
Oct 12, 2022
Oct 12, 2022
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamIn a seminal paper published two years ago, OpenAI introduced GPT-3, their 175 billion parameter text generation model.
Soon afterwards, a fully trained GPT-3 was made available via API, allowing researchers, media and the public to witness the extraordinary breadth of capabilities offered by this model class – from generating Shakespearian sonnets to turning plain English instructions into HTML.
Since then, large language models have played a predominant role in the public discourse around leading-edge artificial intelligence and helped to popularise important concepts such as unsupervised learning.
The term ‘large models’ has begun to give way to ‘foundation models’ which better describes their broad utility and the potential to create specialised derivations.
Large is also a relative concept and, as we will discuss later, foundation models don’t necessarily have to keep increasing in size, even though that has been the trend thus far.
Given the significance of such models, it is unsurprising that customers often ask us about them. This blog will offer a high-level introduction to large/foundation models, their utility, and future direction of travel, as well as how we at Graphcore will deliver systems that are optimised for performance and efficiency on these models in the years to come.
In essence, GPT-3 is a text prediction model, able to take an initial user prompt and generate subsequent language based on a rich understanding of the text’s internal relationship, context and any explicit direction provided by the user.
Applications can range from ‘simple’ sentence completion to sophisticated transposition – such as text summarisation.
The size of the dataset that GPT-3 is trained on (300bn tokens – around 225 billion words) is what makes it capable across a wide range of domains, without the need for fine-tuning.
In lieu of fine-tuning, output can be enhanced by the user including examples of a task and expected output in their prompt, as well as adding a specific request – known as ‘few-shot learning’ e.g.
The ability of GPT3 to handle few-shot learning is described as an ‘emergent’ ability by Wei et al in their paper Emergent Abilities of Large Language Models. As defined by the paper’s authors, such abilities are a property of larger models whose creation or emergence cannot be predicted.
The idea that such capabilities will present themselves as a result of training large models on a diverse body of data is one of the reasons that this aspect of AI commands so much attention.
In the same paper, the authors speculate on how this ability might change in the future: “Although we may observe an emergent ability to occur at a certain scale, it is possible that the ability could be later achieved at a smaller scale—in other words, model scale is not the singular factor for unlocking an emergent ability. As the science of training large language models progresses, certain abilities may be unlocked for smaller models with new architectures, higher-quality data, or improved training procedures.”
The potential to achieve 'large model' capabilities while working with smaller models is tantalising for many reasons, not least as a means of addressing the spiralling computational burden associated with large models’ exponential growth.
2018’s BERT-Large, with its 355 million parameters, consumed approximately 6.16 PetaFLOPS-days to train. By 2020, GPT-3 required around 3,640 PetaFLOPS-Days to train. While the actual dollar cost of training the latter has not been made public, estimates range from $10 to $20 million.
As the expense of working with ever-larger models threatens to become a drag on AI innovation, even for big technology companies and research institutions, there is a growing need to find new efficiencies, both in model design and the compute platforms that they run on.
There is also the matter of who can participate in the business of developing foundation models. Reducing the computational burden will have a democratising effect, ensuring that this work remains within reach of a wider circle of AI practitioners.
Significant progress is already being made on finding efficiencies in model design.
DeepMind’s work on Chinchilla suggests that current models are undertrained, and that better results may be achieved by training smaller models on more text, rather than increasing the overall model size.
Improving the quality of training data can also help deliver significant efficiencies, as shown in the 2022 paper Beyond neural scaling laws: beating power law scaling via data pruning.
Aleph Alpha, a German company developing leading-edge NLP models, is working on the sparsification of large models, potentially bringing further efficiencies to the field. The company has chosen to work with Graphcore on this endeavour because it recognises that radical new approaches to delivering efficient AI rely on taking a fresh look at compute hardware alongside innovative model design.
The role of compute systems in enabling the continued, rapid evolution of large model AI is multi-faceted.
Architectural innovation can deliver a ‘straightforward’ price/performance benefit – a useful counter to growing compute requirements. There are many such characteristics in the Graphcore IPU, including its innovative coupling of on-chip SRAM and off-chip DRAM in place of expensive HBM.
Our recently launched Bow IPU also makes industry-leading use of wafer-on-wafer production techniques to further improve compute performance by up to 40% and power efficiency by up to 16%.
The cumulative value of such efficiencies becomes highly significant when dealing with larger models.
Just as importantly, by designing our hardware and software to meet the specific requirements of current and emerging AI, we enable innovative approaches – like sparsity - that, in a virtuous cycle, deliver more efficient, more capable models. We discuss this further in 'natural selection' below.
Together, these can be thought of as hardware efficiencies and hardware-enabled AI innovation.
There is good reason to pursue the advancement of foundation models.
One of the most promising capabilities that is beginning to emerge is multi-modality; the ability of a single trained model to accommodate different types or ‘modes’ of data, such as text, images, audio and most recently video.
Crucially, these modalities can be made to interact, resulting in abilities such as describing the contents of an image in text. This is one of the capabilities offered by MAGMA, a multi-modal model created by Graphcore’s partner Aleph Alpha.
The cover image of this blog was generated from the text input "a dream in space" using Midjourney's image generation bot.
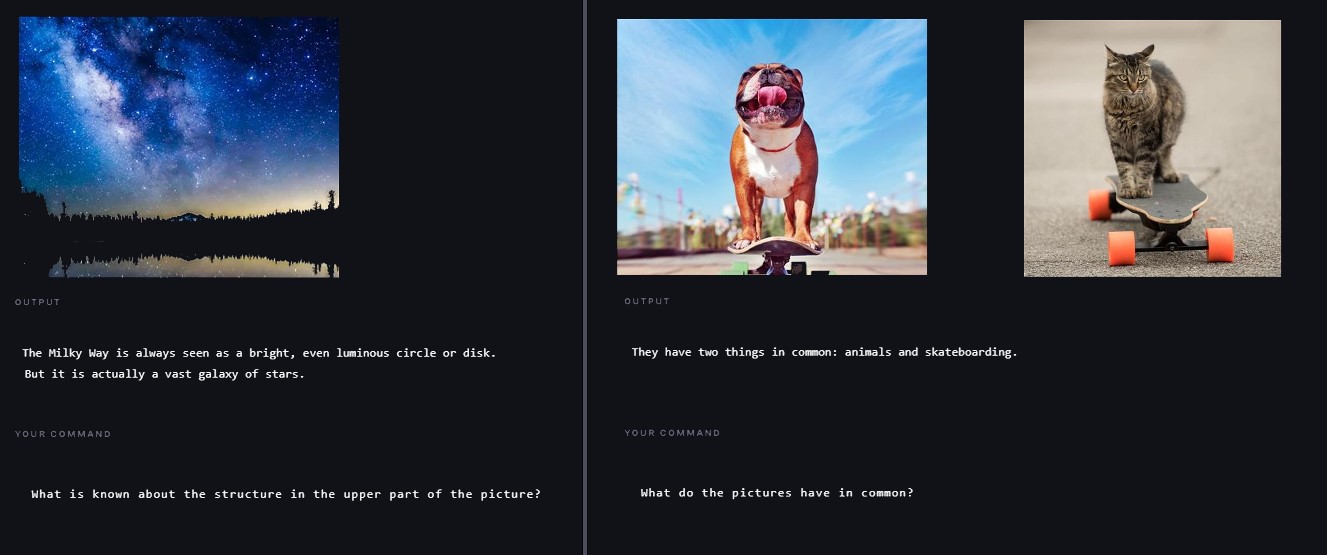 In their paper on the multi-modal BEiT model, Wang et al. describe how masking techniques used on language can also be applied to images to train a vision transformer. Images, in their work, are treated as a “foreign language”.
In their paper on the multi-modal BEiT model, Wang et al. describe how masking techniques used on language can also be applied to images to train a vision transformer. Images, in their work, are treated as a “foreign language”.
They also point out that “scaling up the model size and data size universally improves the generalization quality of foundation models, so that we can transfer them to various downstream tasks.”
This observation supports the idea that, in coming years, there will be organisations dedicated to training multi-modal foundation models, and there will be those that make use of derived subsets of those – on which entire businesses will be built, entirely in the cloud.
DreamBooth, developed by Google Research in 2022, allows users to effectively fine-tune a text-to-image generation model by adding their own photographs, integrating them into the pre-trained multi-modal modal. Users can then generate AI art featuring ‘characters’ that they have introduced.
At Graphcore we are actively working on large model fine-tuning. We recently published on Hugging Face checkpoints for a fine-tuned version of the 6B parameter model GPT-J, trained on the GLUE MNLI dataset. The MNLI task is to take two sentences referred to as the hypothesis and the premise as input and decide if the sentences entail (support), are neutral (cover different subjects) or contradict each other.
To do the task with a generative language model, we create a stylised prompt string containing the two sentences. The first word of the model output is then the result.
Prompt: "mnli hypothesis: <hypothesis-sentence> premise: <premise-sentence> target:"
Output: " {entailment|neutral|contradiction}|<|endoftext|>"
To continue the development of foundation models, finding computational efficiencies will be essential – both for the model makers and model users of the future.
Graphcore technology will help ensure that the ability to create foundation models remains relatively widely accessible – allowing the development of models that account for linguistic, cultural and other differences. At the same time, we will also help lower the barrier to entry for those working with foundation model derivations.
AI’s direction of travel involves several converging streams of innovation, including mixture-of-experts (tasks directed to the most appropriate model), sparsification, and multi-modality.
The destination is systems where tasks can be directed through specific routes, as opposed to activating the entire model – analogous to how the brain works. This allows a massive increase in capability, without a corresponding increase in compute demand.
This approach is known as selectivity, conditional sparsity, or as Google Research describes it, ‘Pathways’.
Graphcore’s CTO Simon Knowles outlined in his keynote at ScaledML 2021 that such techniques are essential if we wish to achieve brain scale machine intelligence, with the many capabilities that would unlock.
Models will no longer be compute-limited, but dependent on the availability of large amounts of memory to hold model state.
The Graphcore IPU chip and system architecture has been designed with such requirements in mind.
Our customers also attest to the IPU’s suitability for running mixture-of-experts models, as well as unlocking the potential of more advanced multi-modal and sparse models.
These characteristics heavily inform Graphcore’s next-generation compute system, the Good Computer. Our system architecture – built using a new logic-stacked wafer-on-wafer IPU, in combination with large amounts of memory - is effectively custom-built for next generation AI, uncompromised by legacy processor design.

The evolution of foundation model AI that we’ve outlined here, and its associated compute requirements, hopefully explain our confidence in the Graphcore IPU and associated systems.
In coming months, we will be making announcements on IPU-specialised training of GPT-3 size models, support for fine-tuning with large models and increasing emphasis on multimodality. In parallel, we are developing approaches to selectivity and large mixture-of-experts models.
Emergent capabilities will bring uses that no-one can foresee today – that is one of the things that makes large/foundation model AI truly exciting. But we do know what it takes to get there, and at Graphcore we’re working hard to make the future happen.
Share:


