
Oct 14, 2022
Oct 14, 2022
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamWith the launch of Graphcore’s Poplar SDK 3.0, developers are now able to take advantage of the open-source NVIDIA Triton™ Inference Server when using IPUs, thanks to the addition of the Poplar Triton Backend library.
NVIDIA Triton™ Inference Server is widely used to streamline the deployment, running and scaling of trained and fine-tuned models in production environments. It provides a cloud and edge inferencing solution optimized for various types of hardware [1] while offering high throughput and low latency.
Here we will walk through the process of preparing the environment, starting the server, preparing the model, and sending a sample query to the server.
Please note that the example presented below is based on a model written with PyTorch for the IPU. This tool is called PopTorch and is a set of extensions for PyTorch that enable PyTorch models to run directly on Graphcore hardware.
PopTorch has been designed to require as few changes as possible to your models to run them on the IPU. Further information on PopTorch can be found in the documentation section of the Graphcore website.
To use NVIDIA Triton™ Inference Server with Graphcore IPUs, you will need to have access to the Poplar Triton Backend. This is available as part of the Poplar SDK which can be downloaded from the Graphcore software portal. New users may wish to read the Getting Started guide.
Deployment requires a saved, trained model. For this example, we will use a simple mnist classification model from the Graphcore tutorials repository.
Steps needed to train, validate and save the model, which will later be used to present the deployment process:
python3 -m pip install -r requirements.txt inference_model.save("executable.popef")python3 mnist_poptorch.py --test-batch-size 1This will result in training and validation of the model on the IPU using the PopTorch API and saving the executable.popef file, which will later be used by the Poplar Triton Backend. More information on the PopEF extension can be found in the user guide.
Now that the model and its configuration are ready, it is time to prepare the model repository along with the global backend directory (the rationale for doing this can be found in the NVIDIA Triton™ Inference Server documentation).
We need to create a server-readable directory structure, as presented below. This will be our model repository. The most important part is the executable.popef file that was just generated. The description of the name_map.json and config.pbtxt files will be presented in the following paragraphs.
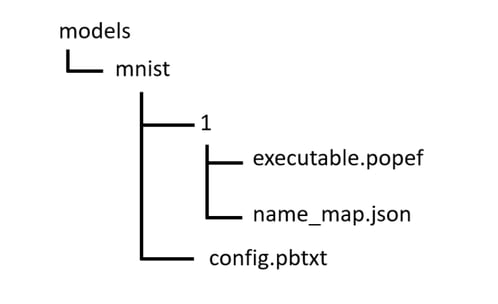
The names of the model’s inputs and outputs are not always user-friendly. Sometimes they also contain special characters that are not accepted by the NVIDIA Triton™ Inference Server. name_map.json allows you to remap these names. This requires you to know the names to be remapped. For this, you can use a tool called popef_dump, which allows inspection of the PopEF file structure and metadata.
$ popef_dump --user-anchors executable.popef
PopEF file: executable.popef Anchors: Inputs (User-provided): Name: "input": TensorInfo: { dtype: F32, sizeInBytes: 3136, shape [1, 1, 28, 28] } Programs: [5] Handle: h2d_input IsPerReplica: False Outputs (User-provided): Name: "softmax/Softmax:0": TensorInfo: { dtype: F32, sizeInBytes: 40, shape [1, 10] } Programs: [5] Handle: anchor_d2h_softmax/Softmax:0 IsPerReplica: False
The names of inputs and outputs are “input” and “softmax/Softmax:0”. The mnist model takes as input a picture that represents a handwritten digit, and as an output, it produces an answer of which digit represents the picture. Hence the names digit_image and output_labels are more appropriate and do not contain any unacceptable special characters. Below is the content of the name_map.json file.
The server must have information about the details of the model and configuration details to run it correctly on the hardware. A description of why this is needed and the possibilities are described on the Triton Inference Server GitHub.
There are many options that allow the execution of the model to be best adapted to our applications. In this case, we just want to run a single query and get the result, hence we need a minimal, simplest configuration. To do this we must specify platform and/or backend properties, the max_batch_size property and the input and output of the model [3].
We use an external backend that will be created in the next section. This will be called ‘poplar’. Hence, this name must appear in the configuration file.
The max_batch_size property indicates the maximum batch size that the model supports for the types of batching that can be exploited by Triton [4]. Our model is compiled for one batch, and we are not going to send multiple requests to Triton, hence we can set this value to 1.
The data type and size of inputs and outputs can be found using the previously mentioned popef_dump tool. The data type must be the same as that defined by popef, but it must also be specified in the nomenclature accepted by Triton Server.
Another important issue is the shape of the tensor. The first value for the dimensions displayed by the tool is batch_size, so you should omit this value when specifying it in the configuration file. The name of the tensor should be rewritten from the information displayed by popef_dump or the file name_map.json if it is specified. Below is the content of the configuration file that we will use in our example.
The model and its configuration are prepared. Now it is time to prepare the place that the server will refer to when executing the queries sent by the client application. After all, someone has to load the model onto the hardware, run it with the data sent by the client application, and return the result calculated by the hardware. Poplar Triton Backend will be responsible for this. For this we need to create the directory structure shown below:

Once you have access to the Poplar SDK and it is enabled, download Dockerfile which will allow the creation of a container with configured Triton Inference Server. Then run the following commands in the terminal. Please note, you should mount directory with the access to the backend directory and model repository (-v option).
Now that everything is prepared, you are ready to start the server.
After executing the command presented below, the server will listen for any incoming requests from client applications.
tritonserver \
--model-repository <your_path_to_models_repository> \
--backend-directory <your_path_to_backend_directory>
For example:
tritonserver \
--model-repository /mnt/host/models \
--backend-directory /mnt/host/backends
One piece of information that will be displayed on the terminal after starting the server is the address and port on which the server will listen for requests. We will need this information to send a query from the client application.
Example end of the output from the tritonserver application:
Started GRPCInferenceService at 0.0.0.0:8001
SessionRunThread: thread initialised
The first step to the request is to prepare the input data to be processed. Pictures can be downloaded from a publicly available source located in the torchvision.datasets module (example provided in our tutorials). Our mnist uses the dataset as a data source for training and validation steps. The example below uses some images from this dataset, downloadable here. The name of each corresponds to the number that appears in the picture. The pictures:
The next step is to prepare a script that will send the pictures prepared in the img folder to the server, which is constantly listening on the address and port mentioned in the previous section. Please note that the script below assumes that you have several modules installed:
The script below is divided into several parts. Establishing a connection with the server, preparing input data with pre-processing, sending and receiving data, post-processing output data, displaying the result.
Assuming that client.py contains the script indicated above, in the img directory there is a set of images mentioned at the beginning of the section and the server is waiting for incoming requests, the result of the above script will be as follows:
$ python3 client.py
Predicted digit for file "0.png": 0 Predicted digit for file "1.png": 1 Predicted digit for file "2.png": 2 Predicted digit for file "3.png": 3 Predicted digit for file "4.png": 4 Predicted digit for file "5.png": 5 Predicted digit for file "6.png": 6 Predicted digit for file "7.png": 7 Predicted digit for file "8.png": 8 Predicted digit for file "9.png": 9
As well as demonstrating the working of Triton backend, hopefully this blog gives you a sense of the ever-expanding possibilities for using the IPU, not limited to training – a point echoed in our blog post on TensorFlow Serving.
In our publicly available examples, you can find the use of NVIDIA Triton™ Inference Server along with an IPU with models from the cnns and nlp families. Common source code for these two examples can be found in utils directory. All examples can be found in our github account.
If you would like to learn more about the possibilities offered by our tools, you can read our documentation:
Share:


