.png?width=1440&name=Header%20new%20(1).png "Commercial AI blog header")
May 26, 2023
May 26, 2023
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamWhen GPT-3 and subsequently ChatGPT and GPT-4 landed, it felt like AI had reached an inflection point - both in terms of popular understanding of its abilities, and the potential to put it to use commercially.
The moment has been likened to the arrival of Sputnik 1 - the first satellite to orbit the earth, sixty-six years ago. Sputnik kick-started the space race, including the creation of NASA, and the countless advances that would flow from it.
These sort of technology-enabled seismic shifts are few and far between, but artificial intelligence seems to be having its Sputnik moment right now.

However, the big GPTs didn’t come out of nowhere. You can trace their lineage, at least to the invention of Transformer models in 2017, while the aspiration to build conversant computer systems goes even further back, certainly as far as Alan Turing.
So what has really changed in 2023?
There’s something more than just AI conversing more convincingly than it has before, or generative visual models being able to imagine novel works of art. The commercial applicability of AI is also, finally, being realised.
Until now, we were mainly in a ‘capability phase’ where the AI industry consisted primarily of researchers working to make the technology do what they thought it might be able to do.
Compute was incredibly important, but things like the cost or number of processors required weren’t the primary concern. Capability was, and remains, about pushing the boundaries, whatever it takes.
Today the research goes on. At the same time, we are in moving into the ‘deployment phase’ where that innovation is being put to work commercially.
.png?width=1280&height=720&name=Capability%20(1).png)
We are seeing thousands of AI-based startups created, while long-established businesses are asking how they too can get the AI advantage.
We are also witnessing the emergence of AI-as-a-Service - delivering enterprise-ready Artificial Intelligence, just as we saw the SaaS revolution of the past twenty years.
So what does this deployment phase – the commercialisation of AI - look like, particularly in relation to generative AI?
What we’ve seen so far from OpenAI and the big GPT models is certainly one facet of it. Their achievements are truly impressive. But this by no means represents the entirety of the AI opportunity.
There are three characteristics of commercial AI, each heavily intertwined, that will be essential to the progress of this field.
Graphcore’s model garden contains a wide selection of popular open-source models, optimised for IPUs. Some of the more recent additions include GPT-J, Dolly, and Stable Diffusion. There are also various flavours of BERT, YOLO, ResNeXt and more.
Many of these are used in applications where it would be computationally wasteful to use something like a 175bn parameter language model. You don’t need that breadth of capability for tasks such as named entity recognition or text summarisation.
With fine-tuning, smaller models can be highly optimised for specific applications. Which brings us to the importance of open-source models.
Using an open-source language model such as GPT-J, there are no ongoing charges to access the model, fine-tuning will only cost the price of your compute, and any data fed into it remains under the user’s control.
Compare that to a proprietary model. Fine tuning with OpenAI involves shipping your – probably confidential – data off to the company, paying for the fine tuning process, and ultimately ‘renting’ your model back on a pay-as-you go basis.
Some organisations will be happy with that. But for those operating at any sort of scale – there's tremendous opportunity for savings; making use of an open source model, fine tuned to your specific needs.
It is an assertion supported by no less than Google. A purportedly leaked memo from the search giant, entitled ‘We have no moat and neither does OpenAI’ declares: “Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months”
This is objectively true – open source offerings are replicating the capabilities of ultra-large LLMs – with few costs or computational overheads.
Arguably it is the ultra-large models that now need to make the case for their role in commercial AI deployment. Where do they fit in?
Efficiency is central to what we do at Graphcore.
While task-specific models will play a vital role in the growth of commercial AI, the general trend in model size is upwards, especially at the leading edge – as foundation models continue to develop.
We’ve already gone from hundreds of billions of parameters into the trillion-parameter model range. There’s every reason to expect this to continue. Even distillations of these ultra large models will be proportionately larger than we see today.
Correspondingly, the computational demands of AI are also increasing dramatically.
.png?width=1134&height=500&name=COmpute%20growth%20(1).png) Informed estimates put the training costs for GPT-3 between $10m and $15m. We don’t know what training GPT-4 cost, but it will not have been less than this.
Informed estimates put the training costs for GPT-3 between $10m and $15m. We don’t know what training GPT-4 cost, but it will not have been less than this.
It would only take one order of magnitude increase for training costs to reach a hundred million dollars or more. That prospect is significant for a number of reasons:
Firstly, it means that the range of organisations capable of developing foundation models becomes very small. Maybe there are four or five big tech companies that can afford those sort of development costs as a matter of routine, and the onus is on those companies to recoup their investment somehow.
Secondly, very large, trained models tend to be computationally demanding on the inference side also.
The answer – up until now – has been to throw another datacentre aisle of GPUs at the problem, or maybe even another datacentre. But that is not sustainable – in any sense of the word.
If we want to build new economies, supercharged by AI, we need to keep the technology as affordable and widely accessible as possible.
And what happens to the number of AI startups when the basic compute costs are $10m per year? Is it easier or harder to get a business off the ground than if your costs are $1m?
For existing companies, adopting AI as part of their business, the rate of innovation is also bound up in the cost of compute.
This issue was raised by Elon Musk, addressing the Wall Street Journal's CEO Council in May 2023: "The thing that’s becoming tricky is you really need three things to compete. You need talent… you need a lot of compute, expensive compute, and you need access to data. The cost of compute has gotten astronomical, so it’s now minimum ante would be $250m of server hardware… minimum."
Whoever you are - the more your use of AI increases, the bigger the numbers get, and the more pressing this issue becomes.
It’s conceivable that the cost of compute could becoming a limiting factor on the commercialisation of AI – if not stopping it, certainly slowing it.
This is why we need more efficient compute platforms. This is why Graphcore was created.
The latest version of the Graphcore IPU has 1,472 processing cores – each capable of working completely independently.
We are world leaders in using wafer-on-wafer technology – with a power delivery wafer enabling higher performance with greater energy efficiency.
The IPU is a Multiple Instruction, Multiple Data or MIMD processor as opposed to GPUs which are Single Instruction Multiple Data or SIMD processors.
MIMD is especially useful for AI applications for a number of reasons. Among them, MIMD reflects the reality that the sort of data that we see used in AI compute is not densely packed and homogenous – in the way that graphics data, such as pixel information, typically is.
When you throw AI compute at a GPU, what it tends to do is run calculations on the meaningful data – but also on all the spaces in-between. It is expending energy multiplying zero-by-zero.
With the IPU you can perform much more fine-grained compute.
There are many other characteristics of the IPU that lend themselves to AI compute.
.png?width=834&height=539&name=IPU%20schematic%20cropped%20(1).png)
Diagram of Graphcore IPU showing processor tiles and in-processor SRAM memory
One important example is the use of in-processor memory. When we designed the IPU, we placed a lot of incredibly fast SRAM on the processor die, adjacent to those 1,472 processing cores. Almost a gigabyte, in fact. That allows us to run processes extremely quickly because AI is all about repeatedly moving data back and forth between memory and compute. Where the model takes up more space, we can distribute that across multiple IPUs. And we can supplement that in-processor memory with inexpensive off-chip DRAM.
Nvidia takes a very different approach with its GPUs – placing High Bandwidth Memory close to, but outside the processor die. HBM is very expensive, and many models today are limited not by compute speed but by memory availability and bandwidth.
The economics or 'chip-onomics' of building these systems is completely different – which is why Graphcore is able to offer a huge performance-per-dollar advantage.
The MLPerf competitive benchmarking exercise showcased impressive results for Graphcore systems compared to the DGX-A100.
These are even more impressive when you consider that this is a comparison between a significantly lower cost Graphcore product and GPU product. Factoring in the cost of the compute – the difference becomes even more pronounced.
Efficiency is also a very flexible concept. You can take efficiency and make use of it in whatever way suits you and your business:
You might buy more compute for the same amount of money if you’re looking to get results faster without spending more. Or you might buy the same amount of compute for much less money, if you’re looking to drive profitability in your business. Maybe energy consumption is your primary concern.
Either way - more efficient compute always works to your advantage.
Tellingly, as of mid-2023, the efficiency of GPUs for AI tasks at scale is beginning to be questioned by prominent users of the technology. Meta, in announcing the development of an inference chip, designed specifically to run its newsfeed ranking algorithm, stated: "We found that GPUs were not always optimal for running Meta’s specific recommendation workloads at the levels of efficiency required at our scale".
While the use case in this instance is highly specific and the processor in question a narrowly-specified ASIC, the logic of seeking more efficient ways of running AI at scale carries over to more general workloads. And it is worth bearing in mind that few companies seeking a GPU alternative can develop their own silicon.
The Graphcore IPU delivers more efficient AI compute in another way too. Our unique architecture allows users to unlock new, more efficient techniques and model types that might not otherwise be available to them because they are too computationally challenging for GPUs – but lend themselves to IPUs.
Sparsification of models will become a hugely important technique. Just as your brain doesn’t need to use every neuron to deal with specific tasks - such as recognising a face - there are some parts of AI models that are more relevant than others for particular applications.
One of Graphcore’s partners is Aleph Alpha, a German company that is developing some impressive large language and multi-modal models.
Aleph Alpha took their Luminous Base model - a 13 billion parameter language model used to power a chatbot – and sparsified it by 80%, reducing it to 2.6 billion parameters.
.jpg?width=749&height=460&name=Dense%20sparse%20(1).jpg)
Aleph Alpha achieved 80% sparsification of their Luminous model using Graphcore IPUs
As a result, Luminous Base Sparse needed 20% of the processing FLOPS of the original and 44% of the memory – crucially with no loss of accuracy. The sparsified model also used 38% less energy than the dense version.
One of the reasons that Aleph Alpha was able to do this was because of the IPU’s support for point sparse matrix multiplications.
Crucially, once sparsified, they we were able to fit the entire model onto the on-chip SRAM of an IPU-POD16 system – maximising performance.
We continue to work together on commercial applications of Aleph Alpha’s work, running on IPUs.
Pienso is another company achieving impressive results using Graphcore technology.
Pienso is an interactive deep learning platform that allows business users to train and deploy models on their own without writing a single line of code or relying on a deep learning team. Pienso believes that people who understand their data the best should be empowered to build, nurture and use their own models in way that derives a substantial ROI.
The company has been using IPUs for around a year now and is not only benefitting from the price performance advantage, but has been exploring a number of new AI techniques that are unlocked by the IPU’s unique architecture.
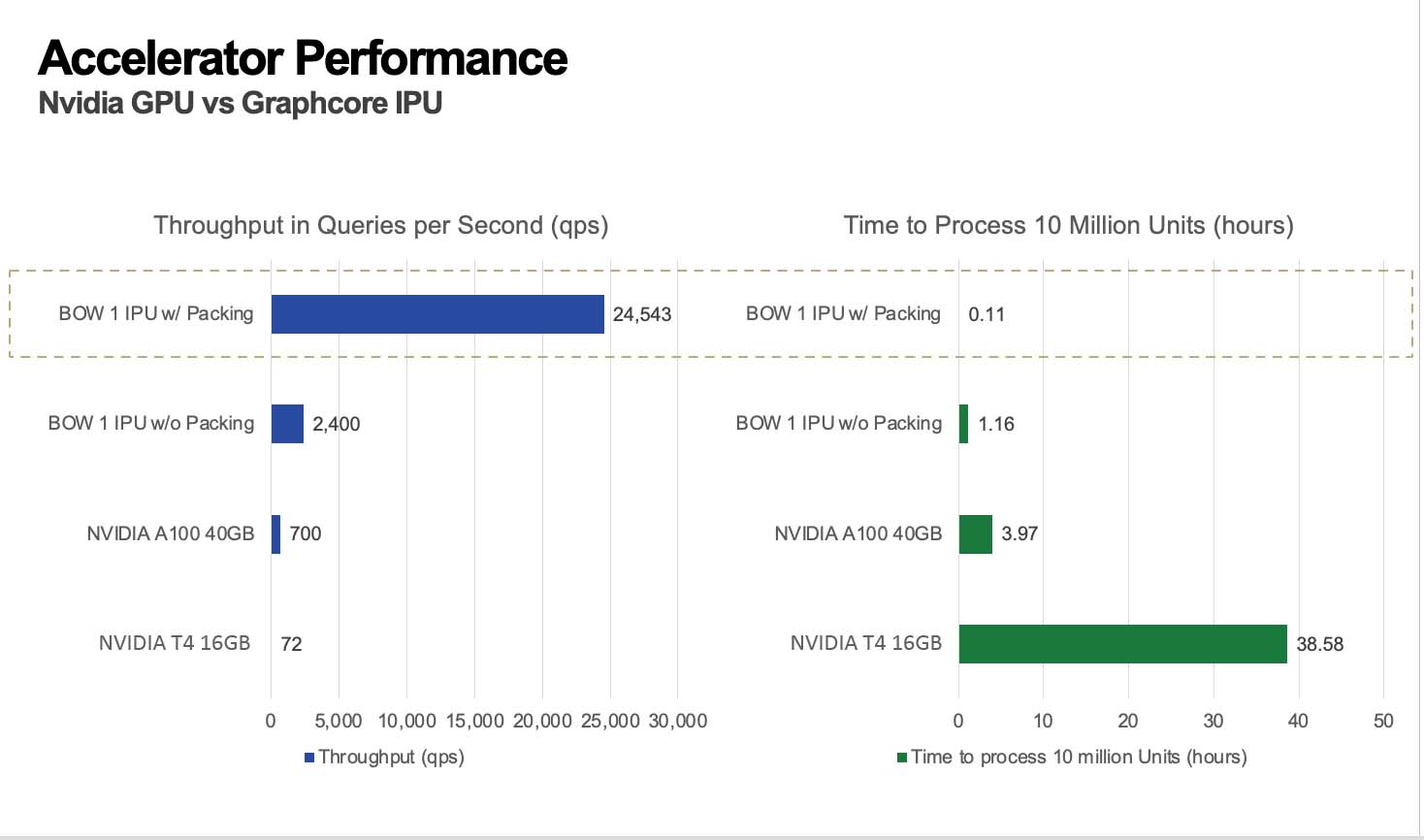
One such technique, developed by Graphcore’s own in-house research team, is called packing. Packing can be used to some benefit on GPUs, but its capability is fully realised on IPUs.
Even without packing, the Bow IPU was processing almost 4x the queries per second than the A100 GPU – a much more expensive piece of technology.
With Packing that went up to an amazing 35X.
Looking at that another way – the time it takes to process 10 million units falls from around 4 hours on the A100 to about 6 minutes on the IPU.
This makes a material difference to Pienso customers, many of whom are looking for real-time, or as close to real-time, insights as possible.
Pienso customer Sky is constantly monitoring for emerging trends which could turn into business opportunities, or problems that need to be addressed.
They are able to use customised language models to analyse the hundreds of thousands of customer interactions they have every day through text, email, telephone call transcriptions and more.
The faster that companies like Sky can identify emerging issues, the faster they can respond to emerging situations. Computational efficiency helps businesses strike while the iron is hot.
This is what efficiency looks like in the commercial world; not just saving time or money, but unlocking performance gains with new techniques, enabled by the IPU.
There’s huge overlap between accessibility and both diversity of models and efficiency – but there is value in digging into this concept more deeply.
Accessibility means making the possibilities offered by AI available to the widest possible user base.
We need to reduce both the technological barriers to entry, and ensure that the cost of AI compute does not become prohibitive to most commercial users.
That matter of cost is closely tied to efficiency. Reducing the cost of your AI compute by 50%, or even 10% could be the difference between profitability and loss for a commercial AI operation. It could mean that a service is viable or not.
More efficient compute equals greater participation. And let’s not think just about commercial offerings. Around the world Graphcore systems are part of large, publicly funded supercomputer facilities. Graphcore IPU systems are being used in four of the US Department of Energy’s national supercomputing labs, where they are made available to scientific researchers.
Do we want the public sector to have access to the same sort of AI computational resources that large tech hyperscalers have? Of course we do.
How we actually interact with AI systems is a large part of accessibility.
If you’re a business thinking about exploring the possibilities of AI, it can feel like a major undertaking to employ a team of AI experts and have them spend a year building bespoke systems. That’s not a model that is conducive to widespread, rapid adoption of AI.
So, in tandem with models getting more sophisticated and capable, we needed to make them easier to use – easier to tailor to your particular needs and easier to deploy.
A large part of the AI revolution is lowering the barrier to entry.
This mirrors what has happened over the past 20 year in the consumer and enterprise internet revolution.
How do you access the technology? The preference for many is in the cloud. Most businesses don’t want the CapEx and hassle of buying and running their own hardware – they want to pay by the hour for the compute they need, when they need it.
How do they want to interact with AI? The answer is, they want a choice. There are developers who like to work close to the metal, directly interacting with the hardware. But the broad utility of AI depends on us providing solutions for people who want less or even no interaction with code.
Paperspace offers cloud-based AI compute, running on Graphcore IPUs, where users can fine-tune and deploy popular AI models, including Stable Diffusion, BERT, Dolly, GPT-J and more, in the cloud. Their means of interacting with these is through web-based Jupyter notebooks.
If you want, you can walk through using these models in plain English, or you can dive into the underlying code – which is still relatively high-level – and make your own modifications.
.png?width=3572&height=1956&name=Cats%20(1).png)
Stable Diffusion running on Graphcore IPUs using Paperspace GRadient Notebooks
We'll shortly announce that we’re adding Bow-Pod64s in Paperspace – a 22 petaFLOPs system. That’s equivalent to around four-and-a-half DGX-A100 GPU systems. Paperspace will be offering that at a fraction of the price. And, you could be running multiple workloads on more than one Bow-Pod system.
But there’s another layer of abstraction coming – one that maintains all the capabilities of advanced AI and generative models, with the least complexity for the user.
AI-as-a-Service businesses will refine the user experience so anyone can use advanced AI – with no compromises in terms of sophistication and performance on the back-end.
If you’re a company – whether your industry is telecoms, retail, or finance, you are almost certainly sitting on a pile of text-based data about your business. That data might be an archive of materials, or it might be the inflow of real-time data.
Guaranteed there are valuable insights to be extracted, using artificial intelligence.
Even if you’re technically able to extract those insights, there’s another factor that affects their usefulness. Who are those insights going to and who is steering the process of AI-assisted enquiry?
If that process is primarily is in the hands of developers, you’ve introduced a level of distance that slows things down and places the subject matter experts and decision makers further away.
The real opportunity comes when you put those AI tools directly into the hands of those same subject matter experts and decision makers in your business.
What Pienso has achieved is a characteristic we expect to see in other successful AI-as-a-Service offerings. It allows users with little or no coding or AI expertise to run what are essentially highly complex operations - they just don’t feel like complex operations.
You might be fine-tuning an open-source model like BERT using your organisation’s own data. However, the process doesn't look or feel like fine-tuning – as most developers would know it. There is no need to think about weights and parameters. Instead, the user is pointing and clicking on categories to merge them, telling the system what is useful information for their particular application, and what isn’t. What’s happening on the back-end is real, leading-edge AI model usage.
Crucially models trained on Pienso belong to the user. Their data is not going back into a pool of training data to help optimise other people’s systems.
How do we know this is what the future looks like? Let’s apply our three tests, first to Pienso, and then more generally.
There is a diversity of open source models – you can choose the one that is right for the task in hand, and you can optimise it without paying model ‘rent’ to its creator.
It is efficient – not just because Pienso allows you to pick the optimal model for your use case, but because they are maximising the computational efficiency that powers the system – using hardware like IPUs and techniques like Packing. They are making it commercially viable for businesses to build on this technology.
It also makes AI more widely accessible to users without deep technical skills. In fact, but putting it in the hands of subject-matter experts within a business, the AI becomes an even more potent tool.
It is reasonable to apply these tests, these questions, to any new commercial AI offering that you may encounter:
Today, we are all tremendously excited by generative AI, how far it has come and where it might go in the future.
But if it is to become a truly useful tool that will add utility to society and aid economic growth, it needs to be a workhorse... not just a show pony.
A version of this blog was delivered as a keynote address by Graphcore's Helen Byrne at the Generative AI Summit in London, May 2023.
Helen's talk was entitled: "Commercialising Generative AI – Turning the Show Pony into a Workhorse".
Some additional content has been added, subsequent to the keynote.
Share: