distributions multiple times, the epistemic uncertainty of the results can be estimated.
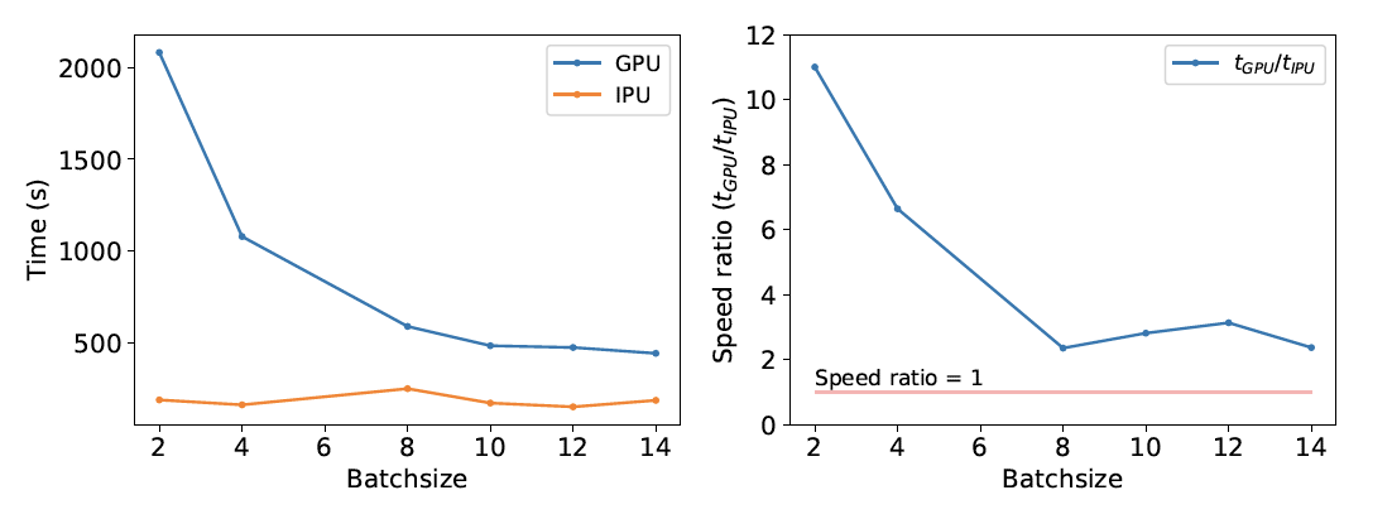
For the deterministic neural network, Graphcore IPUs enable faster time to train in comparison with GPUs, particularly when small batch sizes are used. This is not hugely surprisingly since IPU technology is already known for its efficient performance on convolutional neural networks in computer vision applications.
Next, the technique was tested on a Bayesian Neural Network. It is crucial for cosmology researchers to be able to establish the level of confidence they can have in neural networks’ predictions. Researchers can use BNNs to calculate the epistemic uncertainties associated with predictions, helping to determine the confidence level in these predictions, as epistemic uncertainty strongly correlates with large measurement errors.
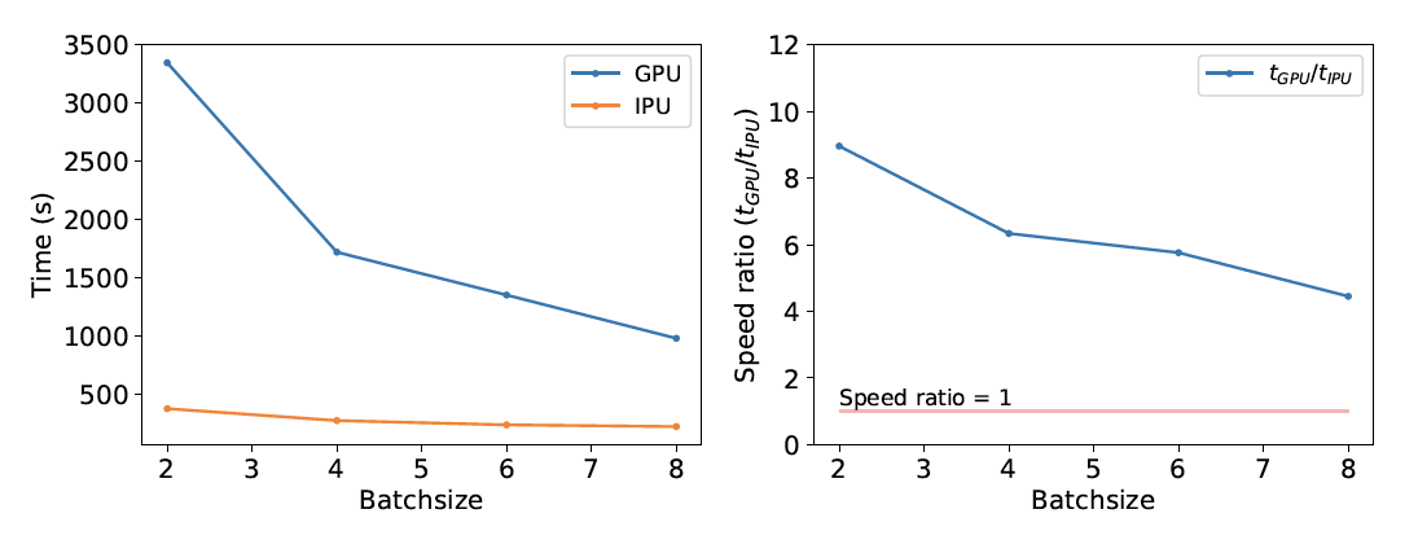
IPUs again outperform GPUs in the case of the BNN with at least four times faster time to train.
The IPU is clearly capable of significantly reducing artificial neural network training time for galaxy shape parameter estimation and performs best at small batch sizes when using one IPU as in this research. For higher batch sizes, the network can be split over multiple IPUs to improve performance and efficiency.
For researchers based in Europe like Bastien Arcelin who need to process their data safely within the EU or EEA, the smartest way to access IPUs is through G-Core’s IPU Cloud.
With locations in Luxembourg and the Netherlands, G-Core Labs provide IPU instances fast and securely on demand through a pay-as-you-go model with no upfront commitment. This AI IPU cloud infrastructure reduces costs on hardware and maintenance while providing the flexibility of multitenancy and integration with cloud services.
The G-Core AI IPU cloud allows researchers to:
Share:


