
Oct 21, 2021 \ Product, IPU-POD, Cloud
Oct 21, 2021 \ Product, IPU-POD, Cloud
공유:
그래프코어가 최신 AI 연산 시스템 IPU-POD128과 IPU-POD256을 출시했습니다. 이 두 제품은 그래프코어가 지금까지 선보인 AI 연산 시스템 중 가장 높은 성능을 자랑하는 데요, 애초부터 머신 인텔리전스 확장을 위해 특별 설계된 아키텍처로써 강력한 이점을 갖추고 있습니다.
각각 32페타플롭스(PFlops, 초당 32,000조번 연산), 64페타플롭스의 AI 연산속도를 제공하는 IPU-POD128과 IPU-POD256을 통해 그래프코어는 AI 슈퍼컴퓨터 영역에서 그 역량을 한층 확대할 수 있게 됐습니다.
클라우드 하이퍼스케일러, 국립 과학 컴퓨팅 센터는 물론, 금융 서비스나 제약 업계에서 대규모 AI 팀을 운영하는 기업에 이상적인 신형 IPU-POD는 시스템 전반에 걸쳐 대형 트랜스포머 기반 언어 모델을 빠르게 훈련시키고, 프로덕션 환경에서 대규모 상용 AI 추론 애플리케이션을 구동하는 것이 특징입니다. 뿐만 아니라, 시스템을 더 작고 유연한 vPOD로 분할해 개발자들의 IPU 활용도를 높이고, GPT 및 그래프신경망(GNN) 같은 새로운 모델을 활용해 과학적 발견을 가속화하도록 지원합니다.
IPU-POD128과 IPU-POD256 모두 현재 Atos 및 기타 시스템 통합 파트너를 통해 출하되며, 그래프클라우드(Graphcloud)를 통해서도 이용 가능합니다. 그래프코어는 또한 고객들이 IPU 기반 AI의 혜택을 충분히 누릴 수 있도록 다양한 교육과 지원을 제공하고 있습니다.
광범위하게 사용되고 있는 언어 및 비전 모델을 활용한 벤치마크 테스트 결과에서는 인상적인 훈련 성능과 매우 효율적인 확장을 보여주었는데요, 향후 소프트웨어 개선을 통해 이러한 성능은 더욱 향상될 것으로 예상됩니다.
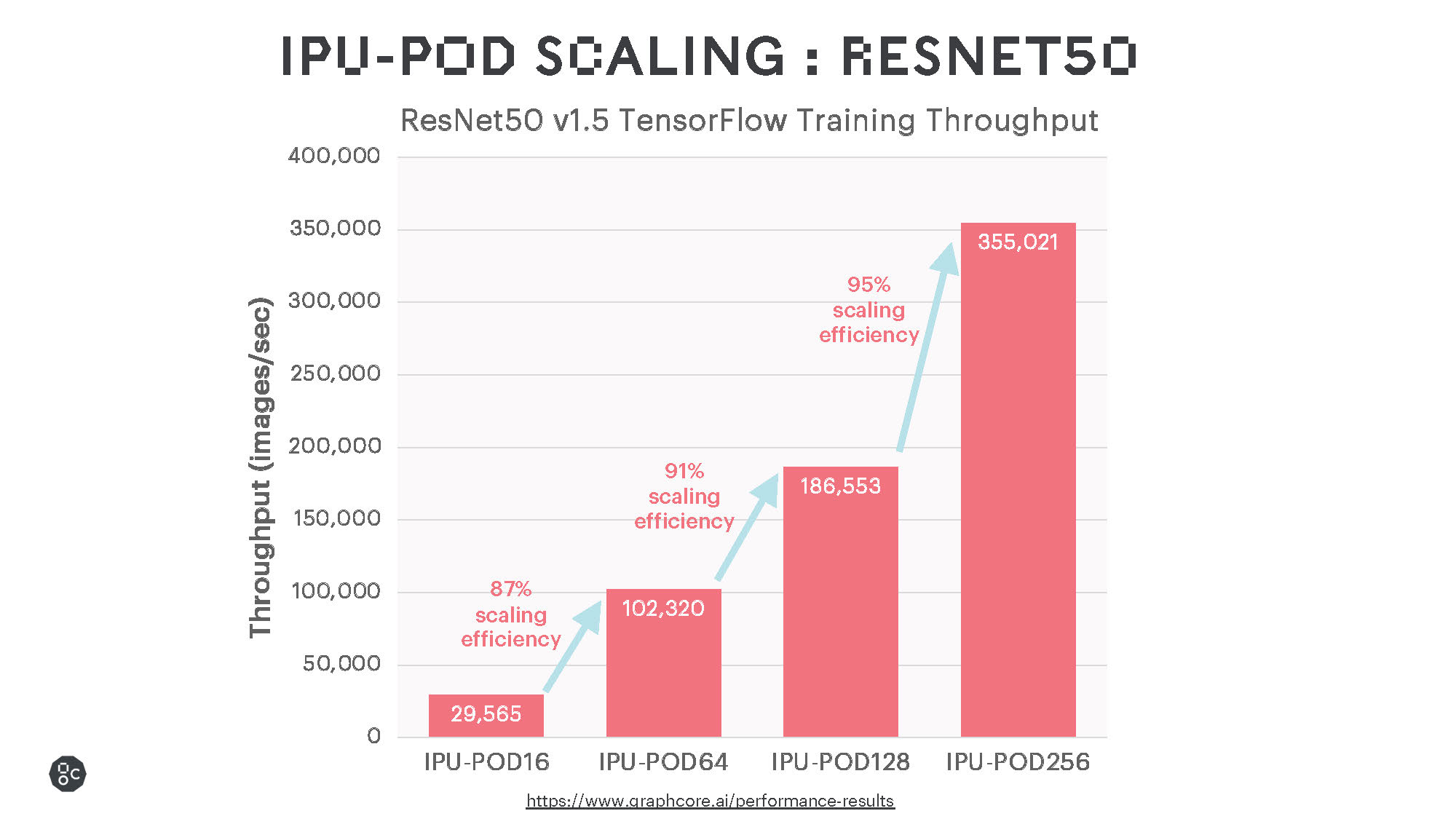
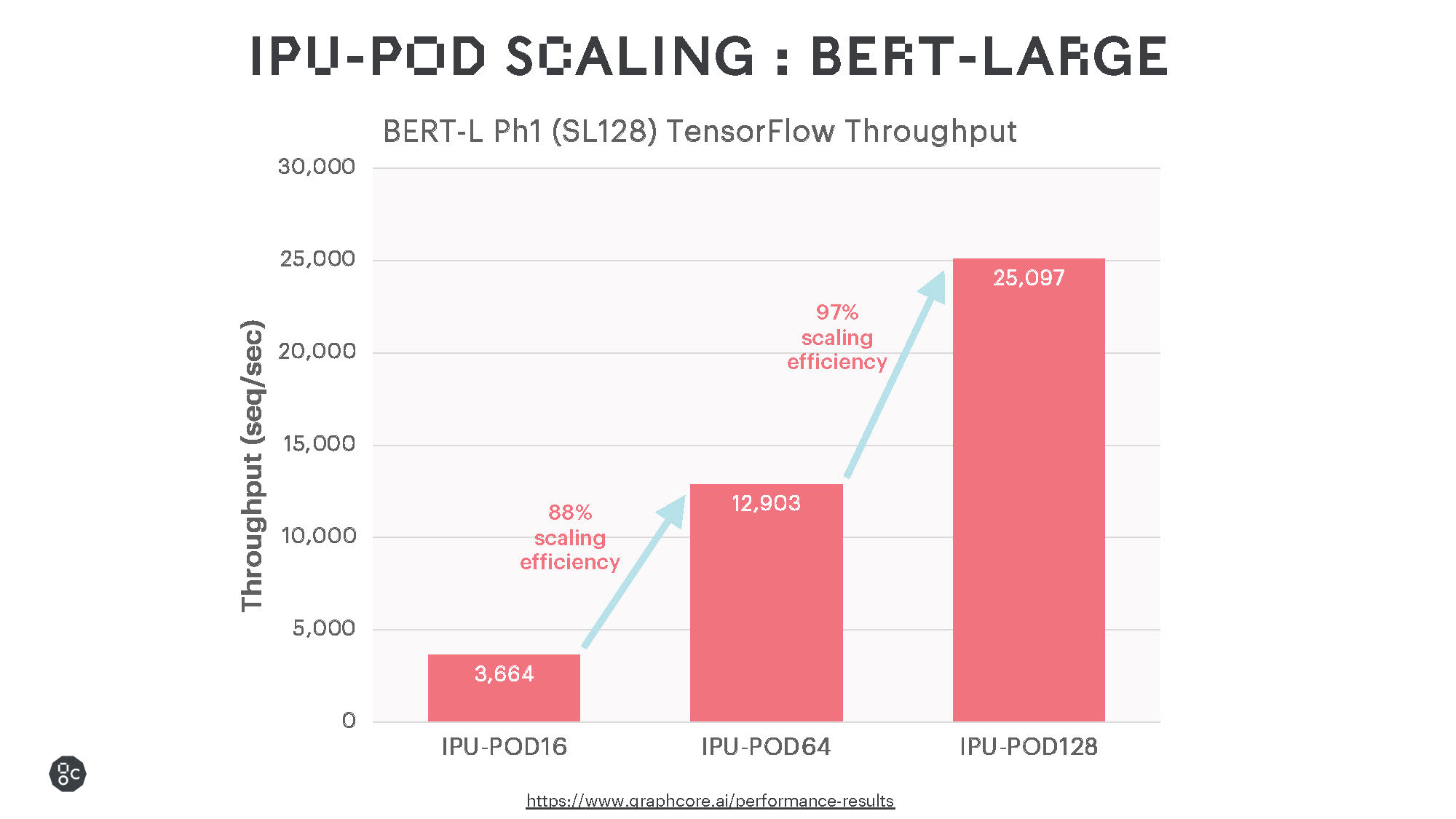
IPU는 프로세서에 메모리가 통합돼 있어 BERT, ResNet-50과 같은 기존의 대형 MatMul 모델에 탁월한 성능을 제공할 뿐 아니라, 일반적인 유형의 연산도 지원하여 희소 곱셈이나 더욱 세분화된 연산도 보다 효율적으로 수행합니다. 이러한 특성은 EfficientNet 모델군은 물론, 그래프 신경망(GNN)이나 여러 비신경망 머신러닝 모델에도 유용합니다.
Atos는 전 세계 고객에게 IPU-POD128과 IPU-POD256을 제공하는 수많은 그래프코어 파트너 중 한 곳입니다.
Atos의 수석 부사장 겸 HPC 및 양자컴퓨팅 담당 총괄인 아그네스 부도(Agnès Boudot)는 "그래프코어의 IPU-POD128과 IPU-POD256 시스템을 당사 Atos ThinkAI 포트폴리오에 추가함으로써, 연구, 금융, 의료, 통신 및 소비자용 인터넷을 포함한 여러 분야에 걸친 우리 고객들이 더욱 혁신적인 대규모 AI 모델을 탐색하고 구축할 수 있게 됐다”고 설명했습니다.
국내 선도적인 통신업체 KT는 IPU-POD128을 가장 먼저 도입한 고객 중 하나인데요, 이미 IPU-POD128이 제공하는 획기적인 연산 성능의 이점을 누리고 있습니다.
이미희 KT 클라우드·DX 사업본부장은 “KT는 국내 최초로 IDC 내에 고집적 AI Zone을 구축하고 그래프코어 IPU를 활용하여 ‘KT 하이퍼스케일 AI서비스’를 제공하고 있다. 현재 다양한 기업과 연구기관에서 해당 서비스를 이용하고 있거나, GPU에서 IPU로의 전환을 위한 테스트를 진행하고 있다”고 밝혔습니다.
이어, “KT는 이러한 호응에 힘입어 시장에서 지속적으로 요구되는 초대규모 AI HPC 환경 지원을 위해 2개의 그래프코어 IPU POD64를 확장 연결한 IPU POD128으로 ‘하이퍼스케일 AI 서비스’ 확대를 진행하고 있다”며, “이를 통해 32페타플롭스 수준의 AI 연산 처리가 가능하게 되어 더욱 다양한 고객들이 대규모 AI 모델에 대한 학습 및 추론에 활용할 수 있을 것으로 기대하고 있으며, 전력소모량의 최적화를 통환 친환경 AI연구개발에도 기여할 것으로 판단하고 있다”고 설명했습니다.
그래프코어는 이번 IPU-POD128과 IPU-POD256의 출시를 통해 AI 여정의 모든 단계에서 고객의 요구를 충족하겠다는 노력을 한층 가속화할 수 있게 됐습니다.
새로운 머신 인텔리전스 접근법을 탐구하는데 최적화된 IPU-POD16과 AI 연산 역량 구축에 이상적인 IPU-POD64에 이어, 더 빠른 혁신과 성장을 추구하는 고객을 위해 IPU-POD128과 IPU-POD256이 추가됐습니다.
IPU-POD128과 IPU-POD256은 여타 IPU-POD 시스템과 마찬가지로 AI 연산과 서버가 분리되어 여러 AI 워크로드에 가능한 최고의 성능을 제공하며, 이를 통해 최적의 총소유비용(TCO)을 실현합니다. 예를 들어, NLP 중심의 시스템은 IPU-POD128을 위해 단 2대의 서버가 필요한 반면, 컴퓨터 비전과 같은 보다 데이터 집약적인 작업에는 8대가 필요할 수 있습니다.
또한, 그래프코어가 최근에 발표한 그래프코어 스토리지 파트너의 기술을 활용하여 시스템 스토리지를 특정 AI 워크로드에 맞게 최적화할 수도 있습니다.
더불어, 다음을 비롯한 여러 하드웨어 및 소프트웨어 지원 기술을 활용하여 그래프코어 연산을 IPU-POD128과 IPU-POD256으로 확대할 수 있는데요.
그래프코어의 여타 모든 하드웨어와 마찬가지로 IPU-POD128과 IPU-POD256은 당사의 포플러(Poplar) 소프트웨어 스택과 함께 설계되었습니다.
또한 최신 버전인 SDK 2.3을 포함한 여러 포플러 소프트웨어 릴리스에 그래프코어의 스케일아웃 시스템을 작동케 하는 기능이 도입되었습니다. 아래는 모든 IPU-POD 시스템을 간편하게 확장시키는데 중요한 혁신적인 기능들인데요, IPU-POD128 및 IPU-POD256 규모의 시스템에서 실제로 해당 이점을 발견할 수 있었습니다.
그래프코어 통신 라이브러리(GCL)는 IPU 간 통신과 동기화를 관리하기 위한 소프트웨어 라이브러리로, IPU 시스템의 고성능 스케일아웃이 가능하도록 설계되었습니다. 컴파일 시 프로그램이 실행될 IPU 수 지정이 가능해 IPU가 2개 이상의 IPU-POD에 걸쳐 분산될 수 있습니다. 또한, IPU-POD 전체에서 자동으로 투명하게 실행되어 추가 비용이나 복잡성 없이 향상된 성능과 처리량을 제공합니다.
PopRun 및 PopDist: 개발자는 PopRun과 PopDist를 사용하여 여러 IPU-POD 시스템에 걸쳐 애플리케이션을 실행할 수 있습니다.
PopRun은 IPU-POD 시스템에서 분산형 애플리케이션을 실행하는 명령줄 유틸리티입니다. 포플러 분산형 컨피규레이션 라이브러리(PopDist)는 개발자가 분산 실행을 위해 애플리케이션을 준비하는 데 사용할 수 있는 API를 제공합니다.
IPU-POD128 및 IPU-POD256과 같은 대규모 시스템을 사용하는 경우, PopRun은 상호 연결된 다른 IPU-POD에 위치한 호스트 서버에서 자동으로 여러 인스턴스를 실행합니다. 애플리케이션 유형에 따라 여러 인스턴스를 실행하면 성능이 향상될 수 있으며, 개발자는 PopRun을 사용해 호스트 서버에서 여러 인스턴스를 실행할 수 있습니다. 또한 NUMA 지원으로 최적의 NUMA 노드 배치도 가능합니다.
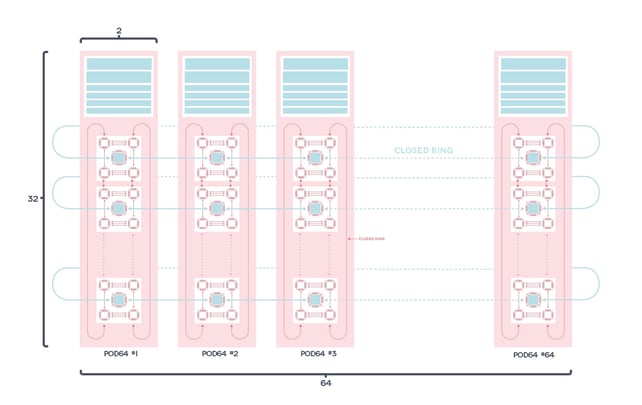
IPU-POD128과 IPU-POD256의 프로덕션 가용성은 여러 데이터센터에 걸쳐 IPU 시스템 확장이 크게 진일보했음을 나타냅니다.
그래프코어의 IPU-Fabric은 멀티랙 시스템에 AI 연산을 제공하는데 상당한 역할을 하고 있는데요, IPU-Fabric은 IPU 간 원활한 고성능 통신을 제공하도록 설계된 AI 최적화 인프라 기술입니다.
랙 내 IPU 통신에는 기존에 IPU-POD16과 IPU-POD64와 같은 시스템에서 이미 제공되고 있는 64GB/s IPU 링크가 사용됩니다.
특히, IPU-POD128과 IPU-POD256은 그래프코어의 게이트웨이 링크가 사용된 최초의 제품인데요, 게이트웨이 링크는 일반 100GB 이더넷을 통한 터널링을 사용하여 IPU 링크를 확장하는 랙 간 수평 연결 기술입니다.
통신은 각 IPU-M2000에 내장된 IPU 게이트웨이에 의해 관리됩니다. 연결성은 IPU-M2000의 듀얼 QSFP/OSFP IPU-GW 커넥터(표준 100GB 스위치 지원)를 통해 제공됩니다.
공유:


