Mar 28, 2023
Mar 28, 2023
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamA seismic shift is well underway in the world of large language models. For those of us who have been immersed in large language models (LLMs) for the past couple of years, the public reception to LLMs since the arrival of ChatGPT on the world stage feels like an arengataram of sorts, like a first solo piano concert after years and years of training.
Interactive AI is the elegant hybrid marriage of intuitive and responsive user interfaces with deep learning. A user interacts with the underlying machine learning algorithm using powerful user interfaces, where every user interaction guides the machine learning algorithm running in the background.
I am passionate about interactive AI Training. A compelling and valuable machine learning model requires careful and often subtle insights about the data. Insights that don't come directly from the data but from a nuanced understanding of how owners interpret it. Data owners have tacit and subtle insights about their domain in a way that is hard to represent merely by data labeling.
For example, a cardiologist's perspective on a research article about angina can be more nuanced than that of a deep learning engineer. But the cardiologist may not have a computer science and deep learning background and therefore rely on a data science team to build a model for her – a lossy, time-consuming, expensive, and often frustrating-inducing process.
The same people who need AI models should also train them.
But the status quo is one of barriers and impediments. The technical nature of the deep learning process: the need to code, data cleansing, data labeling, model training, and model deployment – this body of work increasingly referred to as "ML Ops" – have typically blocked domain data owners from doing their own AI modeling and surfacing their own AI-derived insights.
What's required is Interactive AI -- intuitive interfaces that cloak powerful under-the-hood AI in an approachable, point-and-click interface, allowing data owners to embed their insights into the underlying AI without needing to code or have any experience with deep learning.
This is precisely what we built at Pienso.
On November 30th, 2022, OpenAI released ChatGPT. While the text-based intractability or Chat portion of ChatGPT grabbed headlines, the underlying Large Language Model or LLM deserves the spotlight.
Why? Because massive things are heavy and hard and costly to move.
LLMs are massive – trained on gargantuan amounts of text data, (think: the internet, up to a point) with enormous capacities for a variety of text processing tasks that can supercharge productivity.
Business users may be interested in adapting a generic large language model to help understand user intention, feedback, and emotions in real-time. Physicians may train an LLM that can structure their medical notes. While LLMs can be powerful when fine-tuned to a particular business area, they are computationally expensive to train and deploy and require large numbers of costly hardware accelerators to function.
Building intuitive interfaces to equip interactive AI for the domain expert requires prompt responses to user input -- no one has time to wait minutes, let alone hours, for their AI-powered analysis.
To be adopted, fast and scalable inference from LLMs is essential. Despite their huge size, response times must be nearly instantaneous.
One way to increase inference speed from LLMs is to add more hardware accelerators. However, not only is this extremely expensive, but there aren't enough hardware accelerators available on the cloud providers where the LLMs are hosted to meet the need.
At Pienso, we make LLMs efficient and scalable inference possible by reducing the computational footprint of our large language models.
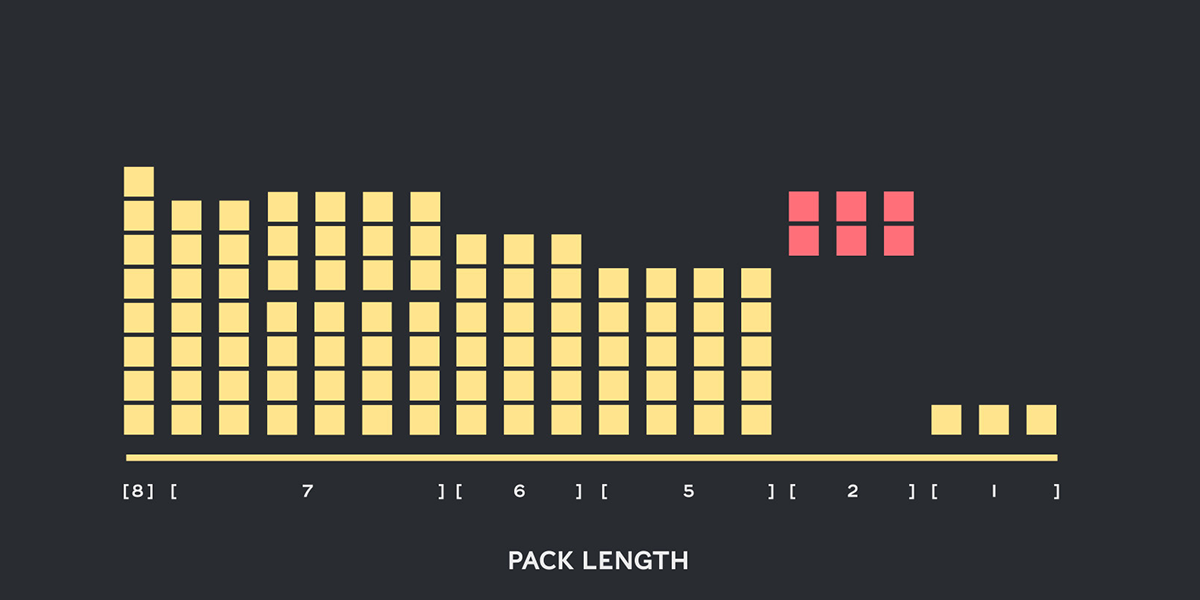
One crucial technique is packing.
First developed by Graphcore for fast training, packing is a way to drastically reduce the computational waste in arranging input text data and, and in doing so, radically reduce the time it takes to pre-train, fine-tune and infer from LLMs.
We have collaborated with Graphcore to productionize packing for large-scale and efficient inference for BERT-flavored LLMs in Pienso on Graphcore IPUs.
There are a variety of techniques to make inference faster and more scalable. Most current practices involve emaciating the original LLM into a smaller, more efficient version.
However, emaciating the model into a smaller computational footprint comes at the cost of inference' quality.
Packing, however, is different. We don't emaciate the original model. Instead, we minimize padding to reduce the computational waste.
For example, suppose every input text document can contain a maximum of 512 words (tokens). For every document with less than 512 tokens, the remaining spaces are padded with dummy values to ensure 512 tokens represent each document.
Very often, text documents have fewer than 512 tokens so the final corpus of documents has a massive amount of dummy padding values that contribute nothing to the training or inference process, but add meaningless weight.
Packing is a method to pack tokens as tightly as possible, eliminating extraneous and unnecessary padding, dramatically reducing the computational overhead required during training or inference.
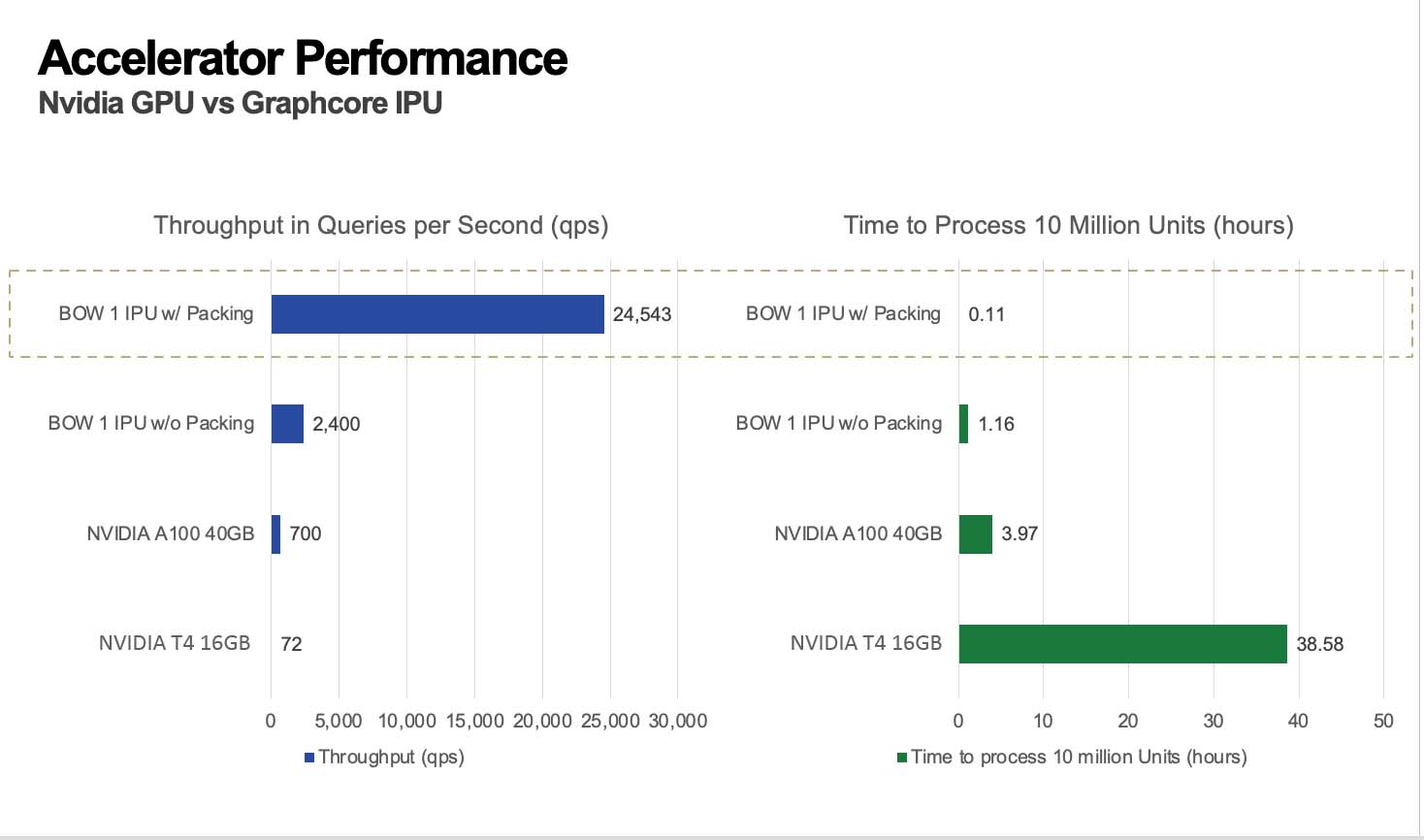
With packing, users can fine-tune a BERT architecture LLM with increased speed. Since fine-tuning BERT architecture models on IPUs is already faster compared to GPUs, fine-tuning with packing on IPUs results in dramatic reductions in training time, making per-epoch times virtually instantaneous.
.png?width=1992&height=1088&name=Updated%20Pienso%20(1).png)
Packing for fast training reduces response times and promotes a richer interactive AI experience. The faster one can train a model, the more time spent experimenting, and more experimenting leads to better models. Equally, packing allows for robust and efficient inference of LLMs.
Enterprises with massive volumes of data that need to be daily analyzed regularly use LLMs for inference. If they have deployed an LLM tuned with their data, they'd want to analyze high-volume new data in real-time using the deployed LLMs for inference.
Since packing makes inference scalable and virtually instantaneous, using additional LLMs to explore the same data is possible. For example, consider an enterprise with its foundation LLM for customer relationship management. If they’d like to infer customer intention and feelings for every sentence spoken or written by the customer, and every sentence needs one LLM inference each, 20 million daily customer sentences will require 20 million inference API calls.
If the inference time is slow, it means a constant backlog of data waiting to be analyzed with inference. With packing, we can make inference an order of magnitude faster without compromising model quality. What used to take hours can now be achieved in only a few minutes.
This near real-time ability to fetch inferences promotes a new line of thinking as new uses of LLMs are unlocked.
Ultimately, there is only user experience
As deep learning engineers, we pay attention to the quality of our models. We invest time and effort making better quality models that deliver accurate insights and generalize well to new data.
As interactive AI makes it more and more likely that the person interacting with AI is not a deep learning engineer but a domain data expert, user experience matters ever more.
A high-quality LLM does not deliver if the user experience discourages experimentation or the process is frustrating. Slow and tedious speed of training and inference will stymie AI adoption.
We must make both training and inference faster and more scalable, and do so economically.
Packing is one such method.
We’re pleased to productionize packing for BERT in our next Pienso release, and apply packing to new LLMs in 2023.
This is a guest post by Pienso Co-founder and CTO Karthik Dinakar. Pienso is a Graphcore partner that helps its customers to unlock actionable insights from their business' data, without the need for coding skills or prior AI experience.
Karthik is a computer scientist specializing in machine learning, natural language processing, and human-computer interaction. A Reid Hoffman Fellow Karthik holds a doctoral degree from Massachusetts Institute of Technology.
Share: