.png?width=1440&name=API%20depiction%20header%20(1).png "API header image")
Oct 04, 2023
Oct 04, 2023
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamThe number of startups building new products and services based on Artificial Intelligence is growing at a dizzying pace. At the same time, long-established businesses are also moving quickly to exploit the opportunities and advantages presented by AI.
As with the compute revolution of the past 20 years, powerful, easy-to-use APIs are proving a vital tool in connecting compute infrastructure to user-facing services.
In this blog, we'll demonstrate how to get started with Graphcore's IPUs, using Hugging Face's Optimum to load and use machine learning models. Then, we'll set up a FastAPI server to serve these models and use Uvicorn to launch the server. Finally, we'll discuss advanced techniques like batching and packing, load balancing, and using optimized models.
These principles apply wherever your IPU compute is hosted. A great way to get started and try out these techniques is via Gcore's cloud IPU service.
If you haven't already installed Optimum and Hugging Face's Transformers, you can install them using pip:
Let's start by loading a sentiment analysis model onto the IPU. To do this, we will use the IPUConfig class to specify our IPU settings.
Here, we only specify that we want to use only one IPU. Then, we use the pipeline function to load our model.
Now, to use this model, we just have to call it with our text input:
![]()
After successfully loading your machine learning model onto Graphcore's IPU, the next step is to make this model accessible through an API.
FastAPI paired with Uvicorn makes this incredibly easy. Amazingly, you can get your server up and running in a few lines of code.
FastAPI() initializes the FastAPI framework.@app.get("/predict") sets up an HTTP GET method for sentiment analysis. It uses the IPU-loaded model to perform inference on the given text.This launches the FastAPI app using Uvicorn, making it accessible at http://localhost:8000/predict?text=YourTextHere.
.png?width=1770&height=484&name=cropped2%20(1).png)
Now that you have a fully functional FastAPI server running a machine learning model on a Graphcore IPU, it's crucial to understand how well this server can handle multiple requests. Stress testing can provide insights into the server's performance, reliability, and capacity. One popular tool for stress testing HTTP services is Locust.
Locust is an open-source load testing tool where you define user behaviour in Python code and then simulate millions of users to stress test your application. It's a flexible and powerful tool that can help you identify bottlenecks and limitations in your system.
Create a locustfile.py with the following Python code to define the user behaviour for the stress test:
Here, @task decorates the method that will simulate the API call. We specify that the simulated users will wait between 1 to 2 seconds (wait_time = between(1, 2)) between tasks.
Once the test is running, Locust will provide real-time statistics on your server's performance, including requests per second, average response time, and more. This data will be invaluable in understanding how well your FastAPI server performs when hosting a model on a Graphcore IPU.
In the initial test with a single IPU, the server handles an impressive 500 requests per second when tested with 200 concurrent users and a response time of 20ms on average.
.png?width=2620&height=568&name=Locust%201%20(1).png)
.png?width=2620&height=742&name=image-20230922-163635%20(1).png)
Graphcore's technology is designed for scalability. By employing the -workers option in Uvicorn, we can effortlessly scale our application to utilize multiple IPUs. For instance, with 16 IPUs (-workers 16), the performance scales almost linearly.
.png?width=2620&height=648&name=Locust%202%20(1).png) With 16 IPUs in play, the server’s capacity to handle requests surges dramatically. The updated test results depict the server processing approximately 7400 requests per second, with a response time of around 27ms.
With 16 IPUs in play, the server’s capacity to handle requests surges dramatically. The updated test results depict the server processing approximately 7400 requests per second, with a response time of around 27ms.
The versatility of Graphcore’s IPU technology extends beyond linear scalability. With a POD16 setup, users not only benefit from enhanced performance but also have the opportunity to deploy multiple models concurrently, each utilizing its own IPU. This feature maximizes the flexibility and capability of the IPUs, providing a significant advantage for diverse applications and services.
The POD16's architecture ensures that each IPU operates independently, thus eliminating the performance bottlenecks associated with shared resources. Each model runs on its dedicated IPU, ensuring optimal performance and efficiency.
In the preceding sections, we've laid out the foundational steps to deploy a model on Graphcore's IPUs using FastAPI. However, the journey to optimal performance doesn’t end here. There are advanced strategies like batching, sequence packing, and load balancing that can be employed to further amplify the performance and efficiency of the models deployed on IPUs.
Our initial example was straightforward, without the implementation of batching or sequence packing. In real-world scenarios, especially with models like BERT, efficiently packing sequences and batching can lead to significant performance improvements.
Graphcore provides detailed insights and methodologies to effectively implement sequence packing for BERT models. By adopting these strategies, inference performance can be amplified up to nine times. Detailed information and implementation guidelines can be found in Graphcore's insightful article: Accelerate NLP Tasks for Transformers with Packing.
While FastAPI is a powerful and efficient tool for deploying machine learning models, it's essential to recognize its limitations, especially when paired with high-performance hardware like Graphcore's IPUs. The IPU's performance potential can be bottlenecked if not paired with optimized implementation and deployment strategies.
In our example, the performance of the IPU is not fully realized due to the limitations inherent in the FastAPI framework. To unleash the full potential of IPUs, integrating advanced load balancing techniques and optimizing the request handling mechanism is crucial, with solutions like NGINX. You can also check out our Simple Server Framework example: GitHub - graphcore/simple-server-framework: Simple Server Framework provides a wrapper to add serving to an application using a minimal declarative config and utilities to package and deploy the application.
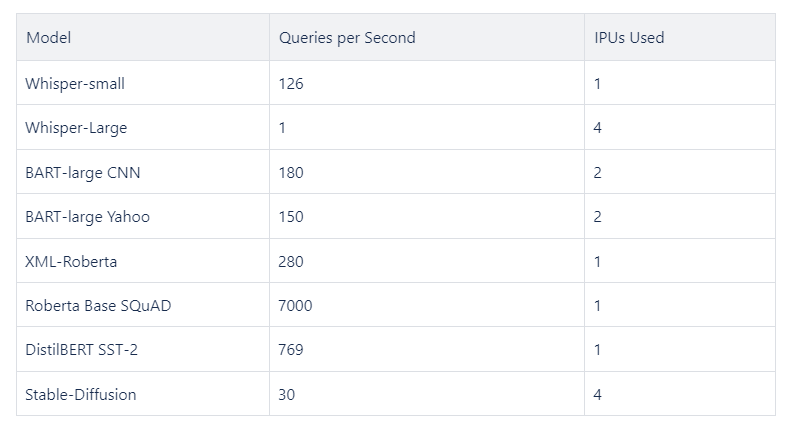
When utilizing Graphcore's POD16, it's essential to know how to optimally distribute different machine learning models across the available IPUs to achieve the highest performance. The POD16 infrastructure allows for the concurrent deployment of multiple models, each potentially requiring a different number of IPUs to maximize efficiency and performance.
Here, we present an illustrative example of how diverse models can be loaded onto a POD16, with their respective performances, showcasing the POD16's capability to handle multiple models with varied requirements effectively:
For those eager to experience first-hand the performance and efficiency gains achievable with IPUs, platforms like Paperspace and G-Core offer an accessible entry point.
For detailed steps on how to embark on this exploration, the official Graphcore documentation provides a comprehensive guide to getting started. The journey from curiosity to tangible implementation is well-supported, ensuring that professionals at every level can effectively harness the power of IPUs in their AI/ML projects.
Get started today by following this guide: Getting Started with Graphcore's IPU.
Happy exploring, and here’s to the next leap forward in your AI and machine learning journey!
Share: