Graphcore Research demonstrate how we accelerated training the innovative computer vision model EfficientNet-B4 over Graphcore’s latest hyperscale IPU-POD128 and IPU-POD256 systems, reaching convergence in less than two hours.
Why EfficientNet?
The EfficientNet family of models showcase the state of the art in computer vision, achieving high task performance with relatively few parameters and FLOPs. Yet its adoption in practice is limited by the fact that legacy processor architectures cannot exploit many of the properties that make EfficientNet so efficient.
For example, the depthwise or group convolutions present in EfficientNets are both highly expressive and computationally efficient when compared to standard convolution operations, but have a low arithmetic intensity (ratio of compute to data movement). These types of operations perform poorly on GPUs due to the large amount of data transfer between the memory and processor cores. Thanks to the IPU’s memory-centric architecture, the entire model and its activations can remain on chip, alleviating this expensive movement of data.
Furthermore, the MIMD (multiple instruction, multiple data) paradigm of the IPU enables fine-grained parallelism over multiple dimensions of the model and training procedure. This helps to achieve high throughput while using small convolutions and processing very few data samples in parallel. In contrast, a GPU with its SIMD (single instruction, multiple data) architecture is limited in its ways to exploit parallelism, forcing the user to make a trade-off between the design of their machine learning algorithm and the attainable throughput of the algorithm on the hardware.
This acceleration on IPU hardware opens up the opportunity for more innovators and AI practitioners to benefit from EfficientNet models’ high efficiency for real-world implementations at scale.
Graphcore’s examples on GitHub provide a wide range of popular models for anyone to use on IPU straight out of the box, including the family of EfficientNet models. For this exercise we consider EfficientNet-B4, which is often used across the AI sector to benchmark EfficientNet performance.
Optimising Throughput
Distributing the Model
There are numerous ways to distribute a model over a set of IPUs, including data parallel replication and
pipeline model parallelism. Given the size of EfficientNet-B4 and the scale of the IPU-PODs, some combination of data and model parallelism achieves the best result. The Poplar software stack makes it easy to try out different distributed settings at the framework level, speeding up our search for the optimal way to configure the various types of parallelism.
The default configuration for EfficientNet-B4 in the GitHub examples pipelines the model over four IPUs. Having many pipeline stages means that more time is spent filling and draining the pipeline, reducing the overall IPU utilisation. It also means greater care needs to be taken to balance the workload across the IPUs. These challenges can be addressed if we are able to reduce the number of pipeline stages to just two. This also enables us to double the number of replicas.
To fit EfficientNet-B4 across just two IPUs, we employ three techniques:
- Use 16-bit floating point arithmetic and master weights
- Reduce the local batch size
- Use the G16-version of EfficientNet as explored in Graphcore Research’s "Making EfficientNet More Efficient" blog and paper
The IPU supports 16-bit and 32-bit floating point number representations natively, allowing users the flexibility to tune the representations of the various tensors present in the application. There are some cases where it may be necessary to store FP32 master weights, in which a copy of the model parameters is stored in full precision throughout training. We found that for EfficientNet, performance could still be maintained when using FP16 master weights and employing stochastic rounding on the weight update.
As the memory required to store activations scales with the batch size, it is important to consider how to reduce the activation overhead without impacting training. Activation recomputation is a method in which we can recompute activations as and when we need them for the backwards pass. This provides a simple trade-off between compute and memory. This method is available in Poplar and is easily accessible at the framework level via the pipelining API. With EfficientNet-B4, we can fit a local batch size of 3 using activation recomputation. This configuration allows more samples to be processed in parallel than the four-stage pipeline setting, as we have twice as many replicas to distribute the mini-batch over. For this work, we use Group Norm, a batch-independent normalisation method. As this model does not have any inter-batch dependencies, we can have any local batch size that can fit in memory and simply increase the gradient accumulation (GA) count to achieve whatever global batch size we please, allowing us to fit our activations in memory without impacting the model’s training dynamics.
By increasing the size of the convolution groups from 1 to 16 (and subsequently decrease the expansion ratio to compensate for the increase in FLOPs and parameters), we reduce the memory overhead of the MBConv block in EfficientNet. This has been explored in further detail in Graphcore Research’s
“Making EfficientNet More Efficient” paper, and is summarised on our
blog. In addition to saving memory, this variant of the model has the added benefit of increasing ImageNet validation accuracy.
These three techniques allow us to fit the model across just two IPUs without having to offload any optimiser state to the streaming memory, permitting training at a high throughput.
Data IO
When training machine learning models on powerful AI accelerator systems like the IPU-POD, a common bottleneck is feeding the model enough data to process from the host. PopRun is a command line utility that helps to alleviate this bottleneck by launching the application in a distributed fashion over multiple program instances. Each instance’s IO is managed by its corresponding host servers, allowing us to scale up our model to various IPU-POD systems without being limited by the speed we can feed our model with data.
While the ImageNet dataset is originally represented in INT-8, it is typically cast to a higher precision floating point datatype on the host as part of the preprocessing. By applying this conversion once the data is on the IPU, the communication overhead is reduced as the input data can be streamed to the IPU at lower precision. This helps to increase the rate at which data is fed to the model, further increasing the throughput.
Data movement within and between IPUs is achieved under a
Bulk Synchronous Parallel (BSP) execution scheme. With BSP, tiles (IPU processor cores) alternate between local computation and data exchange with other tiles, with a synchronisation step in between.
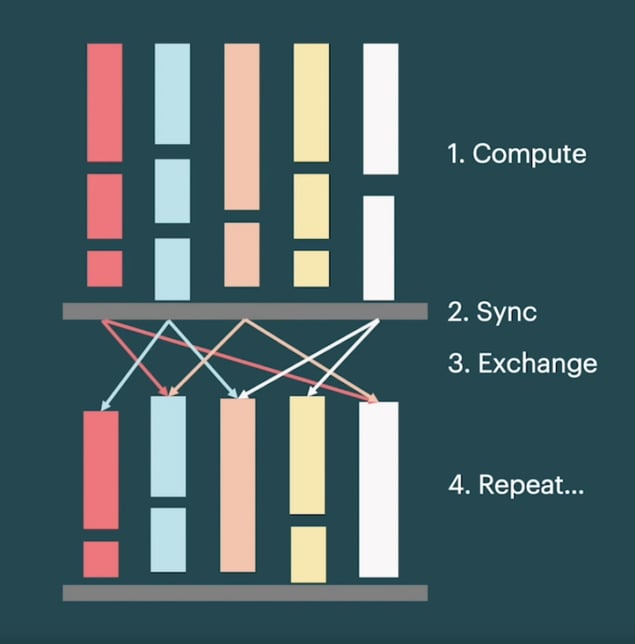
Bulk Synchronous Parallel (BSP) execution scheme.
This execution scheme enables Poplar to efficiently parallelise operations across hundreds of thousands of tiles. For applications that are IO-limited, a naïve BSP paradigm across all tiles would throttle performance. Poplar addresses this by allowing a portion of tiles to be dedicated to streaming data in an asynchronous fashion, while the remaining compute tiles execute under the BSP paradigm. Overlapping IO alleviates the IO bottleneck while still permitting a highly scalable execution scheme. We found that allocating 32 of the 1472 tiles per IPU to IO overlap and prefetching up to three batches of data, combined with the above methods, achieved impressive throughput at all system scales.
Scaling the Batch Size
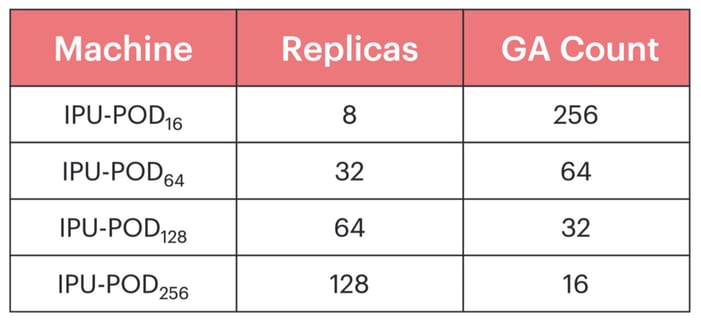
To train across large systems such as IPU-POD128 and IPU-POD256, it is beneficial to use a large global batch size. This allows us to parallelise the processing of data samples over many replicas, while ensuring each replica has enough work to maintain efficiency. Furthermore, to amortise the cost of reducing gradients across replicas, we locally accumulate gradients over multiple forward and backward passes before communicating between replicas and updating the weights, in what is referred to as gradient accumulation (GA). The global batch size is therefore the product of the local batch size, the number of replicas, and the gradient accumulation count.
Our baseline, taken from “Making EfficientNet More Efficient”, uses a global batch size of 768. Given our local batch size of 3, this would yield just two local batches per training iteration on an IPU-POD
256, underutilising the pipeline setup and having to contend with frequent costly weight updates. However, simply increasing the global batch size yields a degradation in generalisation performance. This phenomenon is common across many machine learning applications,
particularly in computer vision. We therefore seek a global batch size that is sufficiently large to maintain high throughput across all IPU-POD systems, but small enough that we attain good statistical efficiency.
It is well known that the
optimiser can have a large influence on the robustness of training with large batch sizes. The original EfficientNet paper used the RMSProp optimiser, which in our investigation struggled to maintain statistical efficiency when increasing the batch size.
Wongpanich et al. made a similar observation, and instead suggest using
Layer-wise Adaptive Rate Scaling (LARS), an optimiser known to work well for training vision models with large batch sizes. LARS scales the learning rate on a layer-wise basis to ensure a similar magnitude between the weights and the weight update. Alongside LARS, we also employ a polynomial decay learning rate schedule that is commonly used in conjunction with the optimiser.
Conducting hyperparameter sweeps over the batch size, learning rate, number of warmup epochs, momentum coefficient and weight decay, we found that we could achieve a global batch size of 6144 without any loss in performance compared to our original EfficientNet-B4 implementation. At this batch size, a high gradient accumulation count can be maintained across all the considered IPU-PODs.
Performance Results
With a flexible hyperparameter configuration, we are now able to train EfficientNet-B4 over a range of IPU-POD systems at a high throughput. As per the original EfficientNet paper, we train for 350 epochs. Although “Making EfficientNet More Efficient” demonstrated that the EfficientNet family of models can be pretrained at lower image resolutions before finetuning at their native resolutions, we maintained the original resolution in order to remain comparable to other implementations.
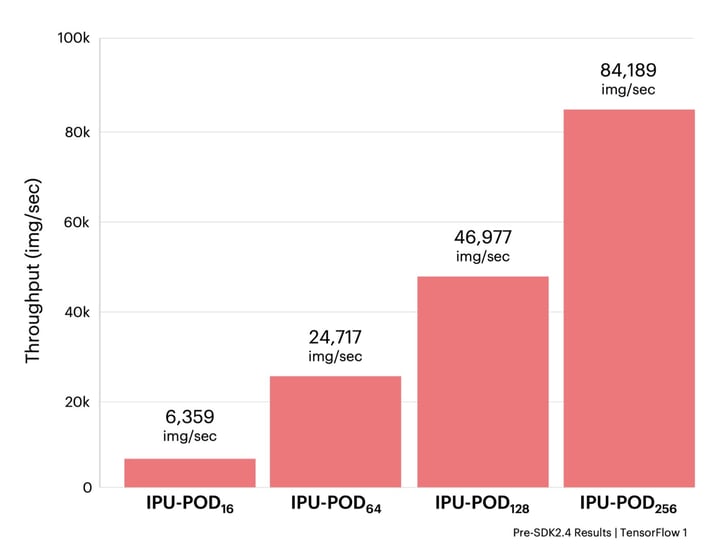
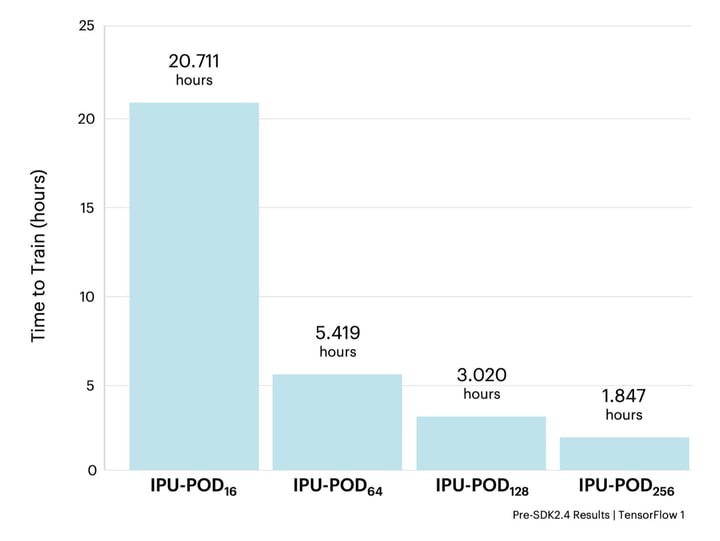
All the experiments used the same basic machine learning hyperparameter configuration by scaling the number of replicas and gradient accumulation count in accordance with the size of the IPU-POD. As a result, they all converged with a validation accuracy of 82.54 ± 0.13%.
The results above show how fast EfficientNet can be trained on IPU-based systems in contrast with results on leading GPU hardware. Being able to rapidly train models is essential for innovators to iterate and test on new ideas quickly – we can train EfficientNet-B4 in less than two hours, speeding up the rate of innovation from days to hours.
This speed-up demonstrates that many computer vision applications can be trained significantly faster at scale when not restricted by legacy processor architectures. Next-generation computer vision models like EfficientNet, when used with novel hardware such as Graphcore’s IPU-POD systems, could help accelerate a huge array of vision-related use cases, from CT scan analysis and video upscaling to fault diagnosis and insurance claims verification.
These configurations are available to try now on Graphcore’s GitHub examples. (Note: the latest configurations for all IPU-POD systems will be updated with our Poplar SDK 2.4 release.)
This article was originally published in Towards Data Science.
Read the article in Towards Data Science
Thank you
Thank you to Dominic Masters and Carlo Luschi who also contributed to this research, and thank you to our other colleagues at Graphcore for their support and insights.