
Oct 21, 2021
Oct 21, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamOur latest release Poplar SDK 2.3 delivers significant performance optimisations, greater ease of use and practical support for production workloads.
Thanks to the many new features and optimisations in SDK 2.3, developers will benefit from faster training and inference times, improved model efficiency and better performance for large models and datacenter-scale applications.
For further information on these new features, see our SDK 2.3.0 Release Notes.
New optimisations and performance improvements have been added to SDK 2.3 to support larger workloads and production scale-out.
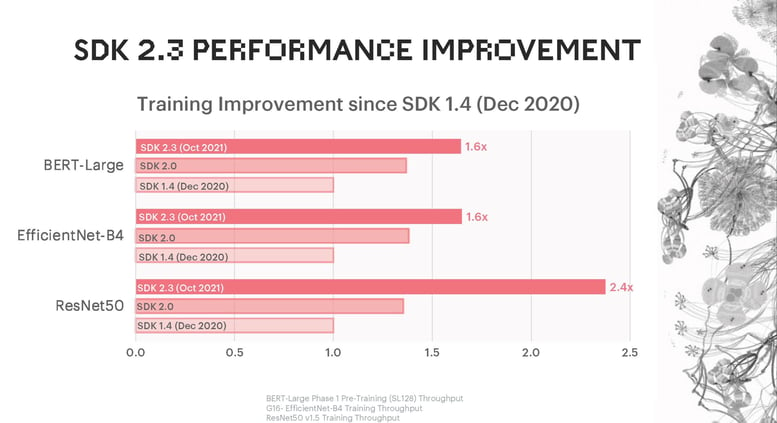
Every new Poplar release brings substantial performance improvements. Developers using SDK 2.3 will benefit from training speed-ups of 1.6 x for BERT-Large, 1.6 x for convolutional neural network EfficientNet-B4 and 2.4 x for ResNet-50.
New optimisations for inference applications ensure optimised and consistent latency, maximising inference performance.
Replicated Tensor Sharding (RTS) for optimiser state is now fully supported in TensorFlow. This can increase the throughput for replicated models where optimiser state is being offloaded to external Streaming Memory. The LAMB optimiser, which enables developers to use larger batch sizes, is now compatible with RTS thanks to improvements made in this release. Read our BERT-Large training blog to learn more or check out our BERT TensorFlow implementation walkthrough on GitHub.
For large-scale production workloads, RTS can now be implemented over multiple IPU-POD systems, from IPU-POD128 upwards. Find out more about IPU-POD128 and IPU-POD256 and their capabilities for innovation at datacenter scale in our IPU-POD128 and IPU-POD256 blog.
It’s easier than ever to accelerate your models and program the IPU with this latest version of our Poplar software stack.
SDK 2.3 delivers further compilation time improvements with speed-ups of 10% or more for BERT, ResNet-50 and EfficientNet, including framework and graph construction times. Host memory utilisation has also been reduced by as much as 6.8% for NLP model BERT with additional enhancements to follow in December under SDK 2.4.
Preview support has been added for Debian 10.7, an OS used in a wide range of scenarios, from the stock exchange to super-colliders.
With improved error and log handling, developers will now be able to troubleshoot issues more easily.
In the latest versions of our PopVision Graph Analyser and System Analyser tools, we’ve added new features to improve performance and make our tools even easier to use. As part of the update, we have also included software to notify users if a new release is available with the option to start the update immediately or postpone it. Major new PopVision features in this release are detailed below.
As models get larger and the number of IPUs supporting workloads increases so does the size of the profiling information. We’ve released a major update to our execution trace report in the PopVision Graph Analyser which now supports profiles that are 10 times larger, boosting performance and ease of use.
To help developers understand exchanges between tiles and between the IPU and the host in greater depth, the option to view which variables are involved in exchanges has been added to the Graph Analyser.
In the PopVision System Analyser, developers can now select threads or graphs and pin them to the top of the report, making it easier to compare them.
We’ve updated our extensive Model Garden to include broader applications coverage for innovators, including new models such as YOLOv4 & MobileNetV3 for Object Detection use cases.
Check out our developer portal to access all the latest documentation, tutorials, code examples, webinars, video, research papers and further resources for IPU programming.
Share:

