
Jul 23, 2020
Jul 23, 2020
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamGraphcore has achieved unmatched text-to-speech training performance on the Intelligence Processing Unit (IPU) with Baidu’s Deep Voice 3. The speed-ups are a result of both the processor’s unique architectural features and optimizations in our Poplar software stack, which has been co-designed with the processor.
Converting written text into speech is arguably one of the most challenging areas of speech technology research. Early progress in text-to-speech (TTS) modelling has happened mostly through small iterations of complex multi-stage, hand-crafted pipelines. One family of early approaches referred to as concatenative systems originated in the 1970s and focused on the optimal concatenation of basic speech units. A competing approach that fell under the umbrella of statistical parametric speech synthesis instead used models like Hidden Markov Models and Recurrent Neural Networks to output low-dimensional audio features which fed into signal processing algorithms known as vocoders.
With the arrival of deep learning, it became possible to generate speech with minimal handcrafting by training models on large labeled datasets. DeepMind’s Wavenet model was a pioneering contribution in the area of speech generation, as it significantly reduced the gap between previous state-of-the-art TTS systems and human-level performance. Wavenet directly generated raw audio samples using stacks of causal convolutional layers with dilations.
Although Wavenet was successful in generating natural sounding speech in different speaker voices, the high-frequency autoregressive nature of the model made it challenging to use for low-latency or high throughput inference applications. After Wavenet, various model families followed from different research groups. Among the most prominent were Tacotron from Google, Deep Voice from Baidu and FastSpeech from Microsoft, enabling high-quality, end-to-end speech synthesis.
Demonstrating Text to Speech Generation on the IPU with Deep Voice 3
When the Baidu Research Group released a family of TTS models under the name Deep Voice in 2017, the first two iterations - Deep Voice 1 and 2 - followed the traditional structure of TTS pipelines. Both had separate models for various stages like grapheme-to-phoneme conversion, segmentation, audio duration and frequency prediction and final waveform synthesis.
The Deep Voice 3 model was a major step forward in that the whole TTS pipeline was captured by a single compact model. The Deep Voice 3 model is fully convolutional and uses attention blocks to decode the input text sequence to the output audio sequence representation (which in this case are mel-scale spectrograms).
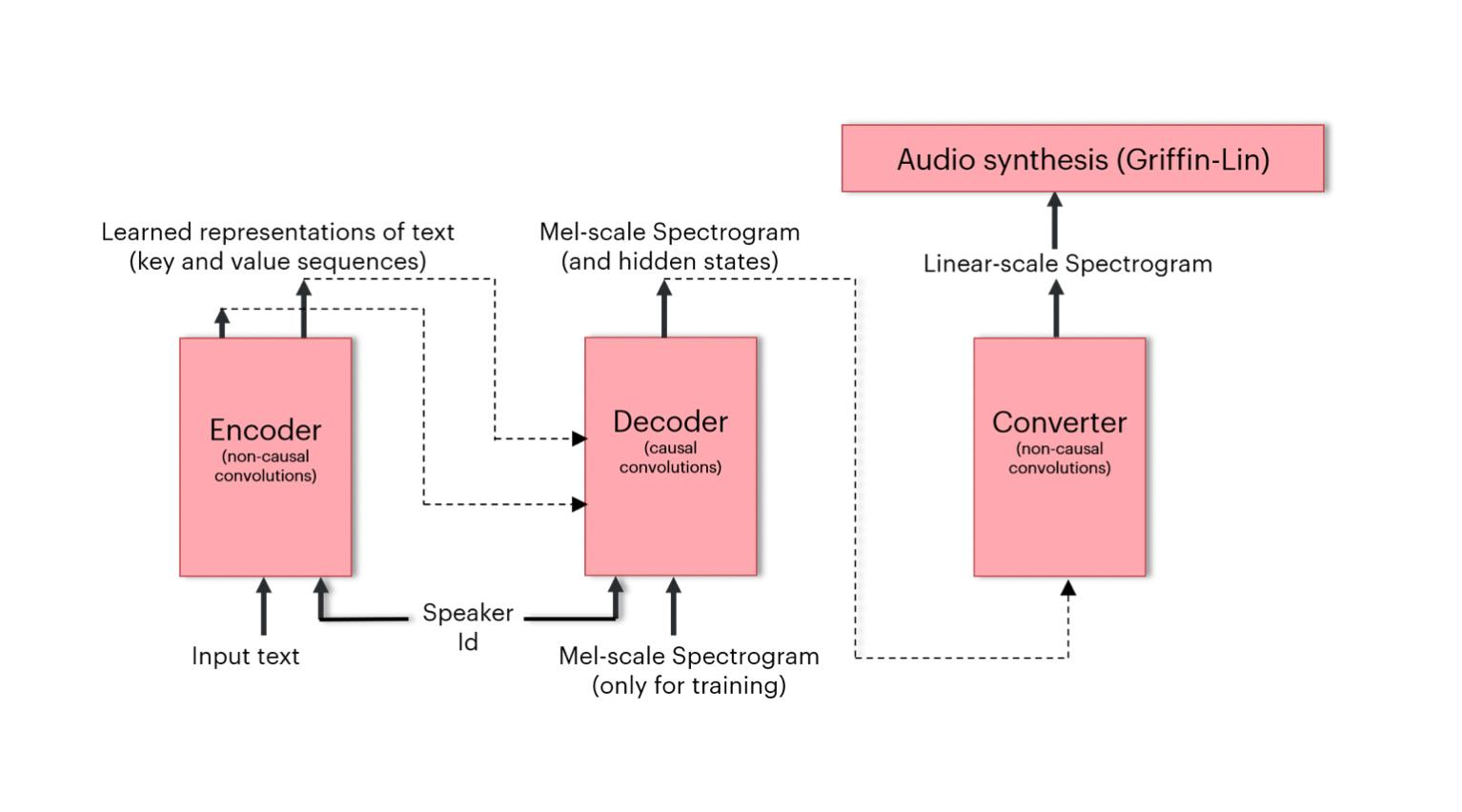
Figure 1: High-level architecture of the Deep Voice 3 model
What are Mel-Scale Spectrograms?
Before we look at the Deep Voice 3 architecture and training performance, here is a brief explainer on spectrograms for those who need it.
Spectrograms are a representation of the frequency content of a signal over short overlapping windows obtained via Short-Time Fourier Transforms. Many speech technology applications require low-dimensional representations of the audio signal and in such cases mel-scale spectrograms are used.
Mel-scale spectrograms are based on the idea that humans perceive frequencies on a logarithmic scale. To give an example, it is much more difficult for a human being to notice the difference between frequencies of 10,000Hz and 10,500Hz, than to distinguish between frequencies of 500Hz and 1000Hz. Mel-scale spectrograms are obtained by simply binning together frequencies that are closer together on the logarithmic scale and averaging the amplitudes for frequencies in the same bins.
Despite being lower dimensional, mel-scale spectrograms are often sufficient for tasks like speech or voice recognition. Figure 4 shows an example visualization of a mel-scale spectrogram.
Deep Voice 3 Model Architecture
Now, let’s take a look at the Deep Voice 3 model architecture. Figure 1 shows a high-level diagram of the Deep Voice 3 model and Figure 2 shows sketches for the main building blocks of the model (a convolutional block and attention block). The Deep Voice 3 model has three major components – the encoder, decoder and converter networks. The inputs to the encoder network are character sequences and speaker identities which are converted to an internal learned representation. The outputs of the encoder network are key and value sequences which feed into the attention blocks of the decoder network. The decoder uses causal convolutional blocks (to model the autoregressive nature of the decoder) and attention blocks to decode the learned text representation from the encoder into mel-scale spectrograms.
During training, the decoder receives the ground-truth mel-scale spectrograms and speaker identities and learns to reconstruct the mel-scale spectrogram. The causal convolutional blocks force the decoder network to learn to predict the i-th frame of the spectrogram from the preceding frames of the spectrogram. This means that during inference, the decoder network can construct the whole spectrogram frame-by-frame solely from the text encoding and speaker identity.
The converter network processes the hidden states generated from the decoder and produces the complete linear-scale spectrograms. It is possible to design the converter to generate other vocoder parameters too, but in this work, we train the converter to generate linear-scale spectrograms. The linear-scale spectrograms generated by the converter are then fed into a classical signal-processing algorithm known as the Griffin-Lin algorithm to synthesize the final audio. The loss function used for training the whole network is a sum of the L1 losses for the mel-scale and linear-scale spectrogram reconstructions. The Deep Voice 3 model has been implemented using Poplar Advanced Run Time (PopARTTM) to run on Graphcore IPU processors and is available at our public examples repository.
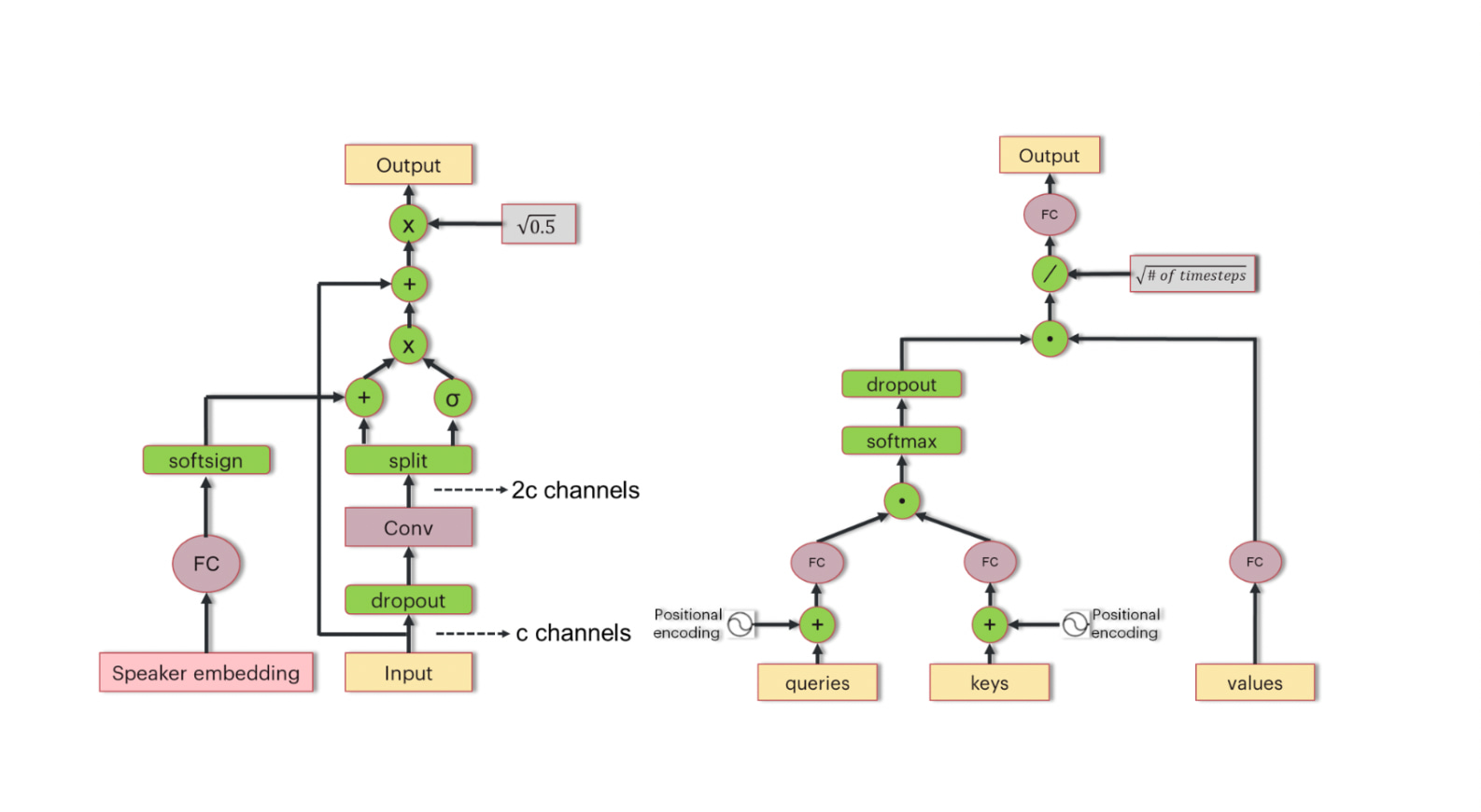
Figure 2: Main building blocks of the Deep Voice 3 model. The block on the left is a one-dimensional convolutional block with gating and a residual connection. The block on the right is a dot-product based attention block.
Comparison Estimates with GPUs
We benchmarked the Mark 1 (MK1) and Mark 2 (MK2) IPUs against a leading 12nm GPU for Deep Voice 3 training using the VCTK Corpus which is a multi-speaker dataset and contains 44 hours’ worth of recordings. Figure 3 compares the throughput numbers during training for the IPUs and the GPU alternatives. With data-parallel training on a C2 card with 2 MK1 IPUs (batch-size of 4), a throughput of 1260 queries per second (QPS) is achieved – a 6.8x speedup over the GPU (which uses the same power as the C2 card). To put this in other terms, to complete one training epoch over the VCTK Corpus, it takes about 35 seconds with a MK1 C2 card, compared with about 4 minutes on the GPU.
With a single MK2 IPU in an IPU-M2000 and a batch-size of 16, we obtain a throughput of 2744 QPS - a 14.8x speedup over the GPU.
Even with the announcement of the latest GPU we expect the IPU MK2 advantage to be ~10x based on published GPU comparison results.
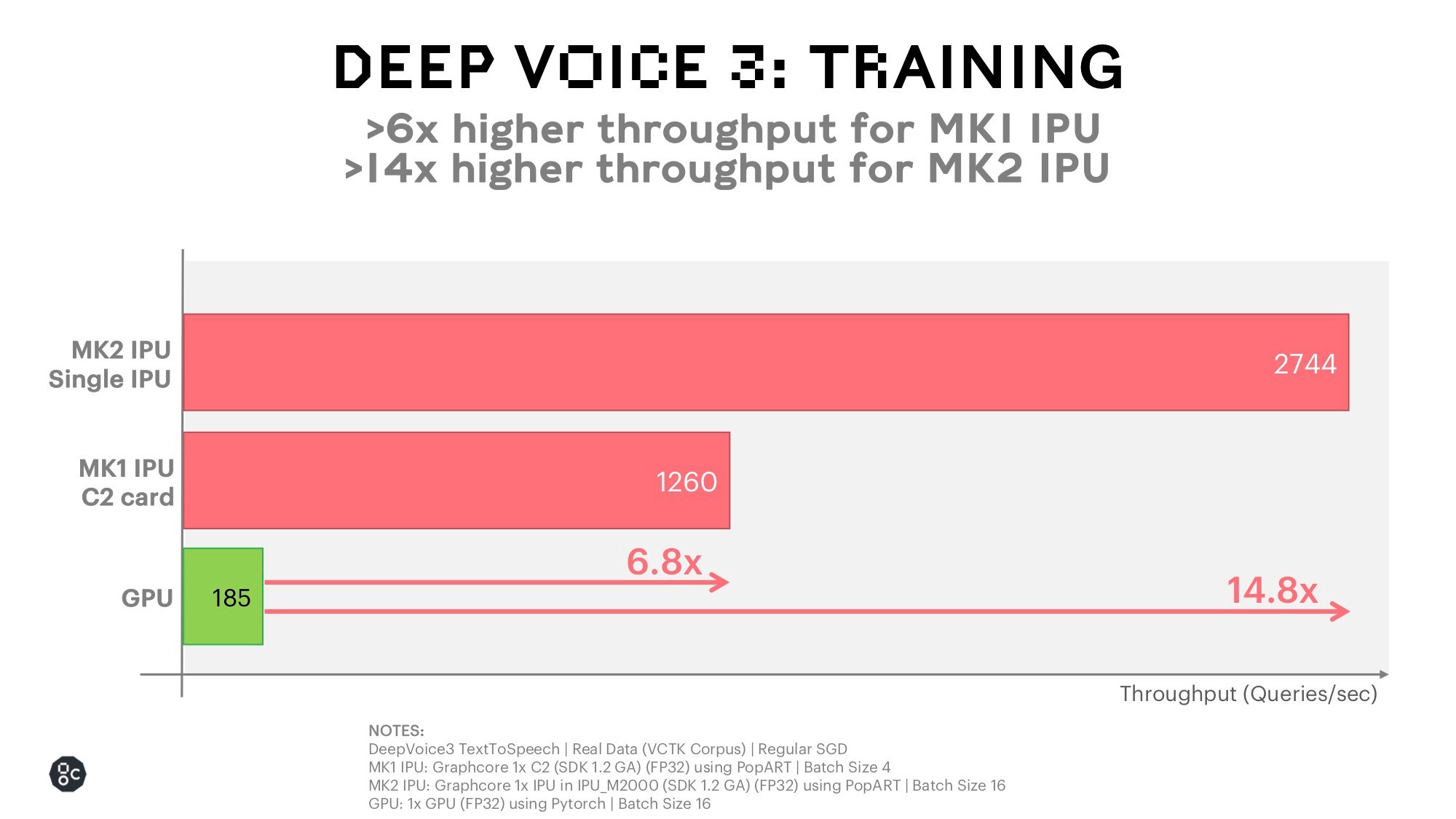
Figure 3: Chart comparing training throughput numbers for IPUs and leading 12nm GPU alternative
How does the IPU accelerate Deep Voice 3 Training?
The IPU is particularly efficient at processing convolutional models because of multiple factors, including its unique memory organization and massive parallelism (as detailed in our recent computer vision blog). These architectural advantages result in impressive speed-ups when training a convolutional model such as Deep Voice 3.
Our PoplarTM software stack is also designed specifically for the IPU. Poplar enables a large degree of parallelism for the one-dimensional convolutions and matrix multiplications which dominate the Deep Voice 3 model.
The IPU’s novel memory organization is equally a key factor. The MK1 IPU contains 1216 cores which perform compute on the processor’s own distributed 300MB of on-chip memory which limits the need to access external memory for data. This is a huge advantage for the IPU in comparison with GPUs which are limited by their bandwidth to external memory.
Sample Synthesized Audio
Below are some audio samples generated using our implementation of Deep Voice 3 on the IPU. Interestingly, even though some of the words used to generate the speech samples were not in the original training dataset, the model is still able to synthesize the corresponding speech effectively.
"He likes the taste of Worcestershire sauce."
Female Voice
"She demonstrated great leadership on the field."
Male Voice
Figure 4 shows a generated mel-scale spectrogram for the text “She demonstrated great leadership on the field”. Next to this is a visualization of the audio signal generated via the Griffin-Lin algorithm, acting on the output of the converter network.
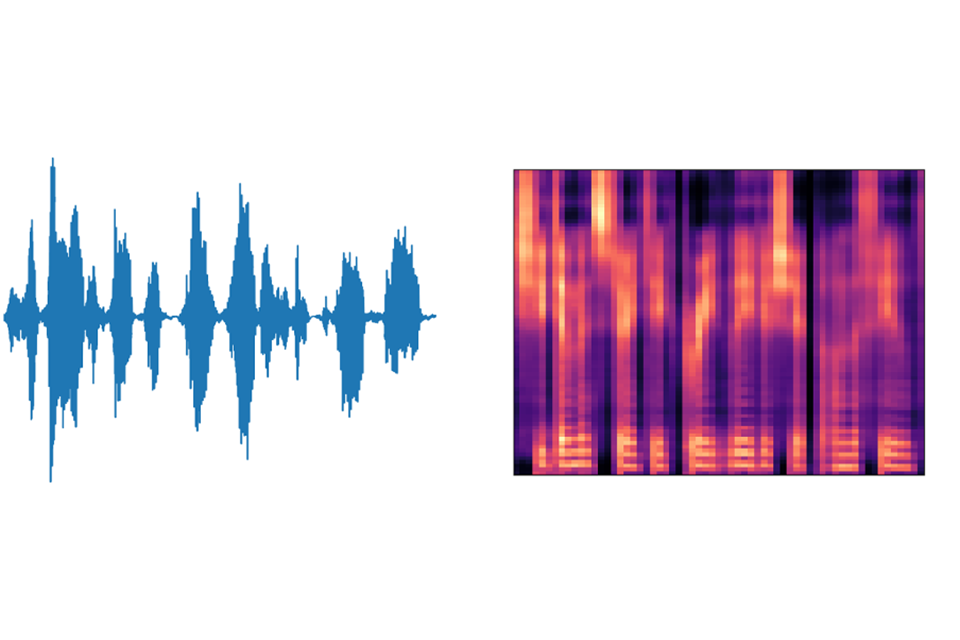
Figure 4: The figure on the right is a mel-scale spectrogram generated by a trained decoder network of the Deep Voice 3 model. The figure on the left is the audio synthesized by the Griffin-Lin algorithm using the output from the trained converter network.
Real-World Text-to-Speech Applications with the IPU
What are the potential benefits of using an IPU for TTS applications? For a use case such as audiobooks which are generated in the author’s voice, fast training of speech synthesis models can lead to savings in time, money and energy spent on computational resources. In educational and consumer internet applications, as well as assistive technologies for people with disabilities, there is significant potential for using voice cloning models which are related to TTS models. Accelerating these applications with the IPU provides similar advantages to those already mentioned, while improving user experience and quality of life.
In real-time applications where low latency is important, efficient inference by TTS models is critical and this is another area where IPUs can bring a huge benefit, since the IPU is effective for both training and inference.
The IPU’s capacity to accelerate TTS models such as Deep Voice 3 opens up the opportunity to create entirely new classes of TTS models which fully utilize its unique processor architecture. We look forward to seeing what these innovations entail in the near future as the field develops.
Share:


