
Jun 29, 2022 \ Machine Learning, Baidu, Benchmarks
Jun 29, 2022 \ Machine Learning, Baidu, Benchmarks
共有:
Graphcore IPUシステムの性能面での劇的な優位性が、最新のMLPerf比較ベンチマークで再び実証されました。
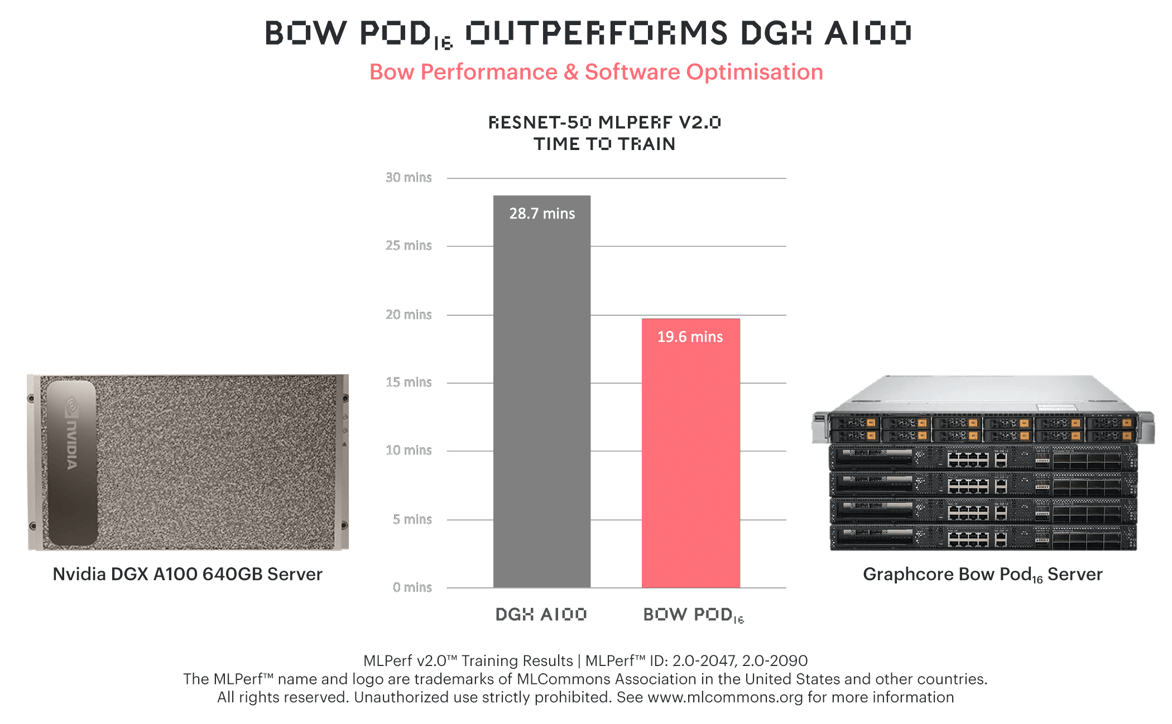
ResNet-50において、GraphcoreのBow Pod16は、NVIDIAの高価なフラッグシップモデルDGX-A100 640GBより31%も速い学習時間を達成しました。
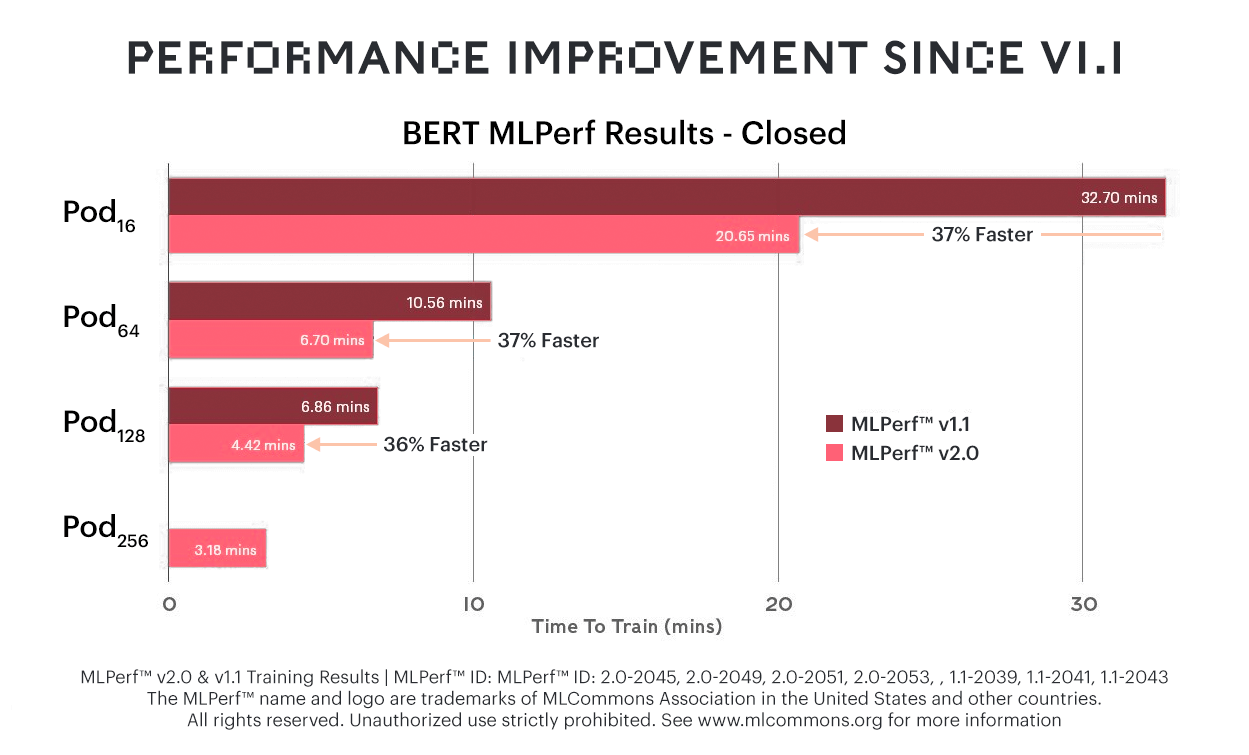
さらにBERTでは、前回のMLPerfと比較して37%の改善が見られ、Graphcoreのシステムが一般的な言語モデルにおいても価格性能比のリーダーであり続けることが確認されました。
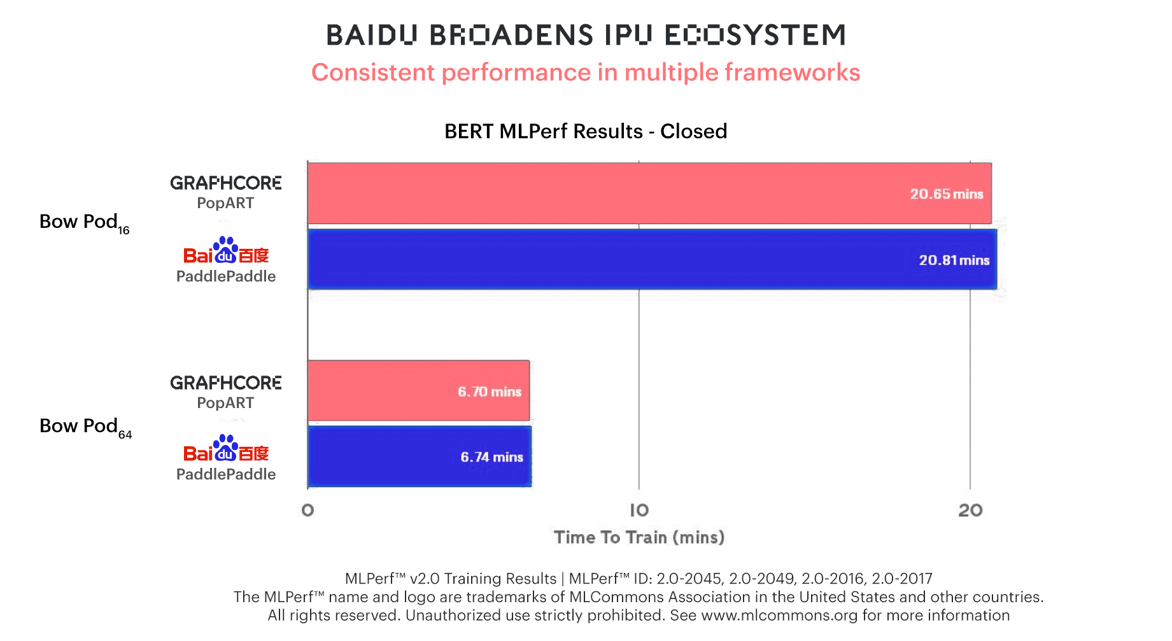
Graphcoreシステムを使用するサードパーティとして初めてベンチマークに参加したBaiduは、同社のPaddlePaddleソフトウェアフレームワークを使ってBERTの学習でも同じ性能を達成。IPUエコシステムの急成長を牽引している採用のしやすさや柔軟性を実証する結果となりました。
Graphcoreは2021年にMLPerfプロセスに参加した時点で、AIコンピュート性能の代表的な指標でIPUの能力を実証するという要求に応えていました。
当時は私たちのお客様や業界の評論家が、IPUの劇的に差別化されたアーキテクチャが、ResNetやBERTが文字通りその上に構築されたベクトルプロセッサとともに機能する様子を確認したかったのも無理ありません。しかし、私たちが成し遂げたのはそれ以上の成果でした。
Graphcoreはこのような価値ある実績にとどまらず、当社のお客様が現在導入しているResNetやBERTの後継モデルに注目し、より高いレベルの精度と効率を実現します。
グラフニューラルネットワーク(GNN)などの新たに出現したモデルクラスは、IPUのMIMDアーキテクチャや、きめ細かい並列処理をサポートするIPUの能力など、AI中心の特性を最大限に活用しています。このような種類のワークロードに対する性能差は、今日のAIコンピュートの大部分を占めるベクトルプロセッサアーキテクチャと比較して、場合によっては1桁分以上にもなります。
新しいBow IPUとソフトウェアの改良を組み合わせることで、ResNet-50の学習時間を前回のMLPerf(v1.1)と比較して最大31%短縮できました。
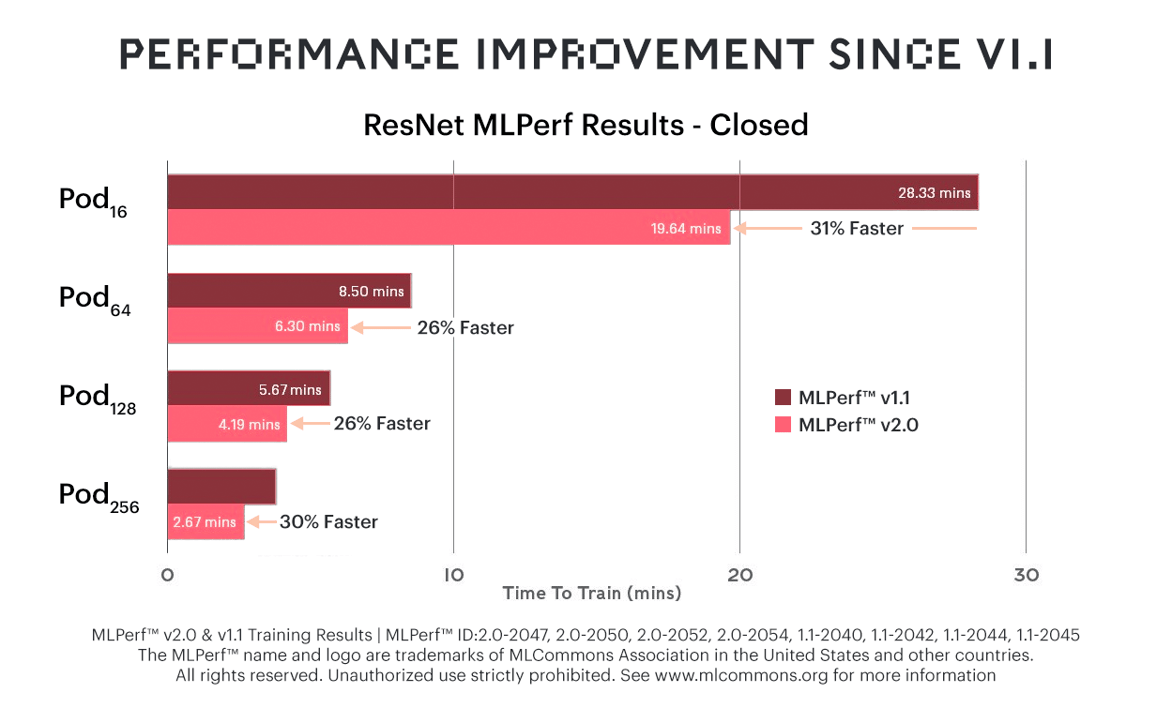 Bow Podシステムは、例外なく性能が飛躍的に高まる一方で、価格は従来のシステムと変わらないため、結果的に価格性能比において大きな優位性につながります。
Bow Podシステムは、例外なく性能が飛躍的に高まる一方で、価格は従来のシステムと変わらないため、結果的に価格性能比において大きな優位性につながります。
お客様は通常、IPUシステムを選択する動機の一つとして、Graphcoreの場合は価格に対して期待以上のAI計算能力が得られることを挙げます。
そのような性能の優位性は、DGX-A100 640GBなど、かなり高価格設定のシステムにおいていっそう顕著になります。
学習時間が最大37%改善されたBERTでは、Graphcoreの価格性能比には顕著な優位性があります。
 BERTの学習にBow Pod16とBow Pod64を使用したBaiduのPaddlePaddleのベンチマーク参加では、PopARTを使用したGraphcore自身の参加と同等の結果が示されています。
BERTの学習にBow Pod16とBow Pod64を使用したBaiduのPaddlePaddleのベンチマーク参加では、PopARTを使用したGraphcore自身の参加と同等の結果が示されています。
これは単に、Bow Podの性能に関して第三者が行った、説得力のある検証結果であるだけでなく、IPUエコシステムの急成長を牽引するGraphcoreシステムの柔軟性を実証するものでもあります。Baiduは、広く使われている同社のPaddlePaddleソフトウェアフレームワークとPoplarを統合し、素晴らしい成果を上げることができたのです。
GraphcoreはオープンカテゴリーでRNN-Tの結果も提出しました。
リカレントニューラルネットワークトランスデューサは、高精度の音声認識を行うための非常に高度な方法です。学習したモデルを最小限の遅延でハンドセットにローカルに展開できることから、モバイル端末で広く利用されています。
今回Graphcoreは、カスタマーサービスやコンプライアンス、プロセスオートメーションなどで音声ソリューションを提供する、当社のお客様Gridspaceと共同でRNN-Tの学習に焦点を当てました。
700GBまたは10,000時間の音声でRNN-Tモデルを学習し、Bow Pod64で動作するようにスケールアップした結果、学習時間が数週間から数日に短縮されました。
MLPerf 2.0にRNN-Tの結果を提出した背景には、IPU向けのモデルの実装と最適化を目指すGraphcoreの顧客中心主義があります。
ResNetやBERT、RNN-T以外にも、Graphcoreのモデルガーデンで提供されているIPU対応モデルの大半は、お客様の要望によって実現されたものです。
私たちは、実際に独立した数千のプログラムスレッドを実行する能力など、AI向けに作られたIPUのMIMDアーキテクチャを活用することで、急速に高度化するモデルに対応しています。
そのような例の一つは、TwitterのグラフML研究責任者であるMichael Bronstein氏によってつい先日まとめられました。IPUが時間グラフネットワークアプリケーションで最大10倍の性能向上を実現することが示されたのです。
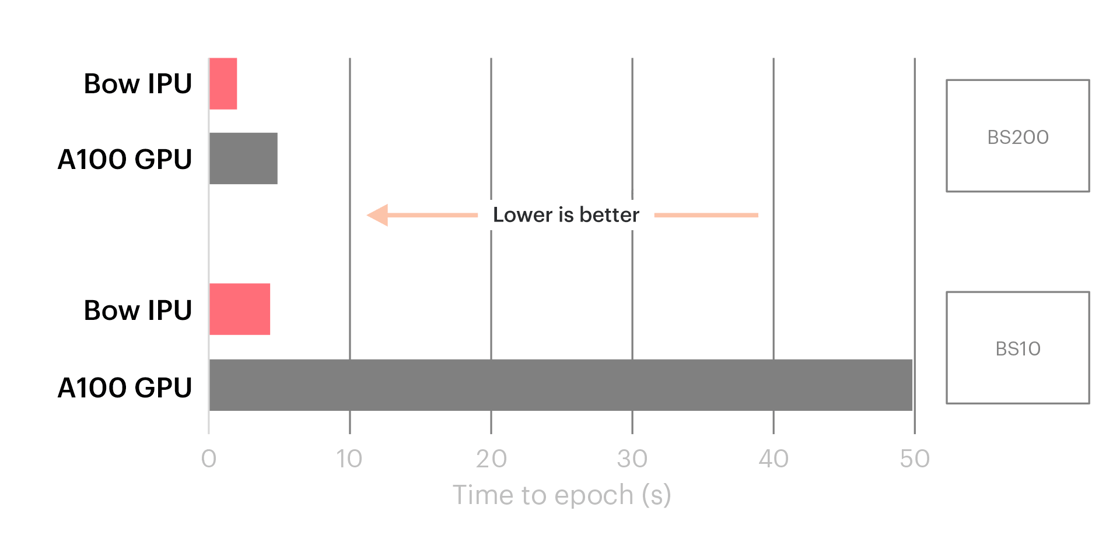
TGNではIPUがGPUを上回り、一般的で小さいバッチサイズではその差が顕著に表れた。
同様に、米国エネルギー省のPNNL研究所の報告では、IPU Classicシステムを使用したSchNet GNNの帰結時間が、V100 GPUセットアップと比較して36倍高速化されたことが示されました。
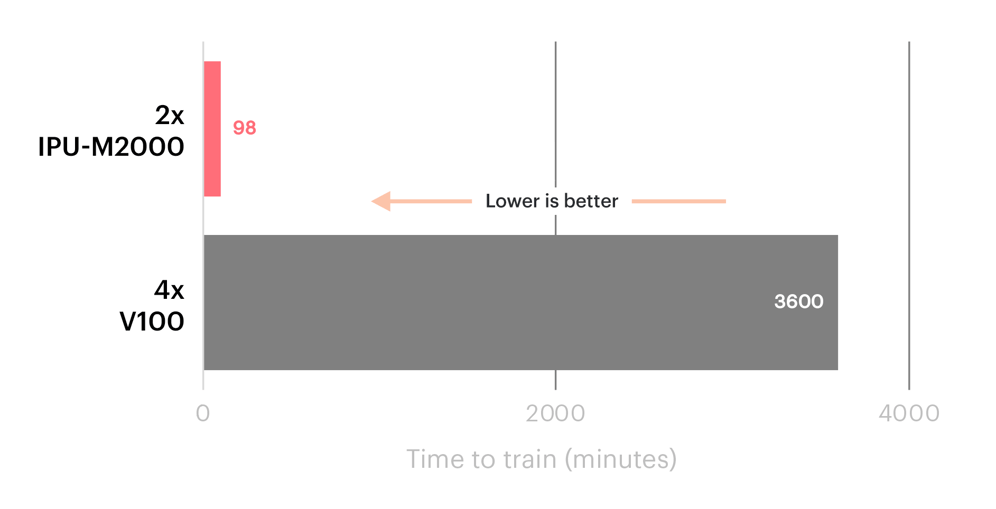
IPU ClassicとV100 GPUのSchNet GNNの性能比較
AIが現在のペースで発展していくためには、新しい機能や精度の向上をもたらすだけでなく、次世代モデルがより効率的に動作するようになる必要があります。そのためには、Graphcoreが提供するような新しいタイプのシステムアーキテクチャが必要です。
モデルのサイズと複雑さは、わずか数年の間に、数億のパラメータから数十億、そして今では数兆に膨れ上がっています。
その結果、テキストや音声、視覚などを扱うマルチモーダルなモデルなど、私たちはこれまでにない機能を手に入れてきました。
しかしその成長スピードは、いかなるシリコン技術でも追いつけないほど速いものです。それに対して業界はこの数年間、コンピュート機能の向上だけでこの問題に対処してきましたが、それは持続可能な解決策とは言えません。
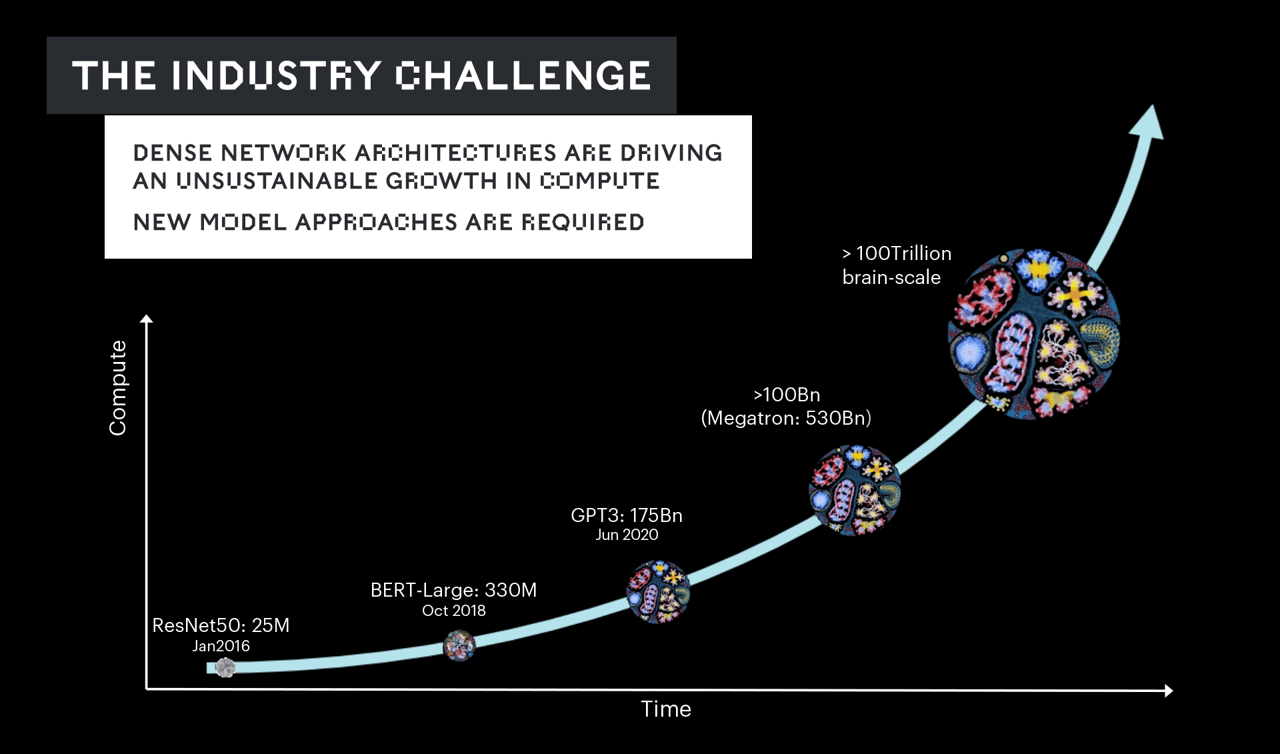
私たちの業界は、最大規模のモデルを学習するために数百万個のプロセッサを数か月間延々と稼働させ、その結果、数十億ドル以上のコストがかかるという、非常に現実的な見通しに直面しているのです。
このようなコンピュート機能の危機的状況を回避し、AIの継続的な発展を確かなものにするためには、IPUのようなシステム上で高度なモデルを開発し、最適化する必要があります。
Graphcoreが進めているのはまさにこのような取り組みで、お客様やパートナー様と協力もあり、すでに成果を上げています。
私たちは先日、Aleph Alphaの協力のもと、同社のマルチモーダルな大規模モデルにおいて、IPUが可能にする次世代技術を使い、より高い計算効率を実現する計画を発表しました。
大規模なAIコンピュートシステムのニーズがなくなることはありませんが、IPUの高度に差別化されたアプローチを活用することで、はるかに手頃な価格のシステムで数兆パラメータ規模に到達することも可能になります。
そのためにGraphcoreは、次世代IPUプロセッサだけでなく、システムメモリやマスストレージの新しいアプローチも駆使したGoodコンピュータの開発を進めています。
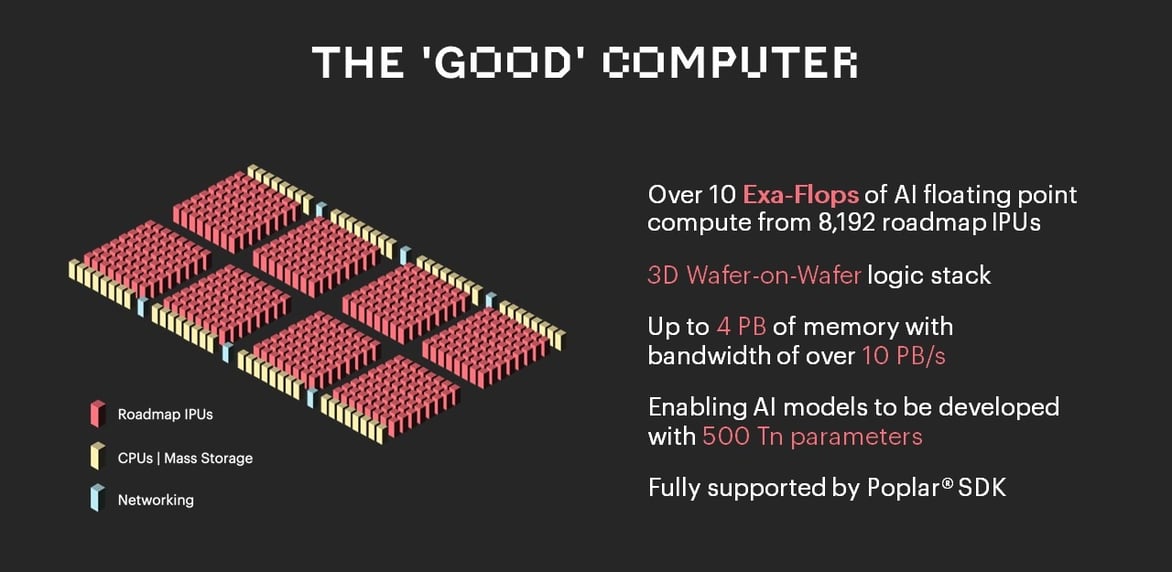 Goodコンピュータは、単にGraphcoreの製品ロードマップにおける次のステップではありません。AIコンピュートの持続可能な前進と、それがもたらす多くの有益なアプリケーションを象徴するものです。
Goodコンピュータは、単にGraphcoreの製品ロードマップにおける次のステップではありません。AIコンピュートの持続可能な前進と、それがもたらす多くの有益なアプリケーションを象徴するものです。
関連記事:超人的認知のためのコンピュータ – Simon Knowles(AICAS 2022にて)
共有:


