
Apr 05, 2023
Apr 05, 2023
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamAre you working with Graph Neural Networks (GNNs) and looking for a way to accelerate your models? You've come to the right place!
In this blog post, we are excited to announce support for PyTorch Geometric (PyG) on Graphcore IPUs. We will guide you through the process of understanding whether your problem aligns with GNNs and IPUs, and how to start leveraging this powerful combination.
Note: This blog post assumes familiarity with PyG and the basics of GNNs. If you're new to these topics, we recommend starting with an introductory blog about GNNs and PyTorch Geometric's official documentation or tutorials.
We have been working hard to make PyTorch Geometric as seamless as possible on Graphcore IPUs. Our latest Poplar SDK 3.2 release includes extensions to PyG - called PopTorch Geometric - which allow you to run PyG on IPUs.
This means that your models will make use of efficient gather and scatter operations from the Poplar SDK, operations frequently used in GNNs, such as in PyG’s message passing layers.
Our current software stack relies on full model compilation, in contrast to eager execution where the model is chunked into small kernels, executed sequentially, which you might be familiar with from other accelerators. Pre-compiling allows us to apply optimisations, such as automatically fusing or parallelising operations, which aren't possible while deploying kernel-by-kernel.
With this release we have provided data loaders and transforms to make it simple to enable your PyG model to be statically compiled, allowing you to easily obtain the optimisations gained from full model compilation.
Finally, we have verified the functionality of many PyG layers on the IPU, and are continuing to increase our coverage. This integration with the Poplar SDK also unlocks a number of other great features, including easily scaling your models with pipelining and replication.
The PopTorch Geometric library is currently experimental, and we will continue adding more features from upstream PyG over time.
.png?width=1200&height=453&name=PopTorch_geometric%20(1).png)
Using PyG with the Poplar SDK is now easier than ever, thanks to Paperspace Gradient.
Paperspace offers a notebook-based interface in a PyG + Poplar SDK environment. This user-friendly environment allows developers and researchers to harness the power of IPUs without upfront investment in hardware.
With its pay-as-you-go model and a free tier for new users, Paperspace Gradient is an attractive option for those looking to experiment with the capabilities of IPUs for their GNN workloads.
To help you get started we have included a range of tutorials and examples in the runtime, which we will discuss in this blog.
.png?width=3360&height=1944&name=Screenshot%202023-03-31%20at%2012.59.33%20(1).png)
We encourage you to explore the PyG runtime for IPUs on Paperspace Gradient. You can also check out our blog - Getting started with PyTorch Geometric (PyG) on Graphcore IPUs - for a code walkthrough example.
Try PyG on IPUs for free
![]()
The unique architecture of IPUs (MIMD) plays a significant role in their ability to excel at GNNs. With large core counts (1,472 per processor), distinct program execution, distributed in-processor memory, and efficient execution of applications with irregular data access patterns and control flow, IPUs outperform CPUs (SISD) and GPUs (SIMD) in graph learning tasks.
.png?width=989&height=343&name=Presentation38%20(1).png)
CPUs, which excel at single-thread performance and control-dominated code, are limited by their complex cores in small counts, deep memory hierarchy, and latency-reducing techniques.
On the other hand, GPUs boast smaller cores in high count per device and simpler architecture, but their SIMD execution model and focus on regular, dense, numerical, data-flow-dominated workloads makes them less effective for GNNs.
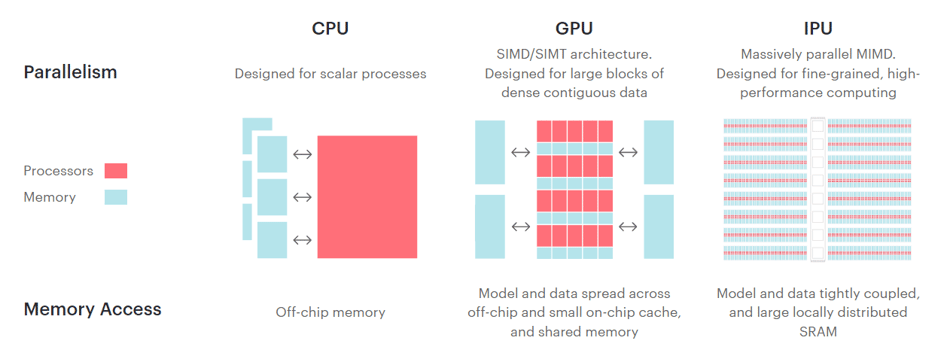
IPUs are particularly efficient at handling gather and scatter operations, which are commonly used in graph learning. These operations are crucial for message passing, a key feature of GNNs, where node features are passed to and aggregated in the neighbouring nodes through non-linear transformations.
Arithmetic intensity is a metric used to characterize the computational efficiency of an algorithm or a computation workload. It is defined as the ratio of the total number of floating-point operations (FLOPs) performed to the total amount of data transferred between memory and the processing unit (usually measured in bytes).
Put simply, arithmetic intensity measures how many calculations are performed per byte of data moved.
Low arithmetic intensity means that a small number of operations are performed for each byte of data transferred, which indicates that the computation is more memory-bound or bandwidth-bound. In such cases, the performance of the algorithm is limited by the memory access speed and the available memory bandwidth.
Improving the processing power might not lead to substantial performance gains, as the algorithm would still be bottlenecked by the memory subsystem.
Many graph machine learning tasks are characterised by low arithmetic intensity.
The combination of a large amount of on-chip SRAM and a fast interconnect system makes the IPU well-suited for handling memory-bound workloads.
To demonstrate this we have benchmarked a range of different sized gather and scatter operations on the IPU, which as discussed above, gives us a good understanding of message passing performance.
We observe statistically significant speedups towards the lower range of tensor sizes, while the GPU approaches the IPU's performance as sizes increase. It is important to note that in the case of sparse access (i.e. small scatter input sizes) the IPU achieves over 16 times the performance of leading GPUs under the same conditions.
It is worth emphasizing that, in many cases, running graph-based workloads on IPUs isn’t only faster, but the cost of renting Graphcore’s hardware in the cloud is also significantly lower. As of Q1 2023, pricing on the cloud platform Paperspace is $3.18/hr (A100-80GB) vs. $1.67/hr (per Bow-IPU).
You can see the full results and run the benchmarks for yourself on Paperspace.
The figures below highlight the advantage offered by the Graphcore Bow IPU compared to an NVIDIA A100 (1x, blue plane). The top row regards scatter_add, and the bottom row gather operations of different sizes. The left columns show the entire performance data we have collected previously which includes a range of feature sizes for each input-output pair as a scatter plot, while the figures on the right show the average speedups across all feature sizes.
.png?width=952&height=442&name=Graph%201%20(1).png)
scatter_add operations
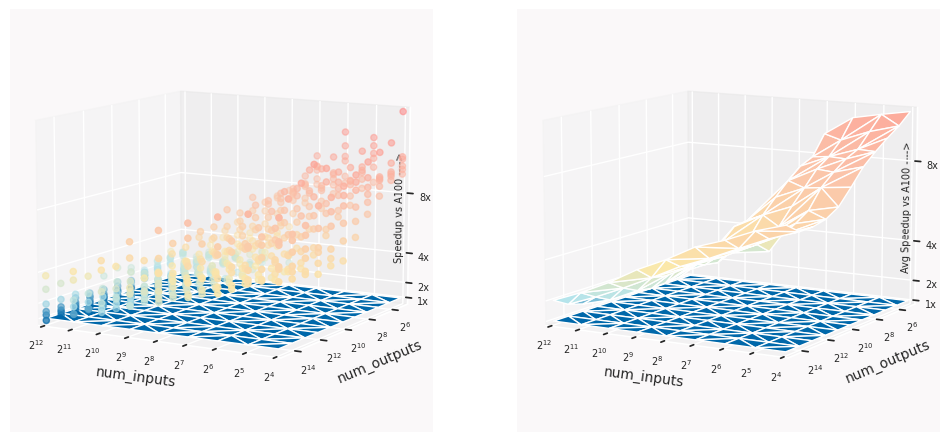
gather operations
Let’s consider the following classification of graph learning tasks from the perspective of supported features and performance on IPU: graph prediction, node prediction and link prediction.
Graph-level prediction is where you attempt to predict attributes of individual graphs. You would usually find this sort of problem when your dataset is a collection of small graphs.
So how is the IPU useful for graph-level prediction tasks?
Problems involving small graph sizes are easy to scale by distributing the workload across multiple devices with pipelining. In those cases, the execution scheme is often a mixture of many small matmuls interleved with memory copies, operations that perform exceptionally well on IPUs.
On top of this, the set of tools provided in PopTorch Geometric makes it easy to batch and load small graphs, producing fixed size batches, ready for the IPU, by using padding or packing.
Packing involves making the most of any wasted space in a fixed sized batch by packing graphs into any space that would otherwise be padding, making the batches and thus the compute more efficient.
Check out our tutorials on these batching approaches Tutorial Notebook : Small graph batching on IPUs using padding and Tutorial Notebook: Small graph batching on IPUs using packing.
We also offer a number of GNN examples for you to run on Paperspace.
One such model is SchNet, which was used on IPUs by the US Department of Energy's PNNL National Lab for molecular property prediction, delivering drastically reduced training times and improved cost efficiency. The SchNet example below also demonstrates how to use replication to scale your PyG model across IPUs.
You can also try predicting molecular properties with a GIN network, which uses packing to get the most out of your batches of small molecular graphs.
Check out both GNN examples below:
For further evidence of success at graph-level prediction tasks on the IPU, see also Graphcore's double win in the Open Graph Benchmark challenge.
Link prediction tackles problems that involve predicting whether a connection is missing or will exist in the future between nodes in a graph. Important examples for link prediction tasks include the prediction of connections in social networks, knowledge graphs, or recommendation systems, usually operating on a single larger graph. We consider both static and dynamic cases, where either the graph structure or the node and edge features change in time.
How can you use the IPU for these tasks?
Like other applications of message passing neural networks, link prediction tasks are often characterised by a low arithmetic intensity and the need for high memory bandwidth, making the IPU a great fit.
The integration of PyTorch Geometric with PopTorch makes it easier to leverage IPUs for these tasks.
What are temporal graphs?
Most graph neural network (GNN) designs presume static graphs, but this assumption may not hold in many real-world scenarios where the underlying systems are dynamic, leading to graphs that evolve over time.
This is especially true in applications like social networks or recommendation systems, where user interactions with content can rapidly change.
As a response to this challenge, researchers have proposed several GNN architectures that can handle dynamic graphs, such as Temporal Graph Networks (TGNs) which act on evolving graph structures and Spatio-Temporal Graph Convolutional Networks that deal with dynamically changing traffic data.
In applications that act on dynamically changing graphs, a dependency of the model accuracy and the batch size used for training and inference can often be observed: the larger the batch, the more short-term context is missing from the predictive window of the model, leading to a degraded predictive power.
When the batch size is small, most hardware platforms suffer from underutilised computation units, whereas IPUs are affected significantly less, which makes them a great match for TGNs.
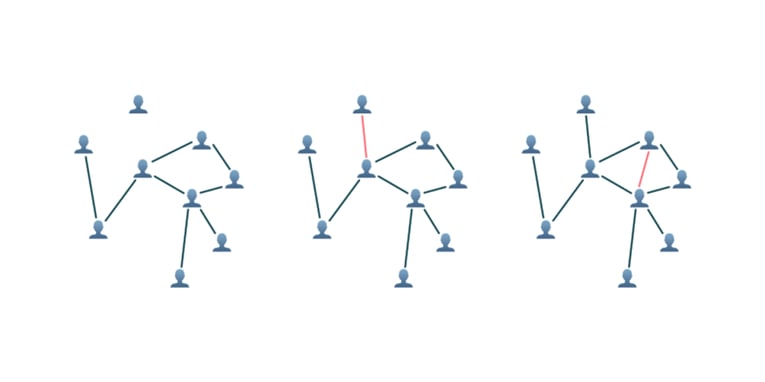
Social networks with dynamically evolving connectivity can efficiently be modelled by TGN
You can now run TGN training as a Paperspace Gradient Notebook.
Training dynamic graphs on IPU using Temporal Graph Networks
![]()
To gain further insight into the application of temporal graphs on IPUs, you can refer to our blog Accelerating and scaling Temporal Graph Networks.
Also, find out how the National University of Singapore used IPUs in: Improving journey time predictions with Spatio-Temporal GCN.
Other methods for graph completion
Neural Bellman-Ford Networks (NBFNet) present a versatile graph neural network framework for link prediction, combining the benefits of traditional path-based methods and modern graph neural networks. This approach facilitates generalization in inductive settings and interpretability. NBFNet is applicable to link prediction tasks in both homogeneous graphs and knowledge graphs.
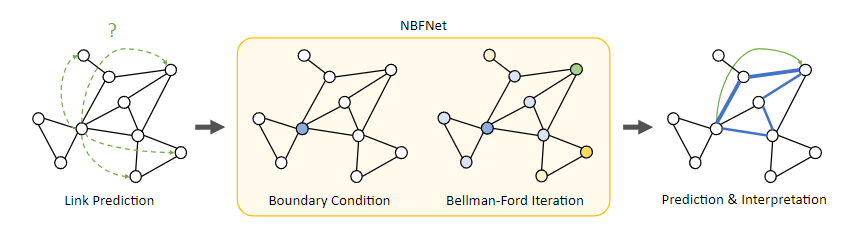
This model is now available to run as a Paperspace Gradient Notebook.
Training NBFnet for inductive knowledge graph link prediction on IPUs
![]()
Node-level prediction involves predicting the properties of a particular node or set of nodes in a network. In many cases these tasks involve large graphs and so often require sampling techniques in order to train.
So why use IPUs for node-level tasks?
Clustering is a suitable sampling approach to consider when training large graphs for node classification on IPUs. Clustering involves cutting your large graph into a number of sub-graphs, then when training your model (such as Cluster-GCN) the sub-graphs are recombined and the original edges connecting the sub-graphs are re-established.
This approach is very suited to IPUs, as the combined clusters can be chosen to fit into IPU SRAM, making the most of the performance benefits mentioned above, sitting in the low arithmetic intensity regime.
Now sampling clusters with static sizes suitable for the IPU is easy with the new tools PopTorch Geometric provides. This sampling approach scales well, as the model can be replicated across IPUs, each sampling a different set of clusters. This functionality is made easily available with PopTorch, only requiring a few code changes to scale your model in this way.
Try our example of node classification with cluster sampling now on Paperspace.
Node Classification on IPU using Cluster-GCN - Training with PyTorch Geometric
![]()
IPUs offer powerful acceleration for a wide range of graph learning tasks when used with PyTorch Geometric and the Poplar SDK.
Get started today for free by exploring our tutorials and examples on Paperspace and unleash the potential of GNNs in your applications. Our journey in demonstrating PyTorch Geometric on Graphcore IPUs has just begun, and we plan to continue expanding our support and examples.
If you find anything missing or have suggestions for improvement, please join our Graphcore community Slack channel. We look forward to seeing what you create!
Share:


