
May 30, 2023
May 30, 2023
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamSee also Flan-T5 XXL Fine Tuning (added July 2023)
In the world of AI language models, there's no one-size-fits-all solution. Commercial users are increasingly coming to the realisation that Ultra-Large Language Models, while broadly capable, are AI overkill for many applications.
The penny (or dollar) usually drops when they receive an outsize bill from the owners of their preferred proprietary model, or cloud compute provider. That's assuming they can even secure GPU availability for the A100 and H100 system needed to run advanced models.
Instead, many are looking to more efficient, open-source alternatives to the likes of GPT-3/4.
In December 2022 Google published Scaling Instruction-Finetuned Language Models in which they perform extensive fine-tuning for a broad collection of tasks across a variety of models (PaLM, T5, U-PaLM).
Part of this publication was the release of Flan-T5 checkpoints, “which achieve strong few-shot performance” with relatively modest parameter counts “even compared to much larger models” like the largest members of the GPT family.
In this blog, we will show how you can use Flan-T5 running on a Paperspace Gradient Notebook, powered by Graphcore IPUs. Flan-T5-Large can be run on an IPU-POD4, using Paperspace's six hour free trial, while Flan-T5-XL can be run on a paid IPU-POD16.
We will look at a range of common NLP workloads and consider the following:
Let’s start by looking at some performance numbers from the Google-authored paper:
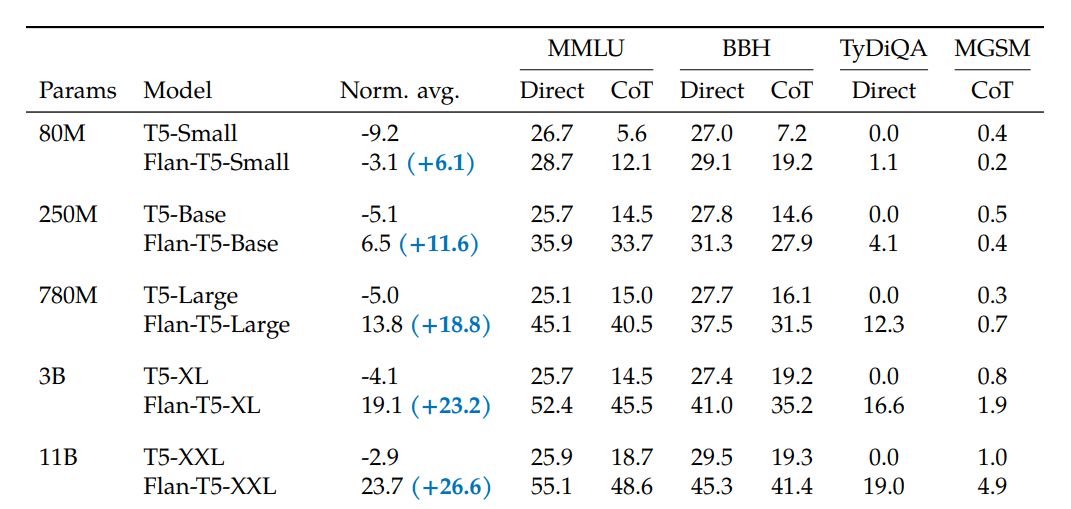
Part of table 5 from Scaling Instruction-Finetuned Language Models
These results are astounding. Notice that:
This establishes Flan-T5 as an entirely different beast to the T5 that you may know. Now let’s see how Flan-T5-Large and Flan-T5-XL compare to other models in the MMLU benchmark:
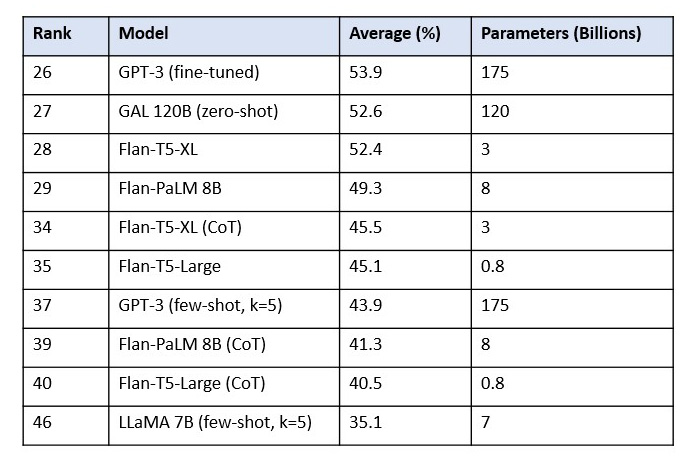
Part of the MMLU leaderboard from Papers With Code (CoT = Chain of Thought)
Noting that Flan-T5 had MMLU held out from training, this table shows that:
Since the Flan-T5 checkpoints are available on Hugging Face, you can use Graphcore’s Hugging Face integration (🤗 Optimum Graphcore) to easily run Flan-T5 with a standard inference pipeline.
If you already have an existing Hugging Face-based application that you’d like to try on IPUs, then it is as simple as:
Now let’s define a text generator of our own to use in the rest of this notebook. First, make sure that your Python virtual environment has the latest version of 🤗 Optimum Graphcore installed:
The location of the cache directories can be configured through environment variables or directly in the notebook:
Next, let’s import pipeline from optimum.graphcore and create our Flan-T5 pipeline for the appropriate number of IPUs:
Now, let’s ask it some random questions:
Note that some of these answers may be wrong, information retrieval from the model itself is not the purpose of Flan-T5. However, if you use Flan-T5-XL they are less likely to be wrong (come back to this notebook with an IPU-POD16 to see the difference!)
Flan-T5 has been fine-tuned on thousands of different tasks across hundreds of datasets. So no matter what your task might be, it’s worth seeing if Flan-T5 can meet your requirements. Here we will demonstrate a few of the common ones:
The following snippets are adapted from the Wikipedia pages corresponding to each mentioned company.
The following snippet came from the squad dataset.
The following snippets came from the xsum dataset.
As we saw earlier, when looking at the results from the paper, Flan-T5-XL is roughly 40% (on average) better than Flan-T5-Large across its validation tasks. Therefore when deciding if Flan-T5-XL is worth the cost for you, ask yourself the following questions:
To demonstrate, let us now look at an example of a task where the answer to all of the above questions is yes. Let’s say you have a customer service AI that you use to answer basic questions in order to reduce the workload of your customer service personnel. This needs:
Looking at the code below, we see some context about Graphcore provided in the input, as well as a primer for a conversational response from the model. As you can see from the example, Flan-T5-XL was able to understand the information provided in the context and provide useful and natural answers to the questions it was asked.