Jul 18, 2022
Jul 18, 2022
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamA new paper by a group of Graphcore researchers will be published and presented in a poster session during the upcoming ICML 2022 Hardware-aware efficient training (HAET) workshop.
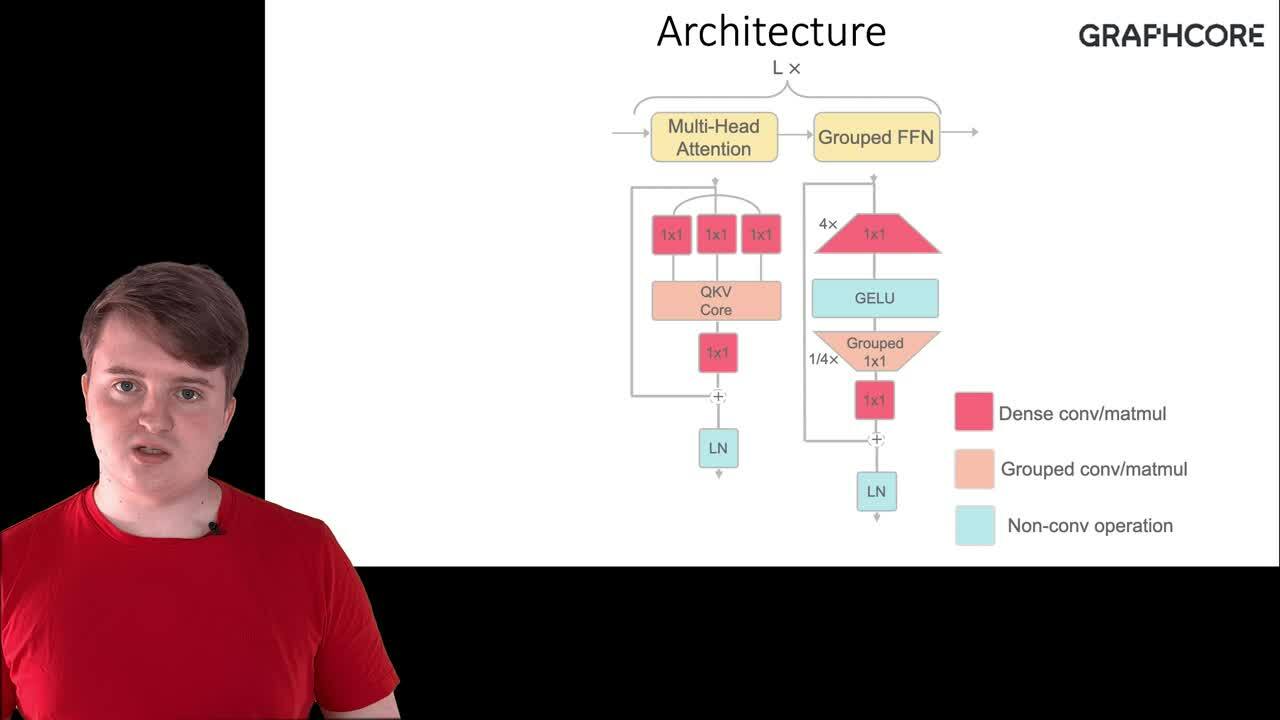
In the paper, titled "GroupBERT: Enhanced Transformer Architecture with Efficient Grouped Structures," the authors outline a set of modifications to improve the structure of a transformer layer, producing a more efficient architecture and saving power and time during training. The superior performance of this modified structure is shown through application to BERT, a family of transformer-based natural language processing (NLP) models. The broad strokes of the paper are summarised in the poster below.
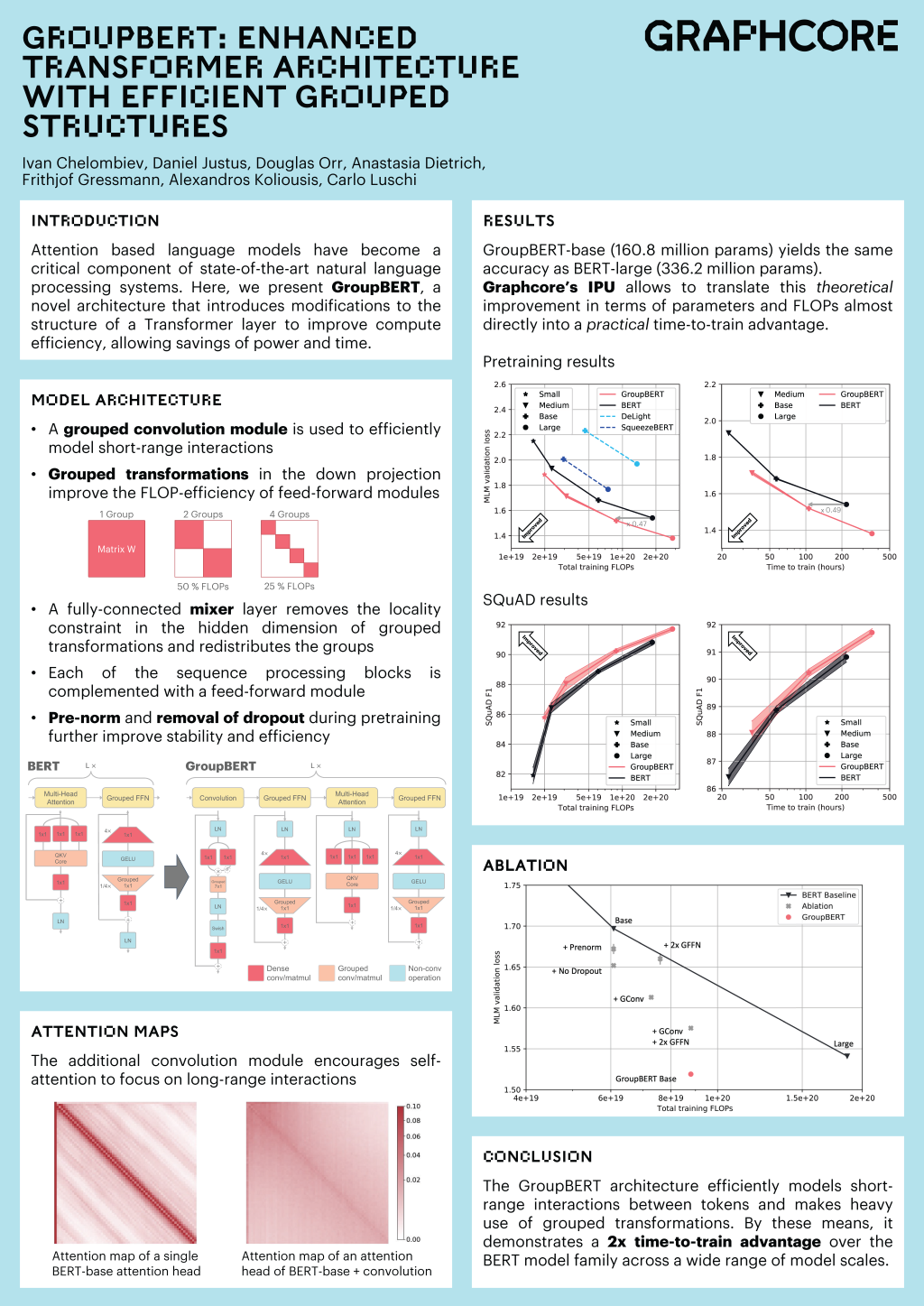 The HAET workshop aims to introduce and discuss novel approaches to reducing the energy, time, and memory cost of training deep learning models—leading to faster, cheaper, and greener prototyping and deployment. Due to the dependence of deep learning on large computational capacities, the outcomes of the workshop could benefit all who deploy these solutions, including those who are not hardware specialists. Moreover, it would contribute to making deep learning more accessible to small businesses and small laboratories.
The HAET workshop aims to introduce and discuss novel approaches to reducing the energy, time, and memory cost of training deep learning models—leading to faster, cheaper, and greener prototyping and deployment. Due to the dependence of deep learning on large computational capacities, the outcomes of the workshop could benefit all who deploy these solutions, including those who are not hardware specialists. Moreover, it would contribute to making deep learning more accessible to small businesses and small laboratories.
The workshop will be held on site at ICML 2022 from 08:45 to 17:30 EDT on July 23, with the poster session featuring GroupBERT running from 15:00 to 16:30 EDT. Further details are available on the workshop's website.
For a deep dive into the underlying research, take a look at our original GroupBERT blog post.
Share:


