
Aug 28, 2020
Aug 28, 2020
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamResearchers from the University of Bristol have demonstrated for the first time that Graphcore’s IPU can be used to accelerate a host of complex computational tasks found in particle physics.
The team – whose work is focused on the Large Hadron Collider beauty (LHCb) experiment at CERN – details its findings in a new paper.
Particle physics has tended to rely on a range of traditional high-performance computing (HPC) methods to address its data processing needs. However, AI solutions are becoming increasingly prevalent as algorithms and hardware enable more advanced analysis.
The shift in Physics is also being seen in other data-heavy HPC applications, sparking a search for new computational technologies optimised for this novel approach.
Using a Graphcore IPU, the Bristol team - led by Professor Jonas Rademacker - found significant improvements in particle identification through neural networks. They accelerated both training and inference for Generative Adversarial Networks (GANs), delivering a performance increase of up to 5.4x compared to GPUs.
The researchers were also able to take advantage of the IPU’s MIMD architecture to run Kalman Filters, a fundamentally important algorithm across modern physics and engineering.
The achievements demonstrated in the paper reflect both the diversity of solutions to what have traditionally been HPC problems, and the versatility of Graphcore’s massively parallel processor.
The research was carried out prior to the announcement of Graphcore’s MK2 IPU technology and used just one MK1 GC2 IPU, compared to one Nvidia P100 GPU.
The superior results obtained with the IPU across all areas of investigation is impressive, not least because they were obtained at half the power consumption of the GPU.
Accelerating Particle Physics on the IPU
Generative Adversarial Networks
Generative Adversarial networks are a pair of networks trained synchronously where one network produces simulated data and the other classifies the output as either real or fake. These are typically used in image manipulation as style transforms, and in speech synthesis. However, recently there has been more focus on exploring the application of GANs to produce analysis-quality data.
As detailed in their paper, researchers from the University of Bristol deployed GANs on the IPU in order to simulate particles and explore track reconstruction.
Simulating particle behaviour in a detector is essential in order to determine the performance of the system and to model the hardware, as well as to understand how different particles may be observed by the detector. These simulations are incredibly computationally expensive because of the combinatorial number of interactions and particles resulting from each collision.
In most Monte Carlo particle physics simulations, there are significant bottlenecks which result in a huge compute cost and low total efficiency. GANs can resolve these bottlenecks by augmenting the simulation process since they are exceptionally good at modelling multi-dimensional, multi-modal distributions. They can generate a correlated distribution which can then be used for physics analysis.
The IPU, specifically designed for AI workloads, was shown to significantly outperform the GPU thanks to the IPU’s performance capability at low batch sizes. During training, the IPU was found to achieve an improvement of 3.9x and 5.4x speed-up respectively for the convolutional architecture of the DijetGAN model and the fully connected architecture of the SHiP model.
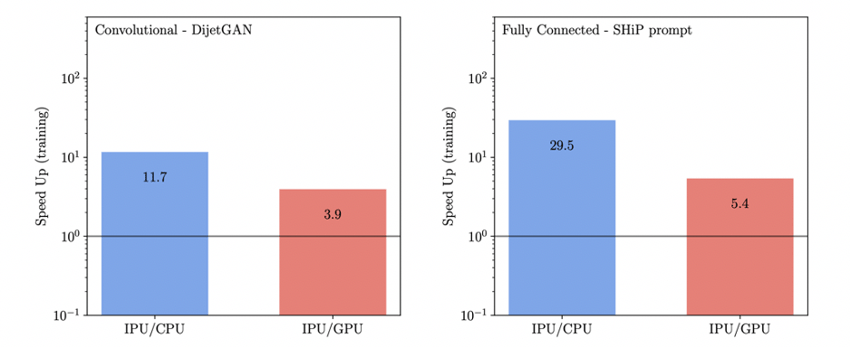
Figure 1: IPU Speedups on DijetGAN and SHiP models generating simulated data
In particle physics, the trajectory of electrically charged particles is tracked using a detector. Particle tracks are composed of individual readings across a range of detectors which need to be reconstructed into a single coherent track in order to calculate the path traversed by a particle. This data is noisy and subject to various scattering effects. The researchers demonstrated that a second application of a GAN could correct the scattering. This kind of application requires a complex model to produce analysis-quality data, and therefore requires low latency to be a viable solution to the real-time reconstruction challenges faced in particle physics.
The strongest performance of the IPU comes at low batch sizes which are of particular interest to applications of GANs. Training a GAN typically occurs at low batch sizes, where the improvement in throughput would allow models to be trained much faster.
In a complex evolving environment, such as those at particle colliders, this is a vital consideration. The ability to retrain and retune simulation data regularly as conditions change is essential for high-quality analyses.
Similar performance was seen for the reconstruction algorithm which directly benefits from the low batch size performance of the IPU. The researchers found for this more complex generative network that the IPU consistently outperformed the GPU across all batch sizes, with the generation rate saturating higher than the GPU.
Real-time reconstruction occurs at low batch sizes. The IPU significantly outperformed the GPU at a best throughput rate of 4.5x higher.
This performance directly translates to a lower latency that is essential for any real-time application. The lower latency enabled by the IPU would make it possible to use a more complex model for inference, whereas this would not be an option with a GPU.
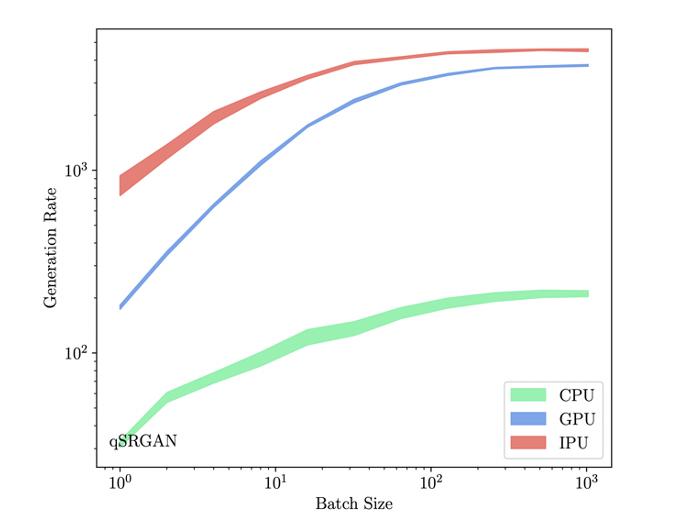
Figure 2: qSRGAN performance for CPU, GPU and IPU
Particle Identification
Particle identification is essential for processing data read from HEP experiments and is primarily achieved using a variety of neural networks including Recurrent Neural Networks (RNNs).
Inference speed is the critical metric for such applications due to the vast amount of data to sift through, regardless of whether or not the classification is run in real time.
The researchers found even on very small lightweight networks that the IPU outperformed the GPU for inference throughput with the RNN at all batch sizes.
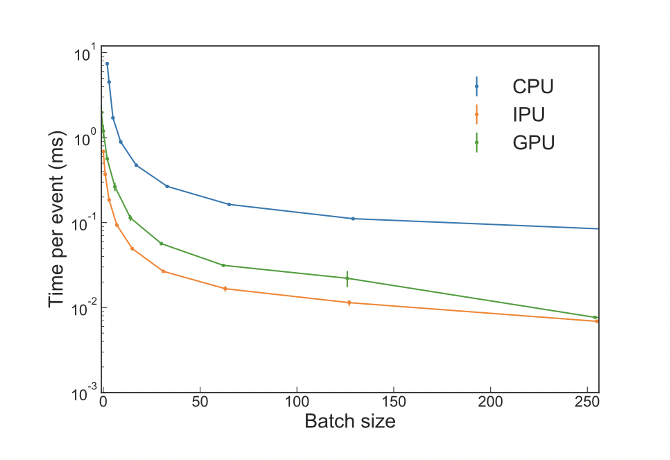
Figure 3: Recurrent neural network execution time per event as a function of the batch size
Kalman Filters
Kalman Filters are ubiquitous across many areas of physics and engineering. They probabilistically combine noisy time series measurements to compute estimates of an unknown variable that describes the underlying data.
The researchers demonstrated an implementation of a Kalman Filter on the IPU as part of a track reconstruction process.
In real experimental situations, the Kalman Filter stage of reconstruction is a significant contributor to the total latency. Since higher data rates are expected as particle colliders are upgraded, reducing this latency is a major goal.
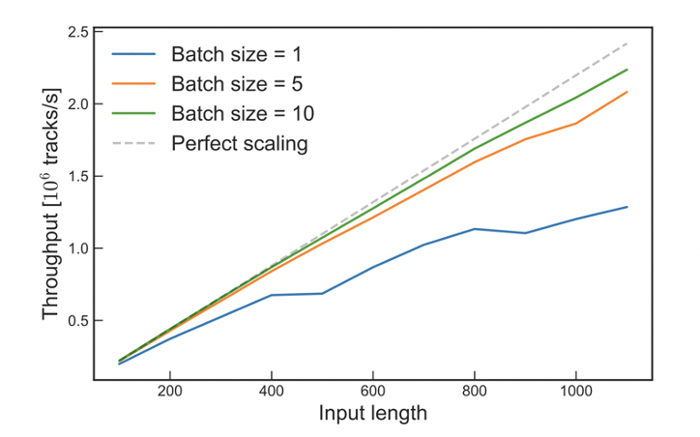
Figure 4: IPU Performance with Kalman Filters as a function of batch size
The Kalman Filter is a kind of process typically handled with traditional HPC solutions. The unique MIMD (Multiple Instruction Multiple Data) architecture of the IPU lends itself well to these kinds of algorithms, as each of the processor’s 1216 IPU-TilesTM can operate independently of each other on different data.
Each tile can be used to compute stages of the Kalman Filter, resulting in over 1000 tracks computed in parallel on each chip.
As the batch size increases, each tile can store multiple tracks. Results for a batch size of 10 show the throughput on the chip approaching perfect scaling, which is logical since every chip executes in parallel.
An IPU could be used to read the data from each event at a collider and process it in parallel on a single chip, removing significant data transfer overheads.
This finding has great significance outside HEP, as the Kalman Filter is an essential tool in the fields of robotics, navigation and automation.
Future Innovations in Particle Physics
While the Large Hadron Collider promises to unlock the secrets of the Universe, physically smashing particles together is only part of the technical challenge researchers are grappling with.
CERN generates an almost incomprehensible volume of experimental data, which needs to be captured and processed if meaningful insights are to be extracted.
At the same time, there is a parallel requirement to generate and analyse simulated particle events. Due to the probabilistic nature of quantum mechanics and the stochastic nature of a particle collider experiment, the simulated data must be at least an order of magnitude greater than the real data.
Add to that the fact that both classes of data are growing exponentially, and it is little wonder that physicists are looking at cutting-edge systems to address the growing deficit in compute.
As particle physics moves into the next phase with even greater quantities of data, novel computing solutions will be needed to continue to enable new discoveries. These solutions are jointly algorithmic and hardware-based, and continue to blend HPC and accelerated AI as a toolkit for the future of big data analysis.
The researchers from the University of Bristol have demonstrated that the IPU provides a competitive advantage over traditional GPUs across many domains. Their work represents the first ever study evaluating the performance of IPUs in High Energy Physics, with their experiments spanning the full lifecycle of a particle physics analysis, from event generation and flavour tagging to reconstruction and modelling.
They pushed the IPU beyond traditional machine learning applications, determining that low batch size and on-chip memory resulted in higher throughput at lower latency, and they explored the unique possibilities that the MIMD architecture offers for highly parallel compute.
The IPU allows researchers to run more complex algorithms and to accelerate existing models. This is essential in a field of research that continuously redefines the definition of big data in the search for answers to the most fundamental questions in the universe.
More information on these experiments is available to read in a new paper from the University of Bristol’s Lakshan Ram Madhan Mohan, Alexander Marshall, Daniel O’Hanlon, Konstantinos Petridis and Jonas Rademacker, and Graphcore’s Samuel Maddrell-Mander, Victoria Rege and Alexander Titterton. The paper has been submitted for peer review and is now available as pre-print on arXiv:2008.09210 [physics.comp-ph].
For researchers based in Europe like Professor Jonas Rademacker who need to process their data safely within the EU or EEA, the smartest way to access IPUs is through G-Core’s IPU Cloud.
With locations in Luxembourg and the Netherlands, G-Core Labs provide IPU instances fast and securely on demand through a pay-as-you-go model with no upfront commitment. This AI IPU cloud infrastructure reduces costs on hardware and maintenance while providing the flexibility of multitenancy and integration with cloud services.
The G-Core AI IPU cloud allows researchers to:
Share:


