.jpg?width=1440&name=Whisper%20header%20(1).jpg "Whisper header")
Apr 25, 2023
Apr 25, 2023
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamUpdated August 2023: speeding-up Whisper using Group Quantisation
Whisper is an exciting new language model that takes a novel approach to speech recognition. It produces high quality results, even from low quality audio, and is extremely adaptable to a diverse range of voices and languages, without the need for fine-tuning.
Whisper is open source, and with a range of model sizes available, can be an efficient solution for a many speech to text applications including translation, smart personal assistants, vehicle voice control systems, customer service operations, and more.
In this blog, we will explore what makes Whisper different to other speech recognition models and we will show you how get started using the Hugging Face implementation of Whisper Tiny using a pre-built Paperspace Gradient Notebook, running on Graphcore IPUs.
For more information on the Group Quantization version of the inference notebook, jump to the end of this blog.
Whisper’s creators at OpenAI set out to solve several fundamental challenges that have faced Automatic Speech Recognition (ASR) up until now:
Many ASR models rely on very high quality, labelled, audio/text data to perform supervised learning. Unfortunately, this ‘gold standard’ of training data is in short supply. Models trained this way are capable of producing good speech recognition results under ideal conditions. However, because of their limited exposure to different training examples, they tend not to generalise well, can struggle with low quality real-world audio, and typically need additional voice fine-tuning to prepare them for specific use-cases.
The obvious way to improve such models would be to train them on more data, but the shortage of high quality datasets led AI practitioners to look in the opposite direction, developing ASR models with unsupervised learning, using vast amounts of unlabelled audio.
Models created this way are able to achieve very high quality representation of speech — but require subsequent fine-tuning to prepare them for specific ASR tasks. As well as entailing extra work, the fine-tuning process used in speech recognition has been shown to throw up some overfitting issues that can limit model generalizability.
Whisper’s creators described this problem as “a crucial weakness which limits their usefulness and robustness” and set out to design an ASR model that worked “out of the box”.
The Whisper solution starts with the same high quality, labelled audio datasets and augment them with much larger ‘weakly supervised datasets’ (such as video captions). This approach was partly influenced by research in computer vision that showed larger, weakly supervised datasets can actually improve the robustness and generalisation of models.
A number of techniques were used to detect and remove the lowest quality data, such as video transcriptions that had been generated by other ASR technologies due to the risk of transferring their limitations into Whisper.
Ultimately, 680,000 hours of labelled audio data was used to train Whisper, far more than previous, supervised models. Almost a fifth of the training data was non-English, spanning 96 languages. The dataset also included 125,000 hours of foreign language-to-English translations.
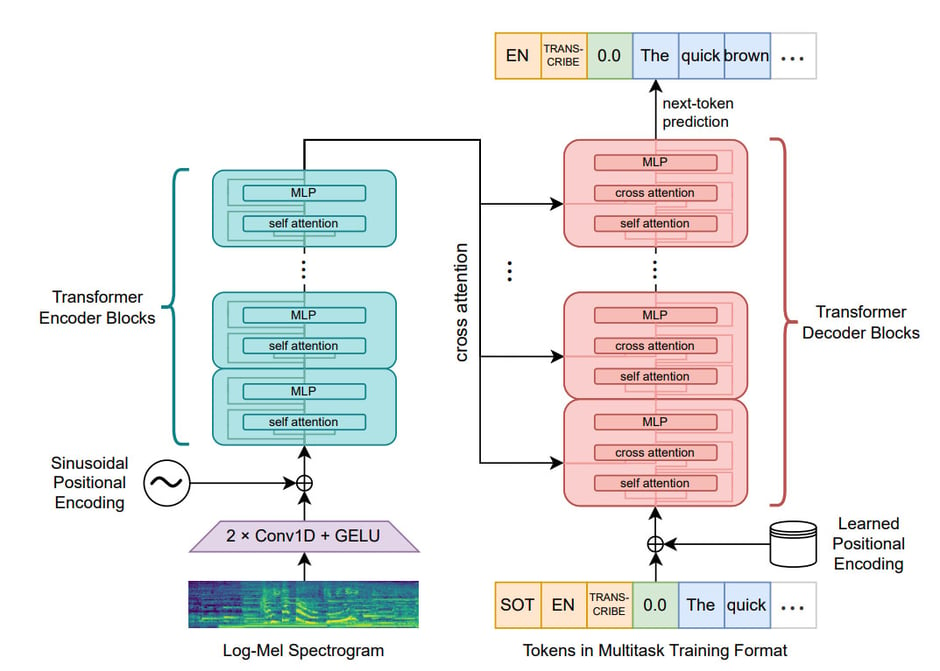
Whisper takes a classic encoder-decoder transformer architecture and applies it to audio/text pairs, using encodings generated from the audio to enable next token prediction on the text component.
Crucially, Whisper includes special tokens in the decoder that direct it to perform different language tasks, such as [transcribe] or [translate].
This approach differs from many AST models which use a variety of subsystems for different aspects of the speech to text process, such as voice activity detection, identifying different speakers, and normalizing the text format. Such architectures require additional resource to coordinate the complex interplay of sub-systems.
The performance of ASR models is typically measured by Word Error Rate (WER).
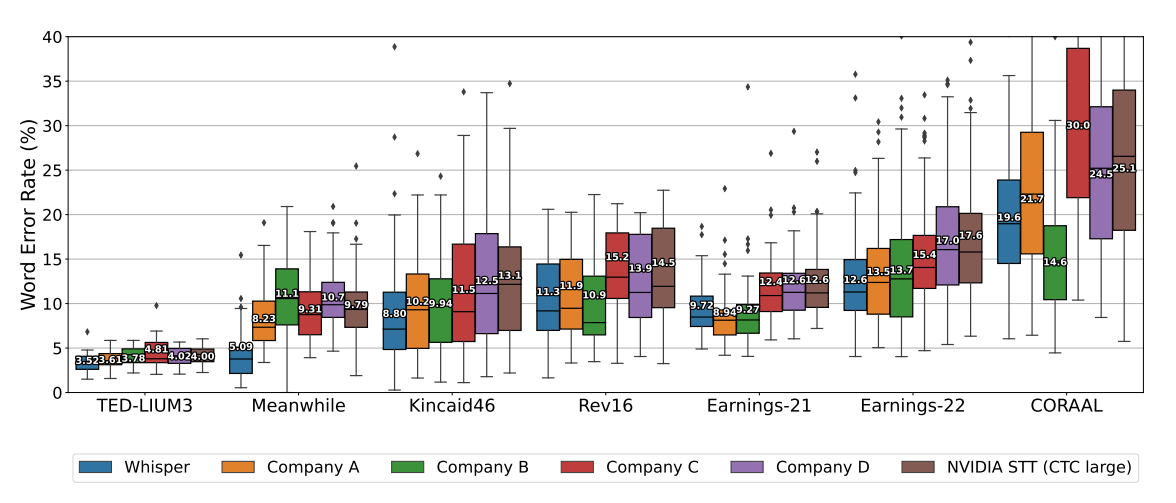
Whisper is competitive with state-of-the-art commercial and open-source ASR systems in long-form transcription. The distribution of word error rates from six ASR systems on seven long-form datasets are compared, where the input lengths range from a few minutes to a few hours. The boxes show the quartiles of per-example WERs, and the per-dataset aggregate WERs are annotated on each box. Our model outperforms the best open source model (NVIDIA STT) on all datasets, and in most cases, commercial ASR systems as well.
[Image and caption text from OpenAI Whisper paper]
As illustrated in the plot above, Whisper’s WER for long-form transcription is comparable to proprietary Audio Speech Recognition (ASR) systems, trained on ‘gold-standard‘ datasets. However, because of its larger corpus of training data and the use of ‘weakly labelled‘ examples, Whisper proved much more robust when measured using other training benchmarks, without the need for fine-tuning.
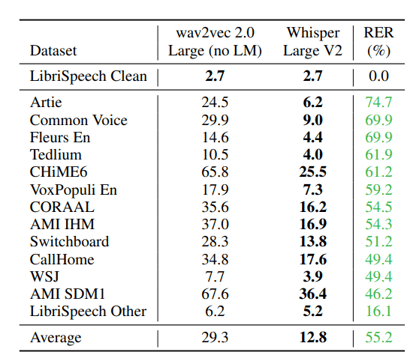
It is worth noting that the Word Error Rate for different languages varies significantly. The chart below shows performance variance for Whisper Large v2 using the Feurs dataset. In this instance, Spanish and Italian perform even better than English, while Zimbabwean Shona and Pakistani Sindhi fare worst, out-of-the-box. Performance for Whisper Tiny may be different.
.png?width=569&height=734&name=2023-04-21%2014%2029%2007%20(1).png)
Developers can use a pretrained Whisper Tiny (39m parameters) for inference on Graphcore IPUs via a Paperspace Gradient Notebook.
Whisper Tiny
inference
![]()
Users can get started with a six hour free trial, or upgrade to a paid tier if they need more.
Other versions of Whisper are available for IPU and if you want to find out more, contact us via this form.
Running Whisper in a Paperspace Gradient Notebook on IPUs is simple.
We will be using Hugging Face’s IPU-optimized transformers library, optimum-graphcore.
You will also need a few other libraries to manipulate sound files, tokenise the inputs for the model and plot our results.
Following this guide, you will be able to transcribe audio content in very little time.
Next, let’s import the part of the libraries that we will use today.
We can now choose the model to use and its configuration. Here we are going for Whisper tiny.en which allow for fastest execution speed whilst also have great transcription quality as it is specialised in a single language, English. We are going to use two IPUs to run this model, on the first we place the encoder -side of the Transformer model and on the second the decoder. By calling .half() on our model, we are enabling the use of fp16 precision resulting in near double throughput in comparison to fp32.
The model is ready, now let’s get some audio data to transcribe. We are using the well known librispeech which contains pairs of audio data with corresponding transcriptions. If you are using your own audio and need to convert it into a file format recognised by Whisper, we would suggest using an free application such as Veed's free audio convertor.
Then, we create a function to call our Whisper model and call on the audio data. After this, we print the generated transcription to the console and observe that it match the ground truth that we got from librispeech and observe visually the audio we just transcribed.
This notebook was added in August, 2023. It demonstrates the use of group quantization in Whisper inference to compress the weights from FP16 to INT4.
Group quantization is a common scheme and divides each weights matrix into groups of 16 elements and for each group store the maximum and minimum values as FP16. Then, it divides the range between the minimum and maximum values of each group into 16 intervals and finally codes individual elements as an INT4 based on the interval that they fall into.
This gives a compression of about 3.5x. While the model is running in forward mode, the weights are decompressed on-the-fly back to FP16 for calculation. There is a small loss of accuracy when using these compressed values, but it is typically only about a 0.1% word error rate (WER).
Hopefully you agree that it is quick and easy to get started transcribing with Whisper on Graphcore IPUs.
Of course — Whisper has many more talents, such as translation and multi-lingual transcription. If you want to take your Whisper usage on IPUs further, or explore larger versions of the model, please feel free to contact us.
Share: