
Jun 29, 2021
Jun 29, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamWe’re excited to announce the availability of our latest software release – Poplar SDK 2.1. With this release, we’ve been focusing on optimisations to improve BERT fine-tuning and similar large-scale applications as well as a wide range of enhancements for production deployment.
We’ve also refreshed our Developer portal, giving IPU programmers better visibility of all our resources designed to support their software development experience with IPU hardware.
In our newly updated portal's model garden, developers can easily search and access a repository of optimised AI applications across multiple machine learning frameworks for deployment on the IPU including BERT, ResNet-50, EfficientNet, ResNeXt-101, and many more.
We’ve also made a new tutorials folder available on Graphcore’s GitHub to make it easier for developers to access tutorials, simple application examples and feature examples.
Here are all the new tutorials and resources resources we’ve just made available for IPU programmers which you can find on our Developer portal:
We continue to see performance improvements for a range of Natural Language Processing and Computer Vision models running on IPU with SDK 2.1. Since December 2020, ResNet-50 training alone has seen 2x higher throughput due to new software features and optimisations.
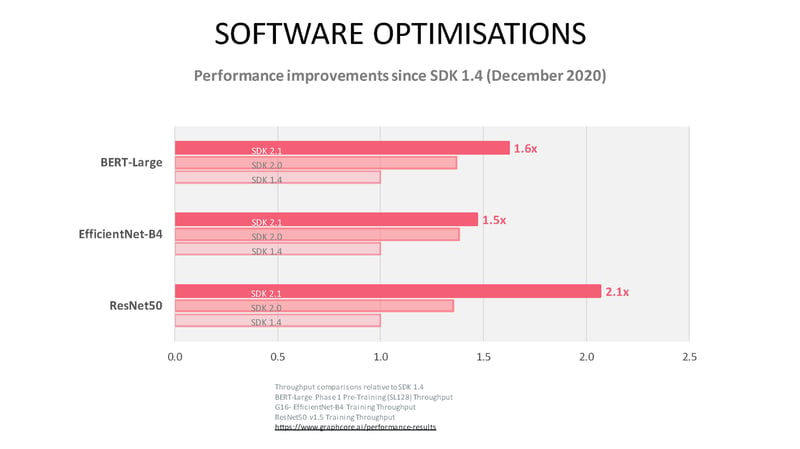 BERT-Large pre-training performance has improved, while fine-tuning has also seen significant optimisations with 856 sequences per second for BERT-Large SQuAD training. Read our recent blog and documentation for more insights into optimising BERT training for IPU systems.
BERT-Large pre-training performance has improved, while fine-tuning has also seen significant optimisations with 856 sequences per second for BERT-Large SQuAD training. Read our recent blog and documentation for more insights into optimising BERT training for IPU systems.
With variable sequence lengths for LSTMs and recompute on LSTM cells, developers will benefit from more flexibility when working with LSTMs.
AI engineers will be able to run even more time-series based models thanks to our latest CTC loss extensions and optimisations for both training and inference.
Data parallel scale-out support has also been added for pipelining with 8 IPUs. Learn more about pipelining on the IPU and how this can improve performance.
Other features in the release to improve performance and ease of use include compile time optimisations, single IPU recomputation optimisation, optimised application binary loading and large batch size convolutions support.
With optimised inference support for TensorFlow, we’ve further improved latency to help AI practitioners to maximise their performance at production scale.
We’ve also made a number of Poplar SDK and platform optimisations for error recovery and for stable inference latency in a production environment.
New PyTorch operations are supported in this release. Automatic mixed-precision casting has been added to allow developers to automatically convert their model between float16 and float32. A custom op is also now available for CTC beam search decoding, facilitating applications such as text recognition. Find out more about the other new PopTorch ops in SDK 2.1 in our PyTorch documentation.
Our award-winning PopVision application analysis tools have also been updated. With the PopVision Graph Analyser, developers can now visualise their machine learning models to better understand how they are mapped to IPU. The PopVision System Analyser now supports the Graph/Series data recorded by the libpvti library, allowing engineers to graph their own data over time. This SDK release also includes the libpva library which helps developers to programmatically analyse profile information.
Don’t forget to visit our newly refreshed Developer Portal and GitHub where you can access all the latest documentation, examples and tutorials to support you as you build applications and run your workloads with IPU systems.
Share:

