
Oct 21, 2021
Oct 21, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamIPU-POD128 and IPU-POD256 are the latest and largest products in the ongoing story of scaling Graphcore AI compute systems showing the strengths and benefits of an architecture that has been designed from the ground up for machine intelligence scale-out.
With a powerful 32 petaFLOPS of AI compute for IPU-POD128 and 64 petaFLOPS for IPU-POD256, Graphcore’s reach into AI supercomputer territory is further extended.
These systems are ideal for cloud hyperscalers, national scientific computing labs and enterprise companies with large AI teams in markets like financial services or pharmaceutical. The new IPU-PODs enable, for example, faster training of large Transformer-based language models across an entire system, running large-scale commercial AI inference applications in production, giving more developers IPU access by dividing up the system into smaller, flexible vPODs or enabling scientific breakthroughs by enabling exploration of new and emerging models like GPT and GNNs across complete systems.
Both IPU-POD128 and IPU-POD256 are shipping to customers today from Atos and other systems integrator partners and are available to buy in the cloud. Graphcore provides extensive training and support to help customers accelerate time to value from IPU-based AI deployments.
Results for extensively used language and vision models show impressive training performance and highly efficient scaling, with future software refinements expected to further boost performance.
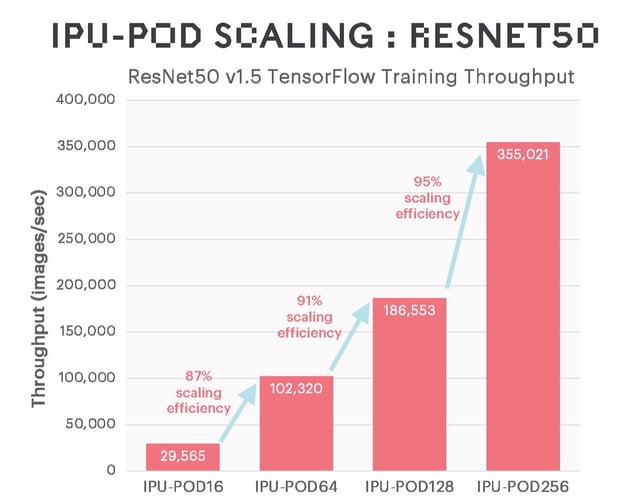
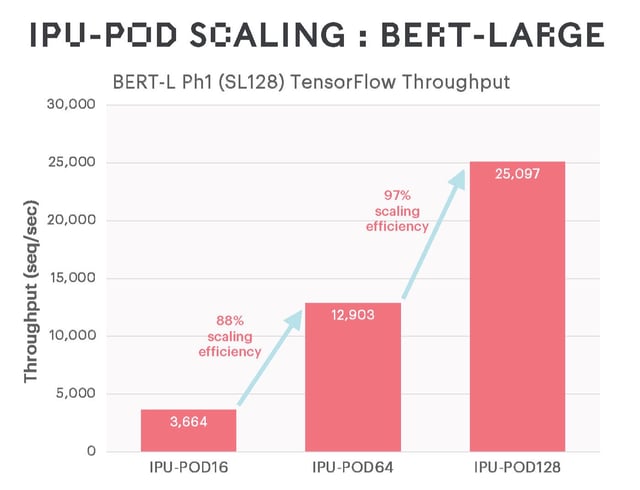
IPUs (intelligence Processing Units), as well as providing excellent performance for traditional large MatMul models like BERT and ResNet-50 due to their integrated on-processor memory, also support more general types of computation that make sparse multiplication and more fine-grained computations more efficient. The EfficientNet family of models benefits heavily from this, as well as graph neural networks (GNNs) and also various machine learning models that are not neural networks.
Atos is among the many Graphcore partners that will deploy IPU-POD256 and IPU-POD128 systems with their customers around the world:
“We are enthusiastic to add IPU-POD128 and IPU-POD256 systems from Graphcore into our Atos ThinkAI portfolio to accelerate our customers’ capabilities to explore and deploy larger and more innovative AI models across many sectors, including academic research, finance, healthcare, telecoms and consumer internet,” said Agnès Boudot, Senior Vice President, Head of HPC & Quantum at Atos.
One of the first customers to deploy IPU-POD128 is Korean technology giant Korea Telecom (KT), which is already benefitting from the additional compute capability:
"KT is the first company in Korea to provide a 'Hyperscale AI Service' utilizing the Graphcore IPUs in a dedicated high-density AI zone within our IDC. Numerous companies and research institutes are currently either using the above service for research and PoCs or testing on the IPU.
In order to continuously support the increasing super-scale AI HPC environment market demand, we are partnering with Graphcore to upgrade our IPU-POD64s to an IPU-POD128 to increase the “Hyperscale AI Services” offering to our customers.
Through this upgrade we expect our AI computation scale to increase to 32 PetaFLOPS of AI Compute, allowing for more diverse customers to be able to use KT’s cutting-edge AI computing for training and inference on large-scale AI models,” said Mihee Lee, Senior Vice President, Cloud/DX Business Unit at KT.
The launch of IPU-POD128 and IPU-POD256 underscores Graphcore’s commitment to serving customers at every stage in their AI journey.
IPU-POD16 continues to be the ideal platform to EXPLORE, IPU-POD64 is aimed at those who want to BUILD their AI compute capacity, and now IPU-POD128 and IPU-POD256 deliver for customers who need to GROW further, faster.
As with other IPU-POD systems, the disaggregation of AI compute and servers means that IPU-POD128 and IPU-POD256 can be optimized to deliver maximum performance for different AI workloads, delivering the best possible total cost of ownership (TCO). For example, an NLP-focused system could use as few as two servers for IPU-POD128, while a more data-intensive task such as computer vision tasks may benefit from an eight-server setup.
Additionally, system storage can be optimized around particular AI workloads, using technology from Graphcore’s recently announced storage partners.
Scaling Graphcore compute to IPU-POD128 and IPU-POD256 is made possible by a number of enabling technologies – both hardware and software:
As with all Graphcore hardware, the IPU-POD128 and IPU-POD256 are co-designed with our Poplar software stack.
The features that enable our scale-out systems have been introduced across several Poplar software releases, including our latest, SDK 2.3. The following innovative features are important to enabling straightforward scale out for all IPU-POD systems, while we really start seeing the benefits with systems of the scale of IPU-POD128 and IPU-POD256.
Graphcore Communication Library (GCL) is a software library for managing communication and synchronization between IPUs and is designed to enable high-performance scale-out for IPU systems. At compile time it is possible to specify the number of IPUs the program should run on, which may be distributed across more than one IPU-POD. The program will run automatically and transparently across the IPU-PODs, delivering increased performance and throughput at no additional cost or complexity for the developer.
PopRun and PopDist allow developers to run their applications across multiple IPU-POD systems.
PopRun is a command line utility for launching distributed applications on IPU-POD systems and the Poplar Distributed Configuration Library (PopDist) provides a set of APIs which developers can use to easily prepare their application for distributed execution.
When using large systems such as IPU-POD128 and IPU-POD256, PopRun will automatically launch multiple instances on host servers located in another interconnected IPU-POD. Depending on the type of application, launching multiple instances can increase performance. With PopRun, developers are able to launch multiple instances on the host server with support for NUMA enabling optimal NUMA node placement.
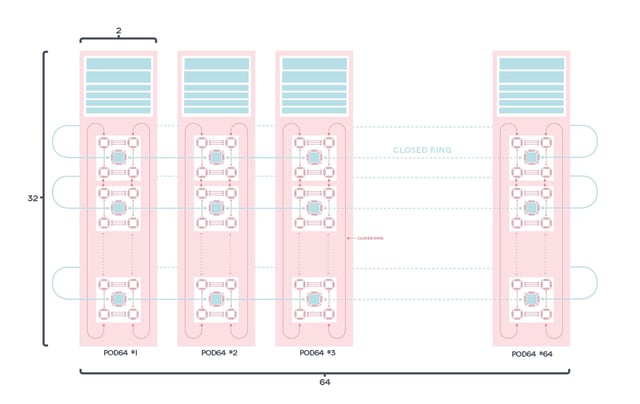
The production availability of IPU-POD128 and IPU-POD256 represent the next major advance in scaling IPU systems across the datacenter.
Delivering AI compute in a multi-rack system is made possible, in part, by Graphcore’s IPU-Fabric, a range of AI-optimized infrastructure technologies, designed to deliver seamless, high-performance communication between IPUs.
For intra-rack IPU communication, we make use of the 64GB/s IPU-Links, already seen in systems such as the IPU-POD16 and IPU-POD64.
IPU-POD128 and IPU-POD256 are the first products from Graphcore to utilize our Gateway Links, the horizontal, rack-to-rack connection that extends IPU-Links using tunnelling over regular 100Gb ethernet.
Communication is managed by the IPU-Gateway onboard each IPU-M2000. Connectivity is via the IPU-M2000's dual QSFP/OSFP IPU-GW connectors, which support standard 100Gb switches.
IPU-POD16, IPU-POD64, IPU-POD128 and IPU-POD256 are shipping to customers today from Atos and other systems integrator partners around the world and are available to buy in the cloud from Cirrascale.
Share:


