
Jul 08, 2021
Jul 08, 2021
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamIn a new Graphcore research paper, we demonstrate how to implement sparse training efficiently using large-scale language model pre-training on the IPU as an example.
Sparse neural network research drives a virtuous cycle of innovation. Algorithmic improvements make it possible for software libraries to represent sparse patterns effectively. Programmers can then use these libraries to make the most of the available hardware and reduce computational requirements as a result.
At the same time, hardware innovations allow the introduction of more efficient and flexible software libraries, enabling researchers to explore algorithmic innovations.
Recently, this innovation cycle has produced exciting advancements on all levels. For instance, the Lottery Ticket Hypothesis (Frankle and Carbin, 2018 and Frankle et al., 2019, Ramanujan et al., 2019, Pensia et al., 2020) has highlighted the algorithmic insight that a small subset of weights of a trained model is sufficient to represent the learned function to a high degree of accuracy (Han et al. 2015). Driven by this idea, novel training methods have been proposed to ‘rig the lottery’. That is, to find high-accuracy sparse subnetworks without incurring the computational cost of dense training (Evci et al. 2020, Jayakumar et al. 2020).
Alongside this work, notable efforts have been made to extend major machine learning frameworks’ software support for sparse computation. OpenAI’s push to integrate its block sparse toolbox into PyTorch is one example of this improved support.
At the hardware level, major innovation is also underway. New accelerators specifically designed to support sparse computation, like Graphcore’s Intelligence Processing Unit (IPU), are becoming widely available to innovators in industry and academia.
All these developments are very timely, given the recent explosion in AI model size growth. Today’s widely used large-scale Transformer-based language models like GPT3 are a pertinent example of ever-increasing model sizes in state-of-the-art architectures. While these ever-larger models bring consistent accuracy improvements, training and inference becomes much more computationally demanding. In this context, improved sparse methods have great potential to limit cost and energy consumption, helping to make models more widely accessible while mitigating environmental issues caused by high power consumption.
In our case study, as presented at the SNN Workshop 2021, we explore the potential of sparse computation using the concrete example of scalable language model pretraining on the IPU processor. Specifically, we implement a strong sparse pretraining baseline of the BERT language model and demonstrate its superiority over dense models when compared on a floating point operation (FLOP) basis. Beyond the exploration of various aspects of the hardware, the software and the algorithms involved in this case study, we hope that our findings can serve as a practical starting point for further research in this area.
Let’s now highlight some of the key findings of our workshop contribution. We’ll start with an overview of the IPU and the features that make it well suited for sparse computation. Next, we’ll introduce the open-source software libraries that we use to implement our sparse algorithms. And finally, we’ll discuss experimental results that shed light on some of the algorithmic properties that can aid efficient execution.
The Graphcore IPU is a novel, massively parallel processor that has been specifically designed for machine learning workloads. The second generation of the chip has 1,472 totally independent processor cores (called tiles), each with 6 threads, which allow it to run 8832 independent, concurrent instructions at once (multiple instruction multiple data (MIMD)). Notably, each tile has its own chunk of in-processor memory that can be accessed at 180 TB/s per card, which is over 100x the memory access bandwidth of off-chip DRAM. The colocation of compute and memory in the IPU not only makes it more energy-efficient, but also means it is very well suited for highly irregular computation which has to be parallelised using a fine-grained, flexible approach.
Since the IPU has been especially designed for a large amount of parallelism, this makes it particularly well suited for sparse workloads. The algorithmic sparsification of network topologies often leads to highly irregular computation graphs with fine granularity, so the IPU’s ability to efficiently parallelise even the smallest computation structures is an advantage.
IPU architecture can maintain computational efficiency for sparse training and inference even when the granularity of the sparse structure is high. The multiply-accumulate unit of size 16 allows the IPU to achieve good thread utilization and performance even for very small block sizes of 1x1, 4x4, 8x8 or 16x16. The IPU also supports a number of instructions designed to accelerate common sparse primitive computations which further help to boost throughput.
All hardware and architectural features can be targeted through optimized kernels that are available through popsparse, a flexible low-level C++ library for sparse computation. Popsparse is one of Graphcore’s open-sourced software libraries (known as PopLibs) which builds on top of Poplar, Graphcore’s graph construction and compilation API that underpins everything running on the IPU.
The sparsity kernels can be either directly targeted through the PopART API or easily integrated into existing TensorFlow models through the TensorFlow and Keras layers used in this work. Sparsity with block sizes 1x1, 4x4, 8x8, 16x16 in both FP16 and FP32 are supported. Graphcore provides open-source implementations and tutorials in public examples on GitHub.
The Poplar software stack supports both static and dynamic sparsity, depending on whether the sparsity pattern of the algorithm is fixed or evolves over time. Using static sparsity allows for increased optimisations at compile time that improve execution efficiency, making it ideally suited for inference workloads involving already trained models. However, many training algorithms slowly evolve the sparsity pattern of the algorithm over the course of training; in such cases, dynamic sparsity can provide greater flexibility.
To simplify the implementation of dynamic sparsity techniques, a range of utilities are provided that allow for easy manipulation of sparsity patterns on the host before streaming it to the IPU. Users can choose a sparse format that is most suitable for their implementation and then convert it to the IPU’s internal CSR-based sparsity format. This makes it easy to integrate sparsity into existing code and express the pattern manipulations in Python.
Full model implementations of sparse models ranging from RNN architectures to GPT2, as well as static and dynamic sparsity optimization techniques like RigL and sparse attention, are also available open source.
The IPU’s Poplar software libraries provide everything required to implement state-of-the-art algorithms for sparse training. However, in the case of an existing dense model like BERT, it is not immediately obvious what the best algorithmic approach might be.
Traditionally, pruning techniques are a simple and surprisingly effective way to speed up inference of a trained model. Achieving similar computational advantages during training is typically more challenging. One common technique is to start training with a sparse topology and evolve the connectivity patterns over time (Evci et al. 2020, Jayakumar et al. 2020). With this approach, the sparse connectivity is periodically modified by pruning and regrowing the current subnetwork. This means that the available degrees of freedom of the original overparametrized model can be effectively explored while retaining the benefit of reduced computational cost.
Naturally, the effectiveness of such methods is highly dependent on the specific pruning and reallocation criteria. Options range from simple magnitude-based pruning and random re-allocation to more sophisticated gradient-based approaches.
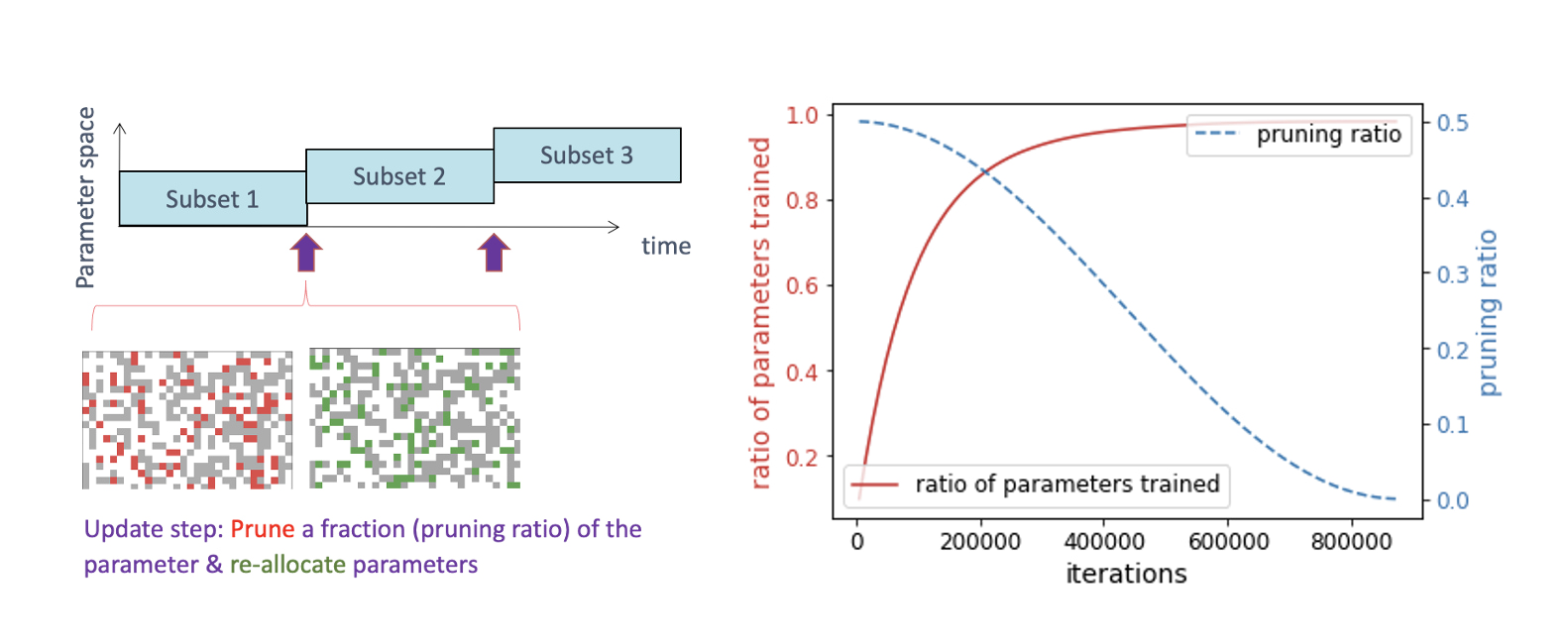
Here, we choose to implement a simple but well-tuned dynamic sparsity baseline using magnitude-based pruning and random regrowing for varying block size 1x1, 4x4, 8x8 and 16x16. Specifically, building on the BERT language modelling task (Devlin et al. 2018), we sparsify the fully connected encoder weights (excluding embedding weights) with a sparsity ratio of 0.9, so that only 10% percent of weights in these layers remain. We regularly update the sparsity pattern (160 times in phase I of pretraining) using magnitude-based pruning and random re-growing of a certain fraction of weights (pruning ratio of 0.5, cosine-decaying over time, see Figure 1).
We then tune the learning rate to yield the best possible task performance. Using this approach, we sparsify varying model sizes up to BERT Base. Figure 2 shows the achieved Masked Language Model loss after phase I, corresponding to the validation performance in predicting a random subset of masked tokens. When compared by the FLOP budget, the dynamically sparse trained models outperform their dense counterpart for all model sizes.
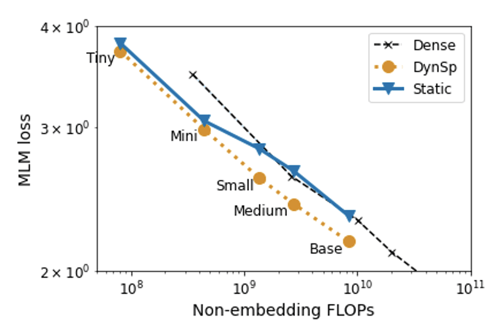
This demonstrates that dynamic sparse training approaches can be an effective technique to reduce the computational burden of large-scale pre-training. Interestingly, the dynamic sparse training approach also remains FLOP-efficient for larger block sizes up to 16x16 (Table 1). The use of larger block sizes provides additional room for optimisations that can be leveraged to make execution even more efficient.
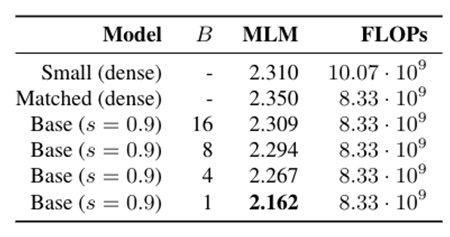
Future work may improve the performance of structured sparsity to identify the best trade-off for compute efficient training of large-scale language models.
In this research, we have established a simple baseline for dynamic, always-sparse training of large-scale language models using novel IPU hardware. For these models, we showed that sparse training can be more efficient than training a dense equivalent, when compared at a given floating point operation (FLOP) budget.
In addition, using larger blocks can partly preserve the FLOP advantage over dense training. In this context, it is worth noting that we only made minimal modifications to the unstructured training method to ensure compatibility with block sparsity. This means that further optimisation and algorithmic innovation could improve the block sparse accuracy that we have achieved here, and help to make sparse training even more efficient.
We believe that this research demonstrates how new hardware and software can both drive and enable the next innovation cycle of sparse network approaches.
If you are interested in collaborating with Graphcore IPUs on a sparsity project, please submit an application to the Graphcore Academic Programme.
Share:


