
Aug 31, 2021 \ Research, Natural Language Processing
Aug 31, 2021 \ Research, Natural Language Processing
共有:
Graphcoreの新しい研究論文では、IPUでの大規模言語モデルの事前学習を例に、スパース学習を効率的に実施する方法が説明されています。
スパースなニューラルネットワークの研究はイノベーションの好循環をもたらします。アルゴリズムの改良により、ソフトウェアライブラリがスパースなパターンを効果的に表現できるようになりました。プログラマーはそのようなライブラリを使用して、利用可能なハードウェアを最大限に活用し、結果として計算の必要条件を減らすことができます。
また同時に、ハードウェアのイノベーションにより、より効率的で柔軟なソフトウェアライブラリの導入が可能になり、研究者はアルゴリズムのイノベーションを探求できるようになりました。
最近では、このイノベーションサイクルがあらゆるレベルで刺激的な進歩をもたらしています。例えば「宝くじ仮説」(FrankleおよびCarbin(2018年)やFrankleおよびその他(2019年)、Ramanujanおよびその他(2019年)、Pensiaおよびその他(2020年))では、学習したモデルの重みの小さなサブセットが、学習した関数を高い精度で表現するのに十分であるというアルゴリズム上のインサイトが強調されています(Hanおよびその他(2015年))。そしてこの考えに基づいて、「宝くじで不正をする」ための新しい学習方法が提唱されています。つまり、全結合の学習のための計算コストをかけずに、高精度のスパースなサブネットワークを見つけることができるのです(Evciおよびその他(2020年)、Jayakumarおよびその他(2020年))。
これと並行して、主要な機械学習フレームワークのソフトウェアサポートをスパース計算向けに拡張する、注目に値する取り組みも行われています。OpenAIはブロックスパースツールボックスをPyTorchに統合することを推奨していますが、これはサポートの向上の一例です。
ハードウェアレベルでも大きなイノベーションが進んでいます。Graphcoreのインテリジェンス処理ユニット(IPU)のように、スパース計算をサポートするために特別に設計された新しいアクセラレータが、産業界や学術界のイノベーターに広く利用されるようになっているのです。
最近のAIモデルのサイズが爆発的に増加していることを考えると、このような動きはどれも時宜にかなったものです。現在広く使われているGPT3のような大規模なトランスフォーマーベースの言語モデルは、最先端のアーキテクチャでモデルサイズがますます大きくなっていることを示す好例です。このようにモデルを大きくすることで、一貫して精度を向上させることができますが、学習や推論にかかる計算量は非常に多くなります。このような状況において、スパースな手法の改良はコストとエネルギー消費を制限する大きな可能性を秘めており、モデルをより広く利用できるようにすると同時に、高い電力消費による環境問題を軽減する効果も期待できます。
SNN Workshop 2021で当社が発表したケーススタディでは、IPUプロセッサ上でスケーラブルな言語モデルの事前学習を行うという具体的な例を用いて、スパース計算の可能性を探っています。具体的には、BERT言語モデルの強力なスパース事前学習ベースラインを実装し、浮動小数点演算(FLOP)ベースで比較した場合に全結合モデルよりも優れていることを実証しました。今回のケーススタディでは、ハードウェア、ソフトウェア、アルゴリズムのさまざまな側面を探求するだけでなく、今回得られた知見がこの分野のさらなる研究のための実用的な出発点となることを期待しています。
ここでは、当社のワークショップへの寄稿で得られた重要な知見を紹介します。まず、IPUの概要と、スパース計算に適した機能を紹介します。次に、スパースアルゴリズムの実装に使用しているオープンソースのソフトウェアライブラリを紹介します。そして最後に、効率的な実行を可能にするアルゴリズムの特性を浮き彫りにする実験結果について説明します。
GraphcoreのIPUは機械学習のワークロードのために特別に設計された、今までにない超並列プロセッサです。第2世代のチップは、完全に独立した1472個のプロセッサコア(タイルと呼ばれる)を持ち、それぞれが6つのスレッドを持つことで、8832個の独立した同時命令を一度に実行できます(複数命令/複数データ方式(MIMD)と呼ばれます)。ここで注目すべきは、各タイルが独立したプロセッサ内メモリの塊を持ち、カードごとに180TB/sでアクセスできることです。これはオフチップDRAMの100倍以上のメモリアクセス帯域幅です。計算とメモリをIPUにコロケーションすることで、エネルギー効率が向上するだけでなく、きめ細かく柔軟なアプローチを使って並列化しなければならないとても不規則な計算にも非常に適しています。
IPUは大規模な並列処理に特化して設計されているので、スパースなワークロードに特に適しています。 ネットワークトポロジーをアルゴリズムでスパース化すると、粒度の細かいとても不規則な計算グラフになることが多いため、最小の計算構造であっても効率的に並列化できるIPUの能力はメリットです。
スパース構造の粒度が高い場合でも、IPUのアーキテクチャはスパースな学習と推論の計算効率を維持できます。サイズ16の積和演算ユニットにより、1x1や4x4、8´8、16´16といったとても小さなブロックサイズでも、IPUは良好なスレッド使用率とパフォーマンスを達成できます。さらにIPUは、一般的な昔ながらのスパース計算を高速化するために設計された数多くの命令をサポートしているので、スループットの向上にも貢献します。
ハードウェアとアーキテクチャの特徴はすべて、スパース計算のための柔軟な低レベルC++ライブラリであるPopsparseで利用可能な、最適化されたカーネルを介してターゲットにすることができます。Popsparseは、Graphcoreがオープンソースで提供しているソフトウェアライブラリ(PopLibsとして知られている)の1つで、Graphcoreのグラフ構築およびコンパイルAPIであるPoplarの上に構築されており、IPU上で動作するあらゆるものを支えています。
スパース性カーネルは、PopART APIを介して直接ターゲットにすることも、この取り組みで使用されているTensorFlowとKerasのレイヤーを介して既存のTensorFlowモデルに簡単に統合することもできます。FP16とFP32の両方でブロックサイズ1x1、4x4、8x8、16x16のスパース性をサポートしています。Graphcoreはオープンソースの実装とチュートリアルをGitHubの公開サンプルで提供しています。
Poplarソフトウェアスタックは、アルゴリズムのスパース性パターンが固定されているか、または時間とともに変化するかに応じて、静的スパース性と動的スパース性の両方をサポートしています。静的スパースを使用することでコンパイル時の最適化が進んで、実行効率が向上するので、すでに学習済みのモデルを含む推論ワークロードにとても適しています。しかし、多くの学習アルゴリズムでは、学習の過程でアルゴリズムのスパース性パターンがゆっくりと進化していきます。このような場合は動的スパース性を用いることで、より高い柔軟性が生まれます。
動的スパース性の技術の実装を容易にするために、IPUにストリーミングする前にホスト上でスパースパターンを簡単に操作できる、さまざまなユーティリティが用意されています。ユーザーは、自分の実装に最適なスパースフォーマットを選択し、それをIPU内部のCSRベースのスパースフォーマットに変換できます。これによって、既存のコードにスパース性を組み込んで、パターン操作をPythonで表すことが容易になります。
また、RNNアーキテクチャからGPT2までのスパースモデルのフルモデル実装や、RigLやスパースAttentionなどの静的スパース性および動的スパース性の最適化技術もオープンソースで公開されています。
IPUのPoplarソフトウェアライブラリには、スパース学習のための最先端のアルゴリズムを実装するために必要なすべてが揃っています。しかしBERTのような既存の全結合モデルの場合、最適なアルゴリズムのアプローチが何であるかはすぐにはわかりません。
従来、学習したモデルの推論を高速化するために、シンプルかつ驚くほど効果的な方法としてプルーニング技術が用いられてきました。通常、学習中に同様の計算上の利点を得ることはより困難になります。一般的な手法としては、スパースなトポロジーで学習を開始し、時間の経過とともに接続パターンを進化させていく方法があります(Evciおよびその他(2020年)、Jayakumarおよびその他(2020年))。このアプローチでは、現在のサブネットワークをプルーニングしたり再成長させたりすることで、スパース接続性を定期的に修正します。つまりこれは、計算コストの削減というメリットを残しながら、元の過剰パラメータモデルの利用可能な自由度を効果的に探索できるということです。
当然のことながら、このような手法の有効性は特定のプルーニングやリアロケーションの基準に大きく依存します。選択肢は、単純な大きさベースのプルーニングやランダムなリアロケーションから、より洗練された勾配ベースのアプローチまで多岐にわたります。
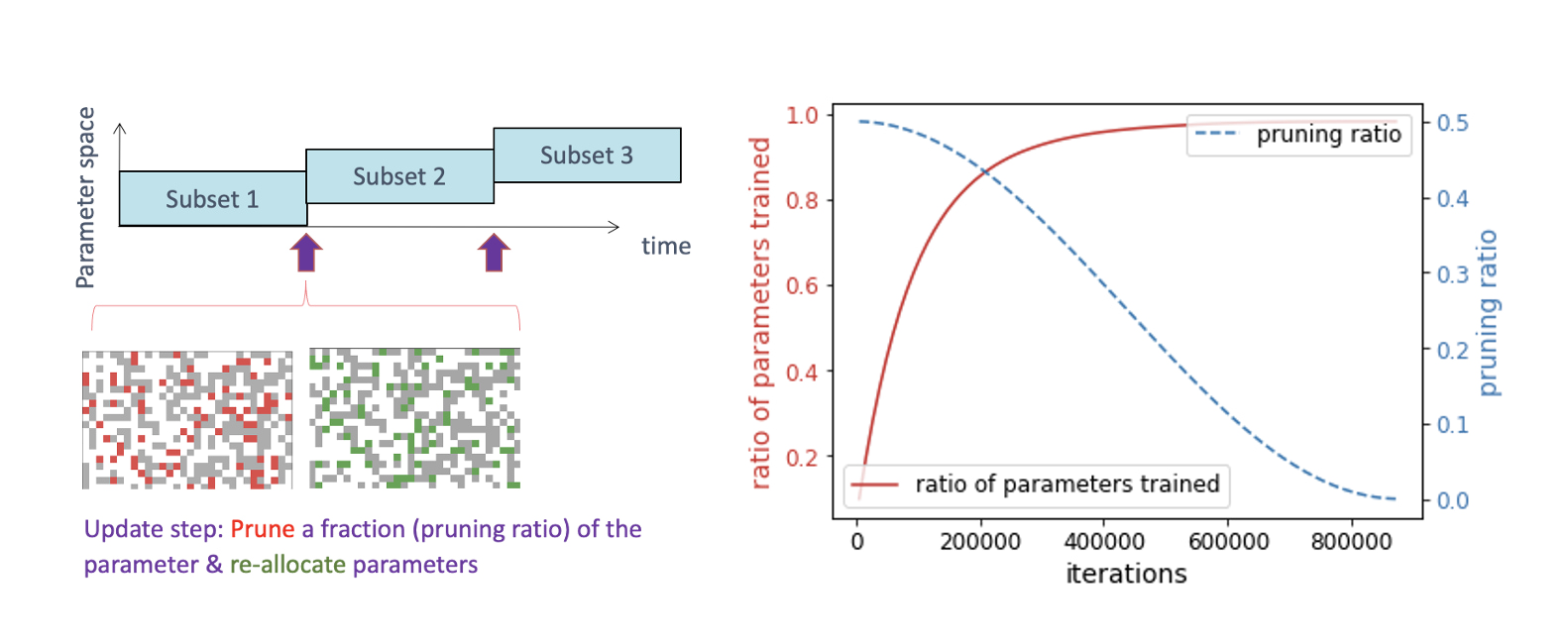
ここではブロックサイズを1x1、4x4、8x8、16x16と変化させながら、大きさベースのプルーニングとランダムな再成長を用いて、シンプルであるが十分に調整された動的スパース性のベースラインを実装することにしました。具体的には、BERT言語モデリングタスク(Devlinおよびその他(2018年))をベースに、完全に連結されたエンコーダの重み(埋め込みの重みを除く)をスパース性比率0.9でスパース化し、これらのレイヤーの重みの10%だけが残るようにします。スパース性のパターンは定期的に更新します(フェーズIの事前学習では160回)。その際、大きさベースのプルーニングと、一定割合の重みのランダムな再成長を行います(プルーニング比率は0.5で、時間の経過とともにコサイン減衰する。図1を参照)。
その後、最適なタスクパフォーマンスを得るために学習率を調整します。このアプローチを用いて、BERT Baseまでさまざまなサイズのモデルをスパース化します。図2に示すのは、フェーズIの後に達成された、マスクされた言語モデルの損失で、これはマスクされたトークンのランダムなサブセットを予測する際の検証パフォーマンスに相当します。FLOPバジェットで比較すると、すべてのモデルサイズにおいて動的スパース学習したモデルが全結合モデルよりも優れています。
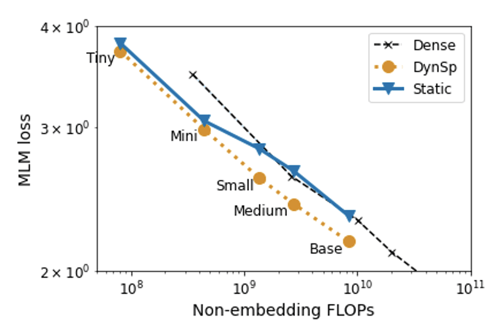
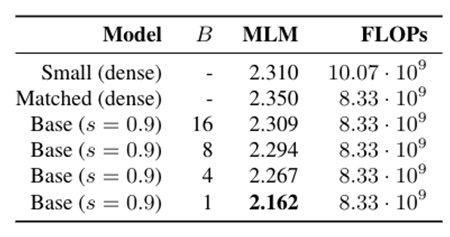
このことから、動的スパース学習のアプローチは、大規模な事前学習の計算負荷を軽減するための有効な手法であることがわかります。興味深いことに、動的スパース学習のアプローチは16x16までの大きなブロックサイズでもFLOP効率を維持しています(表1)。より大きなブロックサイズを使用することで、実行をより効率的にするために活用できる最適化の余地が増えます。
今後は、構造化スパース性のパフォーマンスを向上させ、大規模な言語モデルを効率的に学習するための最適なトレードオフを明らかにしていく予定です。
この研究では斬新なIPUハードウェアを使って、大規模な言語モデルを動的に常時スパース学習するためのシンプルなベースラインを確立しました。これらのモデルについて私たちは、所定の浮動小数点演算(FLOP)バジェットで比較した場合、スパース学習は同等の全結合の学習よりも効率的であることを示しました。
さらに、より大きなブロックを使用することで、全結合の学習に対するFLOPの優位性を部分的に維持できます。これに関連して、ブロックスパース性との互換性を確保するために、構造化されていない学習方法には最小限の変更しか加えていませんが、この点は注目に値します。 これは、さらなる最適化とアルゴリズムのイノベーションにより、今回私たちが達成したブロックスパースの精度を向上させ、スパース学習をさらに効率的に行うことができることを意味しています。
私たちはこの研究について、新しいハードウェアとソフトウェアによってスパースなネットワークのアプローチの次のイノベーションサイクルがいかに後押しされ、可能になるかを示すものだと信じています。
スパース性のプロジェクトでGraphcoreのIPUとの共同研究にご興味のある方は、Graphcore Academic Programme(Graphcoreアカデミックプログラム)にご応募ください。
共有:


