
May 06, 2021 \ IPU-POD, Natural Language Processing
May 06, 2021 \ IPU-POD, Natural Language Processing
공유:
BERT는 정확성과 유연성 덕분에 오늘날 가장 널리 사용되는 자연어 처리 모델 중 하나입니다. 그리고 그래프코어의 고객들이 가장 많이 요청하는 모델 중 하나이기도 합니다.
당사 엔지니어들은 광범위한 언어 기반 응용 분야를 지원하기 위해 IPU 시스템용 BERT를 구현하고 최적화하였으며, 산업 표준 머신러닝 교육 체계를 사용하여 우수한 처리량을 입증했습니다.
그래서 그래프코어가 IPU와 BERT 모델 학습에 관한 연재 포스팅을 기획해 봤습니다. 그 첫 번째인 이번 포스팅에서는 그래프코어의 애플리케이션, 소프트웨어 및 중국 엔지니어링 팀의 엔지니어들이 BERT-Large 구현을 위해 사전 학습 과정을 거치고 파인 튜닝하는데 사용한 최적화 기술에 대해 자세히 알아보겠습니다.
BERT(Bidirectional Encoder Representations from Transformers)는 구글(Google)이 만든 트랜스포머 기반의 언어 표현 모델로, 2018년 말에 출시된 이후 선풍적인 인기를 끌고 있습니다.
구글의 미국 영어 검색 쿼리의 약 10%에 대해 진행한 초기 시험을 거쳐, 오늘날 BERT는 거의 모든 영어 구글 검색에 사용되고 있습니다.
BERT 및 그 파생 모델들은 검색 엔진뿐만 아니라 질의 응답, 콘텐츠 기반 추천, 비디오 이해 및 단백질 특징 추출과 같은 다른 영역에도 적용되어 범용성을 입증했습니다.
GPT(생성적 사전학습 트랜스포머, GPT)와 같은 기존의 트랜스포머 모델과 다르게, BERT는 모든 트랜스포머 레이어에서 레이블되지 않은 각 학습 예제의 좌우 문맥을 활용하여 표현을 양방향으로 효과적으로 검색하도록 설계되었습니다. 이러한 양방향성은 다양한 다운스트림 작업에 더 큰 유연성을 부여합니다.
사전 학습 단계에서 레이블되지 않은 거대한 데이터 세트를 사용하는 BERT의 기능(그리고 미세 조정 단계에서 레이블이 지정된 적은 양의 데이터만으로 최첨단의 정확도를 달성한 것)은 BERT와 유사한 대규모 트랜스포머 기반의 언어 모델들을 매우 매력적으로 보이게 해 줍니다. 그에 따라 이처럼 대규모의 신경망 언어 모델을 학습시키고 파인 튜닝하는 수요가 폭증하고 있습니다.
언어 모델링과 같은 대규모 작업 뿐만 아니라 매우 작은 규모의 다운스트림 작업도 이러한 접근법의 이점을 누릴 수 있습니다. 예를 들어 MRPC: Microsoft Research Paraphrase Corpus의 학습 예제는 3600개밖에 없지만, BERT-Base에서 BERT-Large로 모델 크기를 키움으로써 정확도가 84.4%에서 86.6%로 향상되었습니다. BERT 모델 변이형은 MRPC를 비롯한 많은 유사 벤치마크들에서 우위를 유지하고 있습니다.
머신 러닝 연구진과 엔지니어들이 이러한 언어 모델들의 작업 성능을 지속적으로 향상시키고자 함에 따라 언어 모델의 크기는 점차 커지고 있습니다. 이러한 현상은 BERT 모델의 변이형 내에서도, 그리고 1,750억 개의 매개변수를 가지고 있는 GPT-3과 같은 다른 최신 언어 모델에서도 동일하게 나타납니다.
이것은 모델링의 발전만으로 가능해진 것이 아닙니다. 더 높은 효율을 제공할 수 있는 새로운 인공 지능 하드웨어와 시스템의 개발도 합리적인 기간 안에 이와 같은 대규모 언어 모델의 학습을 가능하게 해 주는데, 잠재적으로 며칠 혹은 심지어 몇 시간 안에 수십억 개의 예제를 사전 학습시킬 수도 있습니다. 그래프코어의 IPU-POD는 이러한 성능 문제를 해결해 주고 연구진과 엔지니어들의 생산성을 크게 향상시켜 줍니다. IPU-POD는 초고성능의 인프로세서 메모리를 활용하여 데이터 이동을 최소화함으로써 뛰어난 계산 성능과 더 나은 전력 효율성을 제공합니다. 고속의 스케일아웃 인터커넥트 기능과 지능형 메모리 관리 기능을 통해 애플리케이션을 수백 개의 IPU로 효율적으로 스케일아웃할 수 있습니다.
IPU-POD에서는 BERT를 효율적으로 실행하기 위해 전체 모델의 매개변수를 IPU에 로드합니다. 이를 위해 BERT 모델을 4개의 IPU에 분할 또는 "샤딩 (shard)"하고, 학습 과정 중에 모델을 파이프라인으로 실행합니다.
아래에서 BERT-Large를 분할하는 방법의 예를 볼 수 있습니다. IPU 0에는 3개의 인코더 레이어와 함께 임베딩 레이어(embedding layer), 프로젝션/손실 레이어(projection/loss layers)가 포함되어 있으며 나머지 21개 레이어는 다른 3개의 IPU에 고르게 분포되어 있습니다. 임베딩 및 프로젝션 레이어는 매개변수를 공유하기 때문에 프로젝션, MLM(Masked Language Model) 및 NSP(Next Sentence Prediction) 레이어를 다시 IPU 0에 배치할 수 있습니다.
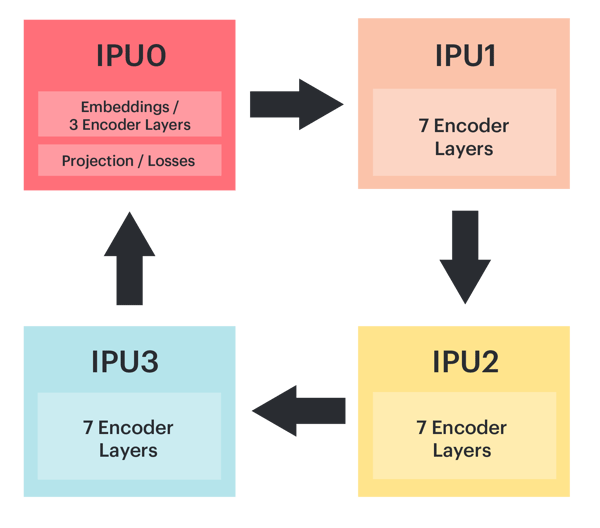
그래프코어는 칩의 메모리 사용량을 줄이기 위해 재계산(recomputation) 기능을 사용합니다. 따라서 역방향 패스를 계산할 때 사용하기 위해 중간 레이어 활성화를 저장할 필요가 없는데요. 재계산은 모델을 학습시킬 때 사용할 수 있는 전략으로, 파이프라인 전략을 구현할 때 특히 유용합니다. 파이프라인을 통해 항상 복수의 배치가 ‘실행 중’이므로 재계산 기능을 사용하지 않으면 저장된 활성화의 크기가 매우 커질 수 있습니다.
사전 학습 시스템의 옵티마이저(Optimizer) 상태는 스트리밍 메모리(Streaming Memory)에 저장되고 옵티마이저 단계 중 요청에 따라 로드됩니다.
스트리밍 메모리는 그래프코어에서 오프칩 메모리(off chip memory)를 일컫는 용어입니다. IPU-POD64 내의 각 핵심 ‘빌딩 블록’인 IPU-M2000에는 4개의 IPU 프로세서로 실행되는 최대 450GB의 메모리가 탑재되어 있습니다. 이는 모든 IPU 칩에 포함된 900MB의 인프로세서 메모리와 IPU당 최대 112GB의 오프칩 스트리밍 메모리로 나뉩니다. 이 스트리밍 메모리는 IPU 머신의 DDR4 DIMM에서 지원됩니다.
GitHub의 그래프코어 예제에서 TensorFlow, PyTorch, PopART에서의 IPU로 구현한 BERT를 확인하실 수 있습니다.
TensorFlow 구현은 그래프코어의 TensorFlow 파이프라인 API를 활용하기 위한 사용자 정의 및 확장을 통해 기존 Google BERT 구현과 모델 코드를 공유합니다.
PyTorch 구현은 Hugging Face 트랜스포머 라이브러리의 모델 설명과 유틸리티를 기반으로 합니다. 파이프라인 실행(pipeline execution), 재계산(recomputation), 다중 복제/데이터 병렬 처리(multiple-replica/data parallelism) 등을 포함해, IPU를 위해 그래프코어 PopTorch 라이브러리를 사용합니다.
Poplar Advanced Runtime(PopART)을 이용한 BERT 구현도 Github에서 확인하실 수 있는데요. PopART를 사용하면 학습 및 추론을 위해 ONNX 모델 설명에서 모델을 가져오거나 생성할 수 있으며, C++ API와 파이썬 API가 모두 포함됩니다. 이 논문에 설명된 대로 PopART는 옵티마이저, 기울기(gradient), 매개변수(parameter) 분할을 지원하는데요, 이를 포괄하여 텐서 샤딩(RTS: Revided Tensor Sharding)이라고 부릅니다. PopART의 복제된 파이프라인 모델-병렬 BERT 시스템의 경우, 옵티마이저 및 그래디언트 파티셔닝(gradient partitioning)을 사용하고 있습니다.
자율 사전 학습의 경우, BERT는 위키피디아, BookCorpus 및 기타 출처의 수십억 가지 학습 예제를 활용할 수 있습니다. IPU-POD4를 사용하는 경우에도 이러한 대용량 데이터 세트를 다수 통과하려면 상당한 시간이 걸립니다. 학습 시간을 단축하기 위해 우리는 데이터 병렬 모델 학습을 사용하여 사전 학습 프로세스를 IPU-POD16, IPU-POD64 이상으로 스케일할 수 있습니다.
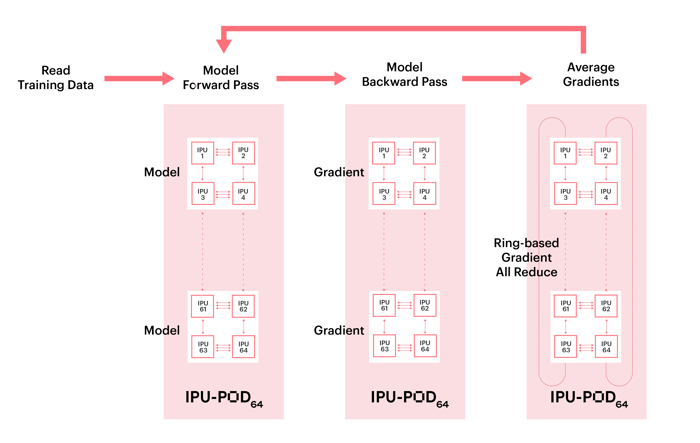
데이터 병렬 학습은 학습 데이터 세트를 여러 부분으로 나누며, 각 부분은 모델 복제에 의해 사용됩니다. 각 최적화 단계에서 그래디언트는 모든 복제에서 평균적으로 감소하므로 모든 복제에서 가중치 업데이트 및 모델 상태가 동일합니다.
그래디언트 감소 기능은 고성능 스케일 아웃을 지원하도록 설계된 포플라(Poplar) 소프트웨어 스택의 확장인 Graphcore 커뮤니케이션 라이브러리(GCL: Graphcore Communication Library)를 사용합니다. GCL에는 매우 효율적인 링 기반 All-Reduce와 다른 많은 일반적인 커뮤니케이션 프리미티브(primitives)가 포함되어 있습니다. 아래 이미지에 나와 있는 것처럼 모든 복제에 대해서 그래디언트의 평균값이 산출되며, 모든 멀티 복제 그레이디언트가 완전히 감소하면 가중치 업데이트가 한 번에 적용됩니다.
데이터 병렬 그래디언트 감소는 옵티마이저 래퍼 기능(optimizer wrapper functions)을 사용하거나 사용자 정의 옵티마이저 정의(custom optimizer definitions)를 보다 세밀하게 제어하여 자동으로 추가할 수 있습니다. 이러한 감소는 IPU-POD 내에서 또는 서로 다른 IPU-POD 간에 균일하게 발생할 수 있습니다.
TensorFlow에서 API가 작동하는 방식에 대한 자세한 내용은 TensorFlow 사용 설명서에서 복제된 그래프에 대한 정보를 참조하시면 됩니다.
PyTorch의 경우, 우리는 PopTorch IPU 모델 옵션에 복제 지수(replication factor)를 설정합니다.
모델의 병렬 스케일링 효율성에 기여하는 주요 요소 중 하나는 그래디언트가 얼마나 자주 통신할 수 있는 지입니다. 우리는 그래디언트 축적(GA: Gradient Accumulation)을 사용하여 컴퓨팅 또는 마이크로 배치 크기를 글로벌 배치 크기와 분리합니다. 또한 그래디언트 축적 지수를 조정하여 IPU 및/또는 복제 수를 변경할 때 일관된 글로벌 배치 크기를 유지할 수 있습니다. 글로벌 배치 크기 = 복제 배치 크기 x 복제 수(global batch size = replica batch size × number of replicas), 여기서 복제 배치 크기 = 컴퓨팅 배치 크기 x 그래디언트 축적 지수(replica batch size = compute batch size × gradient accumulation factor).
복제 수가 고정된 경우, 글로벌 배치 크기가 클수록 GA 지수가 높고 옵티마이저와 통신 단계가 줄어듭니다.
하지만 GA가 수천 개로 너무 크면 FP16의 언더플로(underflow) 문제가 발생할 수 있습니다. 작은 GA의 경우 여기에 설명된 대로 버블 오버헤드(bubble overhead)로 인해 파이프라인 효율이 낮아질 수 있습니다. 최적의 값을 찾기 위해서는 몇 가지 실험이 필요할 수 있습니다.
다음 섹션에서는 BERT를 학습할 때 활용하는 학습 속도, 워밍업 및 최적화 프로그램을 검토합니다.
SGD 미니배치를 이용한 ImageNet 학습에 관한 이 논문에서 연구원들은 ResNet-50 및 Mask R-CNN을 위한 대규모 글로벌 배치를 학습시킬 때 선형 스케일링 규칙을 사용했습니다. 이 규칙은 복제 배치 크기 ƞ에 k를 곱할 때(여기서 k는 일반적으로 모델 복제 수임), 기본 학습 속도 ƞ에 k를 곱하고 이 값을 kƞ로 설정합니다.
글로벌 배치 크기를 n에서 nk로 늘리면 동일한 수의 학습 횟수(training epoch)를 사용하고 테스트 정확성을 유지하는 동시에 총 교육 시간을 k의 지수만큼 줄이고 모델-생산 시간을 크게 단축할 수 있습니다. 그러나 작업 성능은 대규모 글로벌 배치의 경우 떨어지는 것을 입증되었습니다.
이를 완화하는 한 가지 방법은 바로 워밍업입니다. 워밍업 시 학습 속도는kƞ로 즉시 초기화되지 않는데요. 대신, 학습 과정은 0으로 시작하거나 임의의 작은 학습 속도로 시작하여 사전 정의된 워밍업 단계 수에 따라 연속적으로 증가하여 kƞ에 도달합니다. 이러한 점진적 워밍업을 통해 더 적은 수의 단계로 대규모 글로벌 배치 학습을 수행하여 더 작은 배치 크기와 유사한 교육 정확도를 얻을 수 있습니다. SGD 미니배치를 다룬 ImageNet 학습 논문에서 이 학습을 통해 글로벌 배치 크기가 약 8,000인 학습이 가능한 것을 확인했습니다.
사전 정의된 워밍업 단계는 BERT-LARGE 사전 학습 사례의 1단계와 2단계에서 다르게 나타납니다. BERT 논문에서와 같이, 1단계에서는 최대 시퀀스 길이가 128이고 2단계에서는 최대 시퀀스 길이가 384인 학습 데이터를 사용합니다. 1단계 워밍업의 수는 2,000개로 1단계에서 전체 교육 단계의 약 30%를 차지하는데, 이에 비해 2단계의 워밍업 수는 총 2,100개이며, 이 단계의 약 13%가 워밍업 단계입니다.
워밍업 단계는 서로 다른 사전 학습 데이터 세트에 맞게 조정해야 할 수도 있습니다.
표준 확률적 그래디언트 하강 알고리즘(standard stochastic gradient descent algorithm)은 모든 가중치 업데이트에 대해 단일 학습 속도를 사용하며 학습 중에 일정한 속도를 유지합니다. 반대로 적응 모멘트 추정(Adam: Adaptive Moment Estimation)은 그래디언트의 첫 번째 및 두 번째 모멘트의 이동 지수 평균을 사용하고 이러한 모멘트를 기준으로 학습 속도 매개변수를 조정합니다.
ICLR 2019년 논문에서 Loshchilov와 Hutter 연구원은 L2 정규화가 Adam에서 효과가 없다는 사실을 알아냈습니다. 대신, 그들은 손실 기능에서 L2 정규화 대신 가중치 감소 정규화를 적용하는 AdamW를 제안했습니다. 이를 통해 가중치는 추가 상수 지수가 아니라 배수에 의해 감소됩니다. 또한 웜 재시작이 가능한 AdamW가 CIFAR-10 및 ResNet32x32 모두에서 학습 손실과 일반화의 오류 측면에서 더 우수하다는 것을 입증하였습니다.
IPU-POD16 BERT 사전 학습에서 우리는 AdamW로 512~2560의 사전 학습 글로벌 배치 크기를 사용하여 실험을 진행하였으며, 모든 사례가 SQuAD 다운스트림 작업에 맞춰 미세 조정되면서 기준 정확도에 수렴하는 성과를 보였습니다.
LAMB 옵티마이저(자세한 내용은 여기에 설명되어 있음)는 배치 크기가 증가할 때 발생하는 그래디언트 불안정 및 손실 이탈을 극복하여 배치 크기를 더 크게 유지할 수 있도록 설계되었습니다. LAMB은 레이어 와이즈 적응 속도 스케일링(LARS: layer-wise adaptive rate scaling)과 동일한 레이어 와이즈 정규화 개념을 사용하므로 학습 속도가 레이어에 민감합니다. 그러나 매개변수 업데이트의 경우 AdamW의 모멘텀 및 분산 개념을 사용합니다.
각 레이어의 학습 속도는 다음과 같이 계산됩니다.
\[\eta \frac{ \| x \| } { \| g \| }\]
여기서 \(\eta\) 는 전체 학습율이고, \(\| x \|\) 는 이 계층의 매개변수의 기준이며 \(\| g \|\)는 동일한 AdamW 옵티마이저에 대한 업데이트의 기준입니다.
즉, LAMB이 업데이트를 정규화하고 \(\|x\|\)를 곱하여 각 레이어의 매개변수와 동일한 크기 정도를 갖게 함으로써 업데이트가 각 레이어의 실질적인 변화를 가능하게 합니다. 그 다음 결과값에 전체 학습 속도 \(\eta\) 를 곱합니다.
LAMB의 경우, 가중치와 편향은 서로 다른 신뢰값을 가지고 있어 서로 다른 학습 요율로 취급해야 하므로 두 개의 분리된 레이어로 간주됩니다. 편향 및 감마, 배치-표준 (batch-norm)또는 그룹-표준(group-norm) 베타 버전은 레이어 개조에서 제외되는 경우가 많습니다.
BERT의 경우, LAMB은 단계 1에서 최대 65,536의 글로벌 배치 크기와 단계 2에서 최대 32,768의 글로벌 배치 크기를 사용할 수 있습니다.
딥 러닝의 초기에는 많은 모델들이 32비트 정밀 부동소수점 연산 방식(32-bit precision floating-point arithmetic)으로 학습 받았습니다. 낮은 정밀도를 사용하는 것은 컴퓨팅 처리량이 둘 다 향상되기 때문에 매력적입니다. IPU의 경우 FP16 피크 성능이 FP32보다 4배 더 높습니다. 정밀도가 낮을 때 텐서 크기가 2배 감소하여 메모리 압력 및 통신 비용이 절감됩니다.
그러나 FP16 정밀 부동소수점은 FP32보다 정밀도가 낮고 동적 범위가 낮습니다. 하지만 다른 한편으로 FP16을 사용하여 FP32 가중치 그래디언트 누적을 통해 마스터 가중치의 FP32 복사본을 유지하면서 손실 스캐일링을 사용하여 활성 및 그래디언트의 동적 범위를 관리하는 순방향 패스(활성화,activations) 및 역방향 패스(그래디언트) 계산을 제안하는 사람들도 있습니다.
우리는 FP16에서 활성화 및 그래디언트를 학습할 때 손실 스케일링을 유사한 방식으로 구현합니다.
Graphcore IPU는 확률적 반올림(stochastic rounding)과 기존 IEEE 반올림 모드를 사용할 수 있습니다. 확률적 반올림은 해당 값이 위쪽 및 아래쪽 반올림 경계에 근접한 정도에 비례하여 달라집니다. 많은 수의 학습 예제를 이용해 편향되지 않은 반올림 결과를 얻을 수 있습니다.
확률적 반올림 방식을 사용하면 전체 학습 과정 동안 엔드 투 엔드 학습 또는 다운스트림 작업 성과의 정확성이 눈에 띄게 저하되지 않으면서 FP16에 가중치를 유지할 수 있습니다.
옵티마이저의 첫 번째와 두 번째 모멘트가 계산되어 FP32에 저장되고, 정규화도 FP32에서 수행됩니다. 학습 프로세스의 나머지 작업은 FP16에서 계산됩니다.
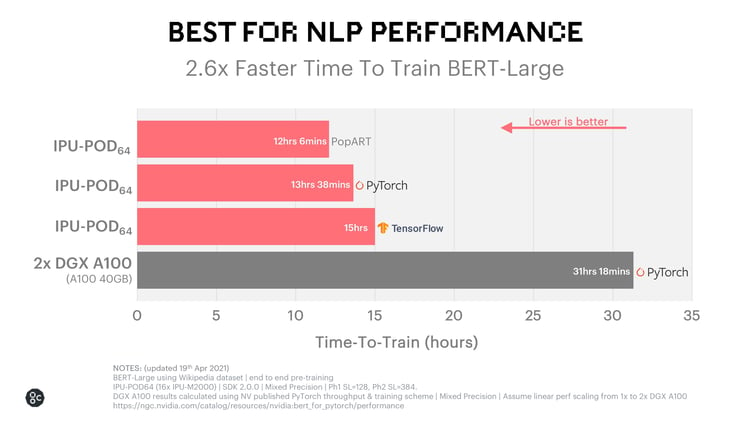
그래프코어의 최신 스케일아웃 시스템은 동급 DGX A100 기반 시스템에 비해 학습 시간을 최대 2.6배 더 단축하여 BERT-Large 학습에서 전례 없는 효율성을 보여줍니다.
최신 IPU-M2000 가속기 16개가 포함된 IPU-POD64는 컴퓨팅, 통신 및 메모리 기술의 혁신을 통해 BERT-Large에서 선도적인 AI 플랫폼과 동일한 정확도를 더욱 짧은 시간 내에 제공합니다. 아래 도표는 TensorFlow 및 PyTorch의 표준 상위 수준 프레임워크를 사용한 결과와 그래프코어의 PopART 기반 구현 결과를 보여줍니다. 이 결과를 NVIDIA가 발표한 가장 우수한 PyTorch 결과와 비교하고 유사한 방법론을 사용하여 비슷한 학습 시간(Time-To-Train) 결과를 도출했습니다.
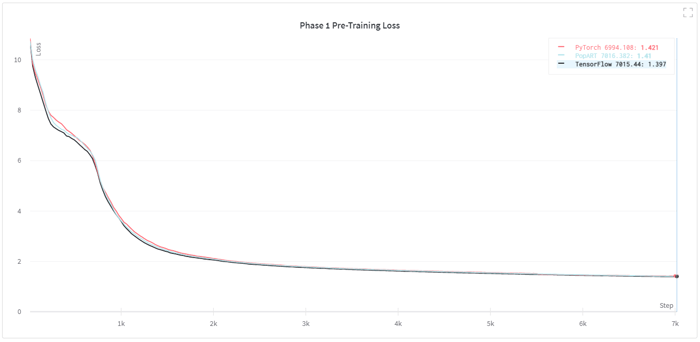
아래 차트는 TensorFlow, PyTorch 및 PopART 구현에 대한 사전 학습 손실 곡선을 나타내는데, 동등한 최종 학습 손실(final training loss)에 대한 수렴과 서로 매우 유사한 학습 곡선을 보여줍니다. 또한 이 차트에는 IPU-POD16 및 IPU-POD64에서 세 가지 모델을 모두 구현했을 때의 학습 처리량이 표시되어 있습니다.
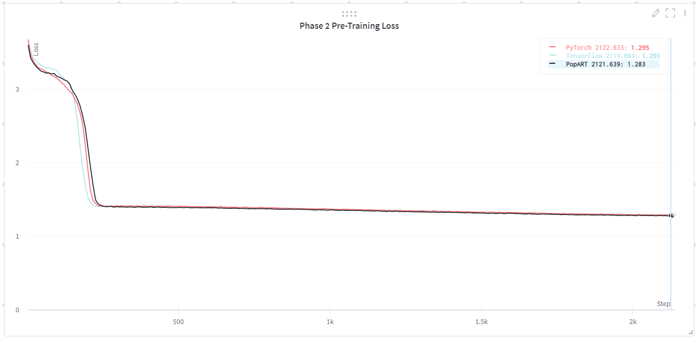
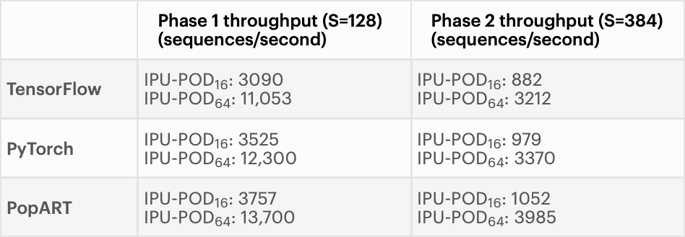
수억 개의 학습 예제를 필요로 하는 BERT를 충분히 학습시킨 후, 미리 학습된 이 가중치를 레이블이 지정된 적은 양의 데이터를 이용하여 태스크별 파인튜닝 학습 프로세스의 초기 가중치로 사용할 수 있습니다.
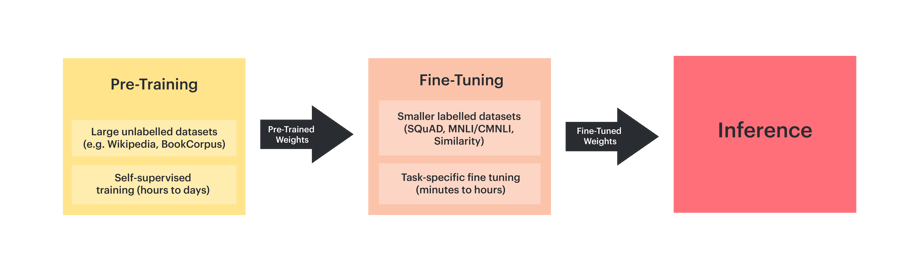
이 2단계 설정 방식은 다음과 같은 이점을 제공하기 때문에 실제로 널리 사용됩니다.
파인튜닝은 학습 데이터 세트의 크기에 따라 IPU POD4 또는 IPU POD16에서 몇 분 내지 몇 시간 내에 완료할 수 있습니다. 많은 파인튜닝 학습이 소량의 학습 세트 패스오버가 처리된 이후에 중지될 수 있습니다.
스탠포드 질의 응답 데이터 세트(SQuAD: Stanford Question Answering Dataset) v1.1은 500개 이상의 논문에 있는 100,000개 이상의 질의 응답 쌍이 포함된 대규모 독해력 데이터 세트입니다.
아래 표는 사전 학습된 참조 및 IPU 사전 학습 가중치를 사용하여 IPU에서 SQuAD v1.1 작업을 통해 BERT-Large를 파인튜닝할 때의 정확도를 보여줍니다. 시연된 바와 같이, IPU는 이 작업에서 높은 참조 정확도를 보여주고 있습니다.
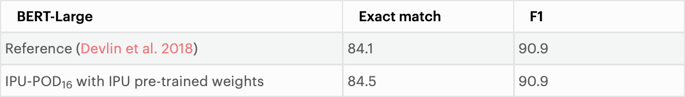
다음에 살펴볼 데이터 세트는 사전 학습된 Google 가중치를 사용하여 IPU에서 중국어 이해도 평가(CLUE: Chinese Language Understanding Evaluation) 작업과 함께 BERT-Base를 파인튜닝할 때의 정확도를 보여줍니다.
CLUE 점수는 모든 CLUE 작업에 대한 테스트 정확도의 평균입니다. 각 작업의 테스트 정확도는 5가지 실험 결과의 평균입니다. 아래 표에 나와 있는 것처럼 IPU는 DGX-1 V100과 같은 AI 플랫폼과 동일한 정확도를 달성할 수 있습니다.

AI 전문가는 몇 가지 기능 최적화를 통해 IPU-POD 시스템을 사용하여 정확도를 유지하면서 BERT-Large의 학습 시간을 크게 단축할 수 있습니다. 지금까지 살펴본 바와 같이 새로운 하드웨어 아키텍처에서 BERT와 같은 대형 모델을 실행하는 것이 생각보다 매우 간단합니다. 많은 개발자분들은 여기에 설명된 최적화 기술에 이미 익숙하실 수도 있습니다. 또한 우리는 TensorFlow 및 PyTorch 구현 자료를 공개하여 모든 머신러닝 전문가가 이러한 프레임워크를 사용하여 IPU에서 BERT를 실행하는 방법을 살펴볼 수 있도록 했습니다.
BERT와 같은 대형 모델을 이용해 최상의 작업 성능을 달성하기 위한 연구자와 엔지니어들의 기대가 점점 더 증가하면서 하드웨어 효율성이 중요한 역할을 하게 될 것입니다. 지금까지 우리는 IPU-POD 시스템을 사용했을 때 BERT-Large 및 유사 모델의 정확도뿐만 아니라 상당한 성능 향상의 이점도 얻을 수 있다는 것을 알 수 있었습니다. IPU 프로세서 아키텍처의 고유한 특성은 오늘날 가장 선진 모델의 성능을 가속화하는 동시에 우리에게 익숙한 소프트웨어 환경에 어울리는 미래의 최첨단 모델을 개발하는 데에도 아이디어를 제공합니다.
James Briggs, Oskar Bunyan, Lorenzo Cevolani, Arjun Chandra, Nic Couronneau, Lakshmi Krishnan, Guoying Li, Visu Loganathan, Sam Maddrell-Mander, Zhiwei Tian, Sylvain Viguier, Xian Wang, Xihuai Wen, ChengShun Xia, Han Zhao.
위의 이름 외에도, IPU 시스템에서의 BERT의 구현 및 최적화를 지원해 주신 그래프코어의 BERT 어플리케이션, PopART, TensorFlow, PyTorch, GCL 및 Poplar 팀에도 감사드립니다.
공유:


